Lowering the Barrier to Data Science: Doubao's AutoKaggle Open-Sourced for End-to-End Data Processing
Lowering the Barrier to Data Science: Doubao's AutoKaggle Open-Sourced for End-to-End Data Processing
Date
2024-11-27
Category
Tech
As a classic competition in data science and machine learning, Kaggle attracts a vast number of top talents with its high level of difficulty, substantial prize money, and extensive attention. Kaggle competition tasks often involve requirements understanding, data cleaning and preprocessing, feature engineering, and modeling, and require participants to possess strong domain expertise and collaborative abilities.
ByteDance's Doubao Large Language Model team and the M-A-P community recently proposed AutoKaggle, providing data scientists with an end-to-end data processing solution that streamlines and optimizes daily data science workflows while significantly lowering the barriers to entry, enabling more users without specialized backgrounds to perform valuable explorations. In relevant evaluations, AutoKaggle's performance surpassed the average human level.
Currently, this achievement has been open-sourced, and this article will present its origins, technical highlights, and key findings from the experiments.
Large Language Models (LLMs) have demonstrated remarkable capabilities in recent years. However, despite LLMs' excellent performance on individual tasks, they still face significant limitations when confronted with complex, multi-step project processing.
Take data analysis projects as an example. These tasks typically involve requirements understanding, data cleaning and preprocessing, exploratory data analysis, feature engineering, and modeling. Each step necessitates domain expertise and meticulous planning, often requiring multiple iterations, resulting in a very high barrier to entry.
Given this context, the Doubao LLM team and the M-A-P community jointly proposed AutoKaggle, an end-to-end data processing solution.
AutoKaggle constructs a multi-agent workflow to enhance the explainability and transparency of intermediate decision-making steps in logically complex data science tasks, while maintaining excellent performance and ease of use, reducing the difficulty of understanding and the barrier to adoption. The team believes that AutoKaggle can systematically address the intricate problems of data science tasks, ensuring robust and correctly generated code.
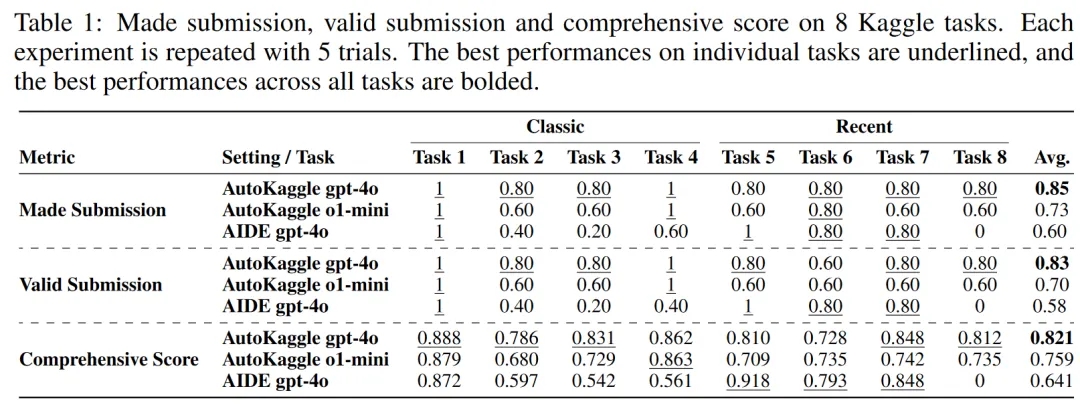
Experimental results show that in the evaluation of 8 Kaggle competition datasets, AutoKaggle achieved an 85% valid submission rate and a comprehensive score of 0.82 (out of 1), outperforming the AIDE framework , which excelled in MLE-Bench, demonstrating its efficiency and broad adaptability in complex data science tasks, with performance surpassing the average human level!
The research findings have now been open-sourced, and the team has provided a detailed report on AutoKaggle's execution results, enabling everyone to examine the details for further exploration.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
论文链接:https://arxiv.org/abs/2410.20424
代码链接:https://github.com/multimodal-art-projection/AutoKaggle

How challenging is it to become a "Kaggle Grandmaster"?
Before introducing our work, let's briefly discuss Kaggle and the complexity of its projects.
