Seed-Music 音乐大模型正式发布!生成编辑两开花,十种创作任务,满足多样化需求
Seed-Music 音乐大模型正式发布!生成编辑两开花,十种创作任务,满足多样化需求
Date
2024-09-18
Category
Tech
当 AI 与音乐这一充满魅力的艺术形式相遇,精彩就此开启。字节跳动豆包大模型团队全新推出了 Seed-Music,助力人们在音乐创作领域探索更多可能性。
Seed-Music 是一个具备灵活控制能力的音乐生成模型家族。它巧妙地将语言模型与扩散模型的优势相结合,并融入作曲工作流之中,适用于小白、专业人士的不同音乐创作场景。
本文将深入解读 Seed-Music 的技术能力,揭示其在音乐生成和编辑方面的突出表现。此外,Seed-Music 官网详细展示了十种音乐创作任务的 demo。
由豆包大模型团队自主研发的音乐大模型 Seed-Music,今日正式发布!它拥有统一的框架,能够支持多种音乐生成和编辑任务。
首先,让我们通过一段视频来领略 Seed-Music 的能力:
1. 四大核心功能、十种创作任务,满足不同场景需求
为了适应多元群体的 AI 辅助音乐创作需求,Seed-Music 提供了四大核心功能:可控音乐生成、谱转曲、词曲编辑、零样本人声克隆,具体涵盖十种创作任务,满足音乐小白、专业音乐人的不同场景需求。
为了让大家更深入地体会 Seed-Music 的模型能力,我们一起来进行具体的拆解演示。
1.1 Lyrics2Song 可控音乐生成
Lyrics2Song 功能包含“1 分钟片段生成”、“3 分钟全曲生成”、“歌曲仿写”以及“纯器乐生成”这四种音乐生成任务。
例如,只要输入一些简单的文本指令,如音乐风格、歌词、情绪、节奏等,Seed-Music 就能快速生成一段与之相符的 AI 音乐。
当演唱者换成女声,流派从“乡村音乐”变为“电子舞曲”时,音质依旧逼真自然。
除了文本提示外,Seed-Music 还能基于参考音频进行歌曲仿写。在下面的 demo 中,我们以英文歌曲音频为参考,生成听感高度相似的中文音乐,展现了 Seed-Music 在跨语言歌词创作方面的能力。
1.2 Lyrics2Leadsheet2Song 谱转曲
lead sheet 即“领谱”,通常包括歌曲的主旋律、歌词以及和弦标记等信息,它就像是一张音乐地图或指南,用于指导演奏者或歌手进行表演。
Seed-Music 将领谱集成到 AI 辅助创作的工作流程中,增强了音乐创作的可解释性和可控性,旨在帮助专业音乐人提升效率,专注于音乐的创意表达。
无论是基于歌词生成领谱、从领谱到完整演奏的生成,还是从领谱到声乐的演绎,音乐家们都可直接在 lead sheet 上进行编辑和调整,轻松对音符的音高、时长、位置以及节奏的快慢进行调整,从而可视化地控制音乐的创作过程。
1.3 Music Editing 词曲编辑
基于扩散模型实现的 Music Editing 能够精确对歌词或旋律进行局部改编,并确保编辑区域的平滑过渡。
比如,在一首歌曲中,创作者想要把某句歌词从“一捧黄河水”改成“一捧长江水”,同时希望保持旋律和伴奏的连贯性,Music Editing 就可以轻松做到,而且效果自然。
1.4 Singing Voice Conversion 零样本人声克隆
零样本人声克隆也是 Seed-Music 的一大创新,模型无需针对特定音色进行大规模训练。创作者只需要使用自己 10 秒的语音(支持清唱或者说话)作为输入,系统便可模仿指定音色生成完整的歌曲。
这使得创作者无需花费大量时间进行录音,就能快速预览声音效果,从而拓宽了音乐创作的边界。
2. Seed-Music 技术方法详解
从上述例子能够看出,Seed-Music 是一个端到端且能力全面的音乐生成框架。它既能从自然语言和音频中汲取灵感,又能灵活控制各种音乐属性,还能与音乐人的工作流无缝集成,生成旋律丰富、质量上乘的音乐作品,为不同人群赋予了创作自由。

论文:《Seed-Music: A Unified Framework for High Quality and Controlled Music Generation》