Kaggle is a popular data science competition platform in the industry, where companies and researchers can post data and problems, offering prizes to contestants who solve them. Each Kaggle competition problem is an extremely complex knowledge maze with no standard answer, only an infinite approach to the optimal solution, prompting contestants to continuously propose better solutions and explore the boundaries of technology.

Kaggle Days held in China Source: Kaggle Official
Taking medical image diagnosis as an example, contestants must not only be proficient in using algorithms but also possess a deep understanding of medical expertise to capture key features in extremely tiny pixel details that are easily overlooked by the naked eye.
Financial risk prediction is even more uncertain, requiring contestants to build models that can penetrate the complex fluctuations of the market and extract valuable signals from massive and noisy time-series data.
Taking this complexity to the extreme is climate change prediction, where contestants need to integrate global multi-source data, simulate the intricate interactions of the Earth system, and make accurate predictions with limited computing resources.
These problems not only test technical skills but also place extremely high demands on collaborative abilities and domain knowledge. Usually, the number of participants in a project can reach thousands, and only the Top 1 can receive a substantial prize. Even if multiple experts team up for collaborative development, they can only provide a not-so-bad solution. To go further, a certain degree of tacit understanding and cooperation experience is required.
High difficulty means both high prize money and prestige. Previously, Hinton and his students demonstrated the powerful capabilities of deep neural networks in a competition, which became a landmark event in the industry. Many talented individuals with strong machine learning skills are also recognized as "Kaggle Grandmasters".
Stage-based Multi-Agent Reasoning, Combined with Two Critical Modules
As mentioned earlier, most Kaggle competition tasks often involve requirements understanding, data cleaning and preprocessing, exploratory data analysis, feature engineering, and modeling. Each step requires domain expertise and meticulous planning, going through multiple iterations, and the barrier to entry is very high.
Therefore, the problems that need to be addressed include: abstraction of the entire task and multi-agent collaboration, iterative debugging and unit testing, the utilization of complex machine learning knowledge, and comprehensive reporting.
With the above challenges in mind, the team carried out the following work:
- Architecture Design
The core of AutoKaggle is phase-based multi-agent reasoning , which transforms complex data science problems into a generalizable workflow by abstracting the competition tasks. This task is accomplished by two sets of components: a multi-phase workflow and multiple agents.
We divide the data science problem-solving process into six key phases: background understanding, preliminary exploratory data analysis (EDA), data cleaning, in-depth EDA, feature engineering, and modelling, validation, and prediction. The structured design provides a clear problem-solving path, ensuring that all aspects are handled systematically and comprehensively.
After defining the problems to be solved in each phase, corresponding agents need to be designed to complete the tasks of different phases. They are Reader, Planner, Developer, Reviewer, and Summarizer. These agents play the roles of collaboratively analyzing problems, formulating strategies, implementing solutions, reviewing results, and generating comprehensive reports in the workflow.
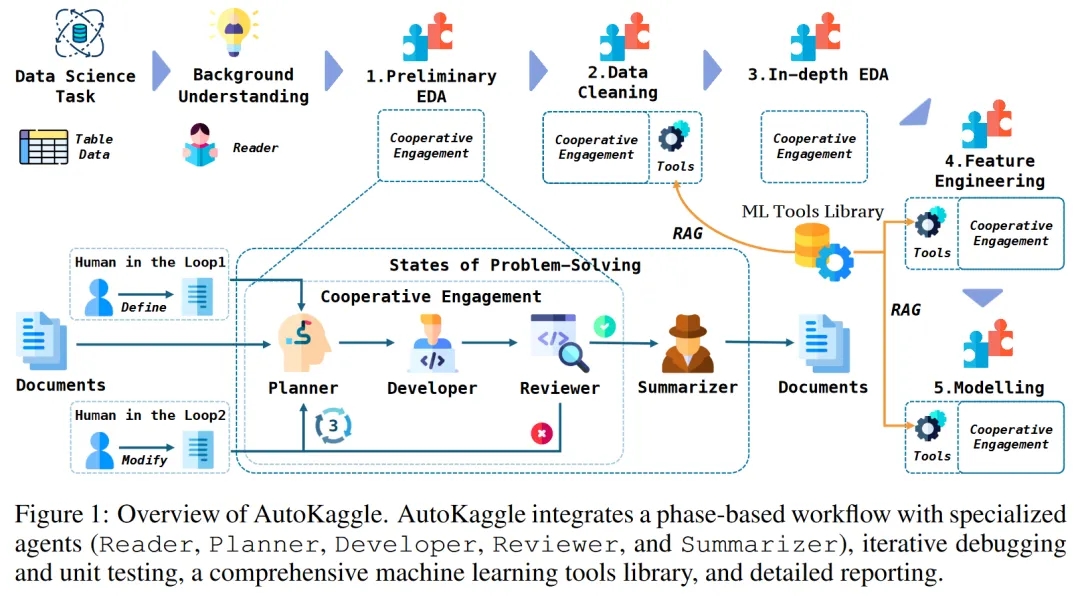
The multi-agent collaboration approach not only improves task completion efficiency but also enhances system flexibility and adaptability, enabling AutoKaggle to cope with various complex data science challenges.