Seed-Music 官网:https://team.doubao.com/seed-music
AI 音乐生成面临着诸多挑战,如领域复杂性、评估局限性和用户需求多样性。其中,音乐信号的复杂性是关键问题之一。音乐信号通常包含多个重叠音轨、多样化的音调、音色以及高采样率信号。此外,音乐信号还兼具短期的旋律连贯性和长期的结构连贯性。
声乐音乐生成则更为复杂,需要同时处理歌词、旋律、和声、节奏等多个因素,并且要在整个曲目中保持连贯。尽管大模型技术取得了一定进展,但仍难以保证生成高质量音频。
而且,音乐是高度艺术化、开放性和主观的,这与图像或语音生成有所不同。音乐生成缺乏一套通用的评价标准和公认的标杆。其中,音乐小白和专业音乐家的需求也截然不同,即使在专业人士中,不同类型的音乐家,如吉他手和声乐家也有着不同的需求。
针对这些挑战,Seed-Music 采用独特的技术方案,提出了音乐生成的通用架构。
为了支持灵活的控制输入,能够根据不同类型的用户输入生成高质量的音乐,该架构宏观上由三个核心组件组成:表征模型、生成器和渲染器。其中,表征模型负责从原始音频波形中提取有意义且紧凑的音乐音频表征;生成器根据用户输入生成音频表征;最后,渲染器负责把音频表征生成最终音频。
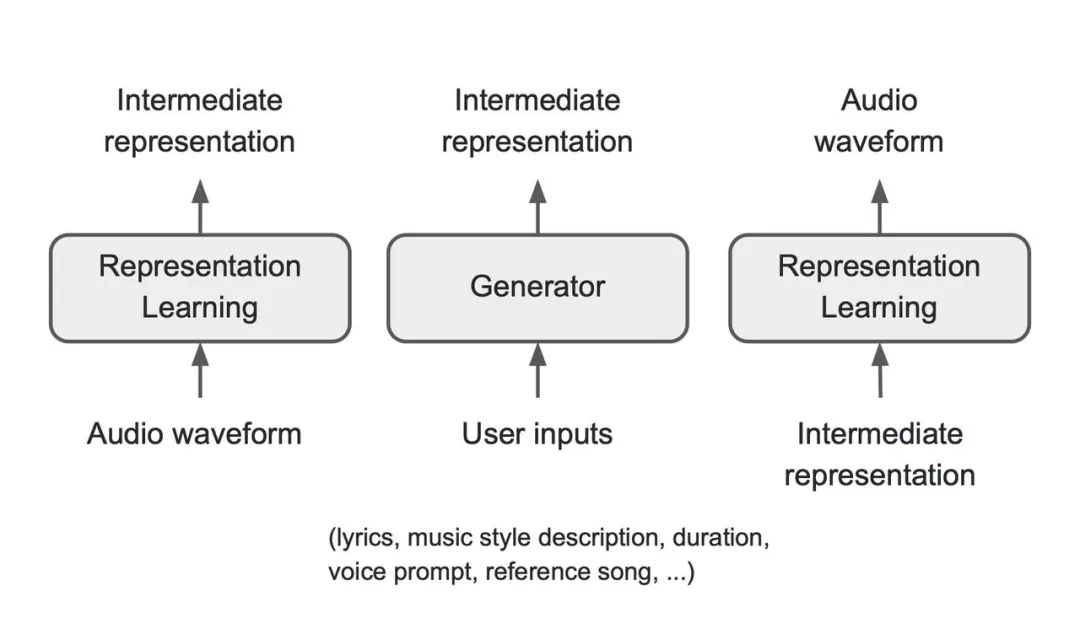
注:An overview of Seed-Music framework
在该架构下,Seed-Music 探索了三种中间表征:音频 token、符号音乐 token 和声码器 latent,每种表征对应着一种生成链路。每种链路都有其优缺点,可以根据下游音乐创作任务匹配最合适的链路。
2.1 基于音频 token 的链路
音频 token 的目标是生成远低于音频采样率的离散 token,旨在有效地编码语义和声学信息。当使用自回归语言模型作为生成器骨干时,音频 token 可以轻松地桥接不同的模态。

注:Overview of the Seed-Music pipeline with audio token as intermediate representation
该链路包含四个主要组成部分:
-
tokenizer,其作用是将原始音频波形压缩为离散的低码率 token;
-
自回归语言模型,它接收用户的各种控制信号,转换为 prefix token ,并预测出目标音频 token 序列;
-
token 扩散模型,根据语言模型预测的目标音频 token 预测连续的声码器 latent;
-
声码器,根据声码器 latent,渲染出高质量的 44KHz 立体声音频波形。
音频 tokenizer 的设计至关重要,它需要在高压缩率的情况下保留关键信息,以提高自回归语言模型的训练效率。同时,还要在分配更多码本容量给与生成器训练目标一致的语义信息,以及在“编码更多语义信息”和“增强 token 到波形的重建性能”之间取得平衡。
2.2 基于符号音乐 token 的链路

注:Overview of the pipeline using symbolic tokens as the intermediate representation
lead sheet tokenizer 将 5 轨 lead sheet(声乐、钢琴、吉他、贝斯、鼓)的信息编码为预定义码本中的 token 序列。语言模型学习基于歌词信息预测 lead sheet token 序列,而不是音频 token。在训练时,我们利用音乐转录模型和 ASR 模型对音乐音频进行标注,以此作为语言模型训练的预测目标。
与音频 token 不同,lead sheet token 具有可解释性,可以和乐谱相互转换,允许在训练和推理过程中注入人类知识。例如,在采样序列中的下一个 token 时,可以根据音乐理论排除违反常规的 lead sheet token。此外,lead sheet 作为中间结果,使音乐家能够在这个阶段介入模型,进行乐谱编辑等交互创作。