- Critical Modules: The Developer Module
Within the architecture, the Developer module is more complex and deserves further analysis.
The team built an adaptive and robust data science code generation system through iterative development and testing. The Developer generates initial code based on the current state, the strategies provided by the Planner, and the context. Afterward, the Developer enters an iterative debugging and testing process:
1)Run the generated code. If there are errors, feed them into the debugging tool.
2)The code debugging tool modifies the code based on the source code and error information.
3)Unit test the generated code. Through multiple code executions, intelligent debugging, and comprehensive unit testing, precise control over the complex development process is achieved.
In Kaggle competitions, simply ensuring error-free code execution is far from sufficient. Competition problems involve complex data processing and sophisticated algorithms, where hidden subtle logical errors often have a decisive impact on the final results.
Therefore, unit testing not only needs to verify the formal correctness of the code but also needs to examine in depth whether it fully complies with the expected logic and performance standards . If this is ignored, minor errors will accumulate at each phase, potentially leading to systematic biases in the entire analysis.
To reduce this potential risk, extremely meticulous unit test design must be carried out for each development phase , fully covering both regular scenarios and edge cases.
The core advantages of this method are: dynamically capturing potential errors, correcting code logic in real-time, preventing error propagation, and ensuring code correctness and consistency with minimal manual intervention. Thanks to the introduction of self-repair and continuous optimization mechanisms, there has been a significant improvement in code generation.
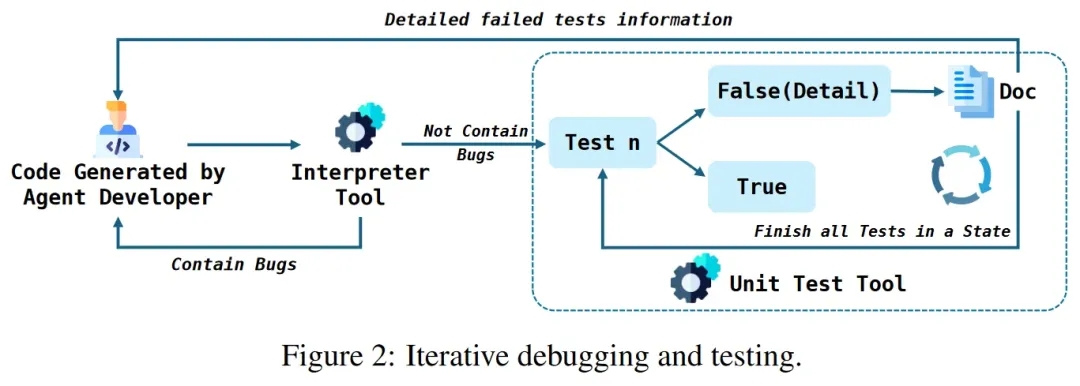
- Critical Modules: The Machine Learning Tool Library
AutoKaggle's machine learning toolkit is another core innovation of its architecture. Three meticulously designed toolsets: data cleaning, feature engineering, and model building and validation , collectively provide a comprehensive and standardized solution.
This library not only compensates for the inherent limitations of LLMs in domain expertise but also automates and intelligentizes the data processing pipeline through seven data cleaning tools, eleven feature engineering tools, and comprehensive model development tools.