与音频 token 不同,lead sheet token 包含音符、歌词、乐器类型和元信息等,而不包含声学信息。因此,从 lead sheet token 预测声码器 latent 对扩散模型来说是一个更具挑战性的任务,需要显著扩大扩散模型的规模以达到相同的端到端性能。
2.3 基于声码器 latent 的链路
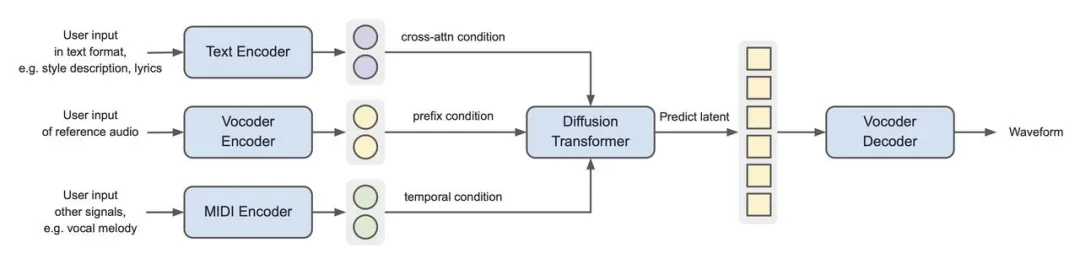
注:Seed-Music pipeline with vocoder latents as intermediate representation
Seed-Music 也探索了基于声码器 latent 的链路。在这种链路下,通过变分自编码器把输入音频压缩成声码器 latent,并训练扩散模型将条件信号映射到连续的声码器 latent 空间。
当使用声学声码器 latent 作为中间表示时,扩散模型和声码器的架构与基于音频 token 的管道类似。但是去除了自回归模型后,整体链路层数较少,训练和推理效率都更高,当然也需要扩大每个组件的模型以实现可比的性能。
扩散模型的另一大优势是它支持多种不同的控制信号,比如支持通过声码器 latent 空间中的前后文预测掩码区域、支持通过交叉注意力注入文本控制信号,也支持通过添加时间对齐的输入信号(如人声旋律)来生成对应伴奏。
2.4 模型训练和推理
Seed-Music 的训练经历预训练、微调和后训练三个阶段。预训练阶段旨在为音乐音频建模建立强大的基础模型;微调阶段包括基于高质量音乐数据集的数据微调,以增强音乐性,以及指令微调,以适配特定的创作任务;后训练通过强化学习进行,提高了模型的整体稳定性。
在推理时,样本解码方案对于从训练模型中诱导出最佳结果至关重要。通过仔细调整 Classifier Free Guidance,确保了整体的音乐性和对提示的依从性。此外,为了提高级联生成系统的延迟,Seed-Music 实现了流式解码方案,使语言模型和扩散模型的推理能够并行进行,从而实现在用户输入指令 3 秒以内即可开始播放生成音乐。
3. 音乐创作的「金牌辅助」,为媒体创作带来全新可能
上文展示了 Seed-Music 通过自然语言和音频输入、可解释的领谱、词曲编辑和零样本语音转换系统生成高质量声乐的效果,详述了 Seed-Music 基于三种音乐音频表征的生成技术及其模型训练、推理的方法。
传统的音乐创作过程往往复杂繁琐,限制了很多人的创作热情。Seed-Music 能够通过定制化的技术解决方案,为音乐小白和专业音乐人士提供同样精准、高效的支持,堪称音乐创作的「金牌辅助」。
比如,对于音乐小白,Seed-Music 将文生音乐与音色克隆相结合,让普通人能够低门槛地开始音乐创作,将自己的声音融入到音乐的构思之中,创造出自己的专属音乐。
而对于专业音乐人士,Seed-Music 以尊重并融入音乐家、作曲家、歌手和艺术家的工作流程为准则,让专业创作者可以实现对词、旋律、编曲的完全控制,节省创作中的时间和成本,更快地试听音乐创意。Seed-Music 帮助音乐人发挥创造力,产出更多意想不到的音乐灵感。

声音是个人身份的重要标识之一,AI 音乐创作的安全性问题值得重视。为避免 Seed-Music 被滥用于模仿他人,团队采用了 Seed-TTS 同类安全措施流程,其中包括会对语音内容和声音进行多步验证,并在整个音乐生成过程中,实施多级水印方案和重复检查。
音乐是短视频、长视频、游戏和 AR/VR 等多媒体体验中不可缺少的一部分,在未来,Seed-Music 的音乐生成或许能够实现一种全新的艺术媒介——其中,生成音乐响应的不仅仅是文本,还包括游戏内故事情节和视觉艺术风格等环境信号,进而为多媒体创作带来更多的可能性。
豆包大模型团队致力于为创作者提供支持、为音乐制作提高效率,让音乐成为人类无门槛、无边界、无限制的表达方式。如果对 Seed-Music 的成果感兴趣,欢迎访问官网,或通过 PC 端浏览官网 https://team.doubao.com/seed-music 以体验更多 demo 效果、了解更多技术细节。
同时,我们希望吸纳有同样志向和目标的优秀人才加入团队,共同解决技术问题、实现技术设想,为 Seed-Music 带来更多突破。