Its advanced features include: standardized functional modules, a comprehensive exception handling mechanism, precise adaptation to complex Kaggle competition scenarios, and a significant reduction in technical implementation complexity , enabling the multi-agent system to focus on higher-level strategic task planning. The standardization of each tool's functionality allows for seamless data sharing and processing across the project, enhancing feature quality, optimizing model performance, and ultimately improving the efficiency of the overall workflow.
- High Scalability, Comprehensive Reporting, User-Friendly Framework
Beyond its technical advantages, AutoKaggle prioritizes user experience, making it a truly scalable and **user-friendly **framework. It also ensures transparency in the data processing pipeline, increasing user trust in the AutoKaggle solution.
Regarding customizability, AutoKaggle recognizes that each user's scenario is unique. By providing customizable interfaces, users can tailor the entire data processing pipeline through simple modifications to configuration file parameters.
Furthermore, AutoKaggle's machine learning toolkit is designed with extensibility in mind. Users can expand the existing tools to meet diverse needs by simply deploying a function along with its accompanying documentation in Markdown and JSON formats.
Finally, to enhance the interpretability of the AutoKaggle solution and ensure full transparency of the entire data processing pipeline, AutoKaggle provides detailed reports at each phase, culminating in a competition summary.
These detailed phase-wise reports allow users to not only track AutoKaggle's progress in real-time but also to gain a deeper understanding of the analytical logic at each phase, thereby strengthening their confidence in the framework.
For details, please see https://github.com/multimodal-art-projection/AutoKaggle.
AutoKaggle Demonstrates Superior Performance in Most Metrics
We divided the 8 tasks into two groups: Classic and Recent. Considering that the project relies on GPT-4o, which was trained on data available before October 2023, it likely includes data from most classic Kaggle competitions.
For a fairer evaluation of the workflow, we selected competitions that started before October 2023 and had at least 500 participants for the Classic group, while the Recent group comprised competitions from 2024 onwards.
We compared the performance of AutoKaggle and AIDE across different dimensions, including completing submission, valid submission, and comprehensive score. AutoKaggle demonstrated superior performance in most metrics.
To further explore the factors that contribute to its performance, we compared the completion rate and comprehensive score across four scenarios: no tools used, only data cleaning tools used, data cleaning and feature engineering tools used , and all tools used .
Compared to using no tools, using only data cleaning tools resulted in the highest completion rate, a 30% improvement, while using all tools yielded a 27% improvement. The completion rate showed a decreasing trend after incorporating feature engineering. This decline might be attributed to the relatively large number of features involved, coupled with the complexity and high encapsulation of the tools in this phase, requiring the addition and deletion of features, thus increasing complexity.
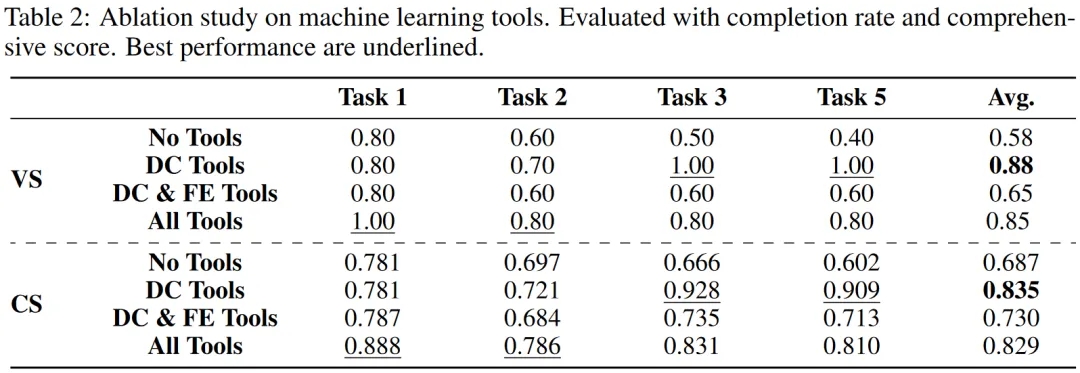
The bottom left figure shows that the debugging time is significantly higher when feature engineering tools are used than when data cleaning tools alone are used. This complexity makes it more challenging for Developers to debug erroneous code and could be a reason for the performance degradation.
The bottom right figure illustrates the impact of different scenarios on performance. Although the machine learning toolkit did not significantly raise the upper limit of the solution, it served as a more stable tool, improving AutoKaggle's completion rate.
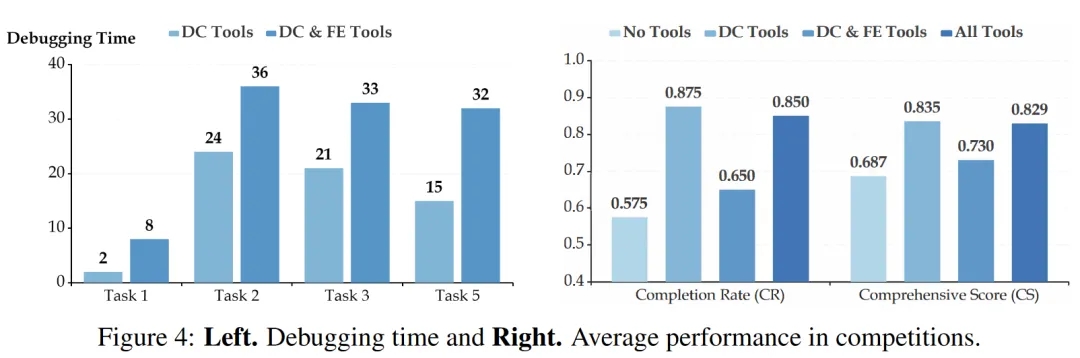
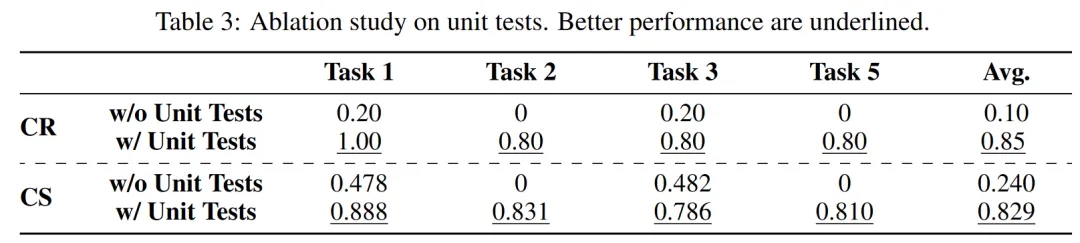
Without unit testing, the completion rate dropped significantly, making task completion nearly impossible.
This implies that for tasks requiring high precision and logical rigor, such as data science, simply ensuring that the code is executable and error-free at each phase is insufficient. Comprehensive unit testing is necessary to ensure correct code logic and achieve the objectives of each phase.
Finally, we analyzed the types and frequencies of different errors. Errors can occur at each sub-task phase. Data cleaning and feature engineering had the highest error rates, at 25% and 22.5%, respectively. Notably, errors during the feature engineering phase led to 31.25% of task failures.

However, the team provides Developers with a detailed debugging process. Taking the "file not found" error as an example, the debugging workflow is as follows:
1)Error Localization : The Developer initially encounters a problem when executing the script, related to file saving operations.
2 )Error Fixing : Several modification suggestions are proposed to address these issues.
3 )Code Fragment Merging : The corrected fragments are merged back into the original code to create a seamless and robust solution.
Reflections
AutoKaggle provides a robust framework for data science exploration. Extensive evaluation based on various Kaggle competition problems has demonstrated its effectiveness. This achievement not only showcases the enhancement of model capabilities through multi-agent systems but also proves that sufficiently complex problems can be solved by abstracting the workflow, offering more possibilities for LLM applications. Admittedly, there are some limitations, such as the inability to validate AutoKaggle's performance on competitions with particularly large datasets.
In the future, the team will continue to explore intelligent data science topics and related open-source work, focusing on the latest cutting-edge technologies on Kaggle. If you are interested in agent collaboration, data science, and applying LLMs to complex problems, and are eager to explore frontier research topics, please visit our careers page for more information about open positions.