Doubao Large Language Model Team Open-Sources New Benchmark for Code Large Models, Covering Over 11 Real-World Programming Scenarios for the First Time
Doubao Large Language Model Team Open-Sources New Benchmark for Code Large Models, Covering Over 11 Real-World Programming Scenarios for the First Time
日期
2024-12-06
分类
技术解读
Today, ByteDance's Doubao Large Language Model (LLM) team open-sourced FullStack Bench, a dataset specifically designed for evaluating code generation in full-stack and multilingual programming scenarios.
This dataset is the first in the industry to encompass over 11 real-world scenarios within the full spectrum of programming technologies, covering 16 programming languages and containing 3374 problems. Compared to previous benchmarks, it can more effectively assess the real-world code development capabilities of LLMs. Concurrently, the team has also open-sourced SandboxFusion, a highly efficient code sandbox execution tool for evaluating various programming tasks across different languages.
Comprehensive experimental results demonstrate that FullStack
Bench accurately reflects the performance of LLMs in diverse practical code development scenarios, contributing to the further advancement of code intelligence.
Code Large Language Models (code LLMs) have made significant strides in code intelligence. To reveal the limitations of existing code LLMs and propel further development in this field, several code evaluation benchmark datasets have been proposed, such as HumanEval, MBPP, DS-1000, McEval, MDEval, and xCodeEval.
However, current evaluation benchmarks offer limited coverage of programming languages and application types, making it difficult to comprehensively reflect the diverse programming capabilities required in real-world code development scenarios. For example, the majority of the data (nearly 80%) in HumanEval and MBPP focuses solely on basic and advanced programming problems.
To address these limitations, the Doubao LLM team at ByteDance, in collaboration with the M-A-P open-source community, introduced FullStack Bench, an evaluation set encompassing multiple real-world application domains and programming languages. This benchmark aims to assess the capabilities of LLMs in a variety of real-world code development scenarios.
To support the multi-domain and multilingual programming evaluation requirements of FullStack Bench, the team developed a new sandbox execution environment – SandboxFusion. This environment supports 23 commonly used programming languages and caters to the needs of diverse application scenarios, including front-end development, back-end development, and machine learning training.
Comprehensive experimental results demonstrate that FullStack Bench accurately reflects the performance of LLMs in various practical code development scenarios, thereby driving further advancements in the field of code intelligence.

Currently, the research paper, dataset, and sandbox experience portal are all publicly available.
FullStack Bench: Evaluating LLMs as Full Stack Coders
论文链接: https://arxiv.org/abs/2412.00535
数据集开源地址: https://huggingface.co/datasets/ByteDance/FullStackBench
沙盒开源地址: https://github.com/bytedance/SandboxFusion
沙盒体验入口: https://bytedance.github.io/SandboxFusion/playground/datasets
A Gap in Multi-Domain, Multilingual Code Evaluation Benchmarks
Code evaluation benchmarks play a crucial role in the development of code LLMs. They serve not only as standard tools for measuring model capabilities but also as key drivers for promoting model optimization and refinement.
Despite their central role in the research and application of LLMs, existing benchmarks still have significant limitations, particularly in reflecting the diversity and complexity of real-world code development scenarios.
For instance, most of the data (nearly 80%) in HumanEval and MBPP focuses only on basic and advanced programming problems. DS-1000 focuses primarily (over 95%) data analysis and machine learning tasks, evaluating only Python code. While xCodeEval covers multiple tasks, it is largely limited to advanced programming and mathematics. McEval and MDEval expand the supported programming languages, covering 40 and nearly 20 languages respectively, but their application domains remain confined to basic and advanced programming problems, failing to encompass broader application scenarios.
Furthermore, automated evaluation of a multi-task, multilingual code benchmark presents numerous challenges. Although some sandbox execution environments exist, such as DifySandbox, MultiPL-E, and MPLSandbox, they still have significant limitations, such as lacking support for front-end browsers and deep learning packages, and supporting a limited number of programming languages.
Building FullStack Bench: A Full-Stack, Multilingual Code Evaluation Benchmark
To simulate real-world application scenarios in full-stack development, the research team analyzed the problem distribution on Stack Overflow, the world's largest programmer technical Q&A community, and extracted common real-world programming application domains. As illustrated, the team randomly sampled 500,000 problems from Stack Overflow and used an LLM to label each problem with its corresponding application domain type.
The research team selected the main application domains accounting for the top 88.1% of the total problems, categorizing the remaining domains as "Others." Based on this, the team completed the labeling of problem domain types and adjusted the distribution to ensure robustness in each domain, ultimately forming the 11+ application scenarios and their distribution ratios covered by FullStack Bench. Detailed descriptions of the specific domain types can be found in the original paper.

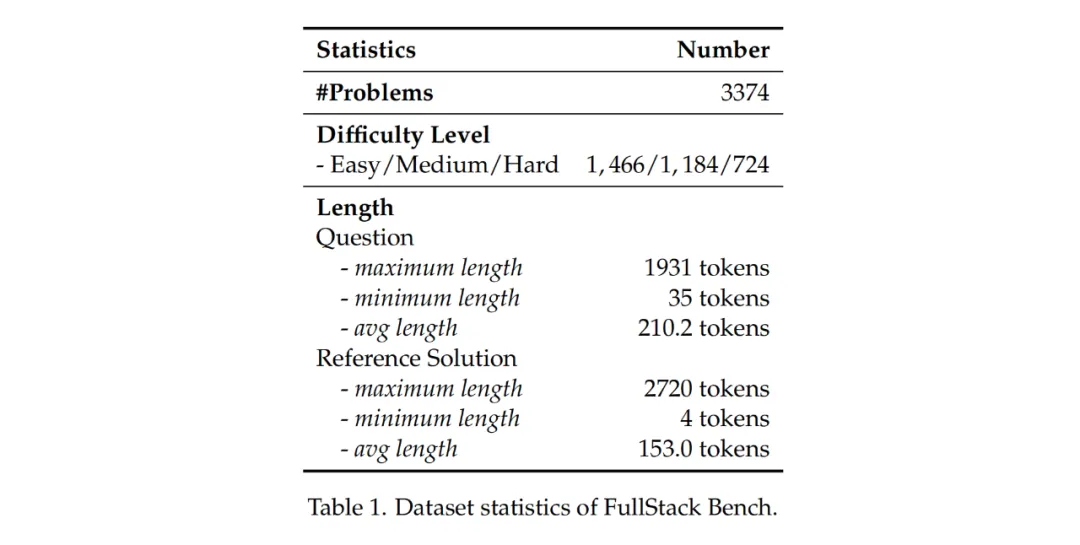
FullStack Bench contains 3374 problems (half in Chinese and half in English). Each problem includes a problem description, a reference solution, unit test cases, and labels. To ensure evaluation accuracy, the content of each problem was designed by programming experts in the relevant fields and reviewed for quality through both AI and manual verification. For example, data analysis-related problems were proposed and reviewed by data engineering experts.
The construction of FullStack Bench employed a comprehensive and systematic manual annotation process for generating code samples in different application domains. The research team collected code snippets in various programming languages from GitHub and code-related documentation, and used LLMs combined with manual verification to generate instructions, unit test cases, and reference solutions.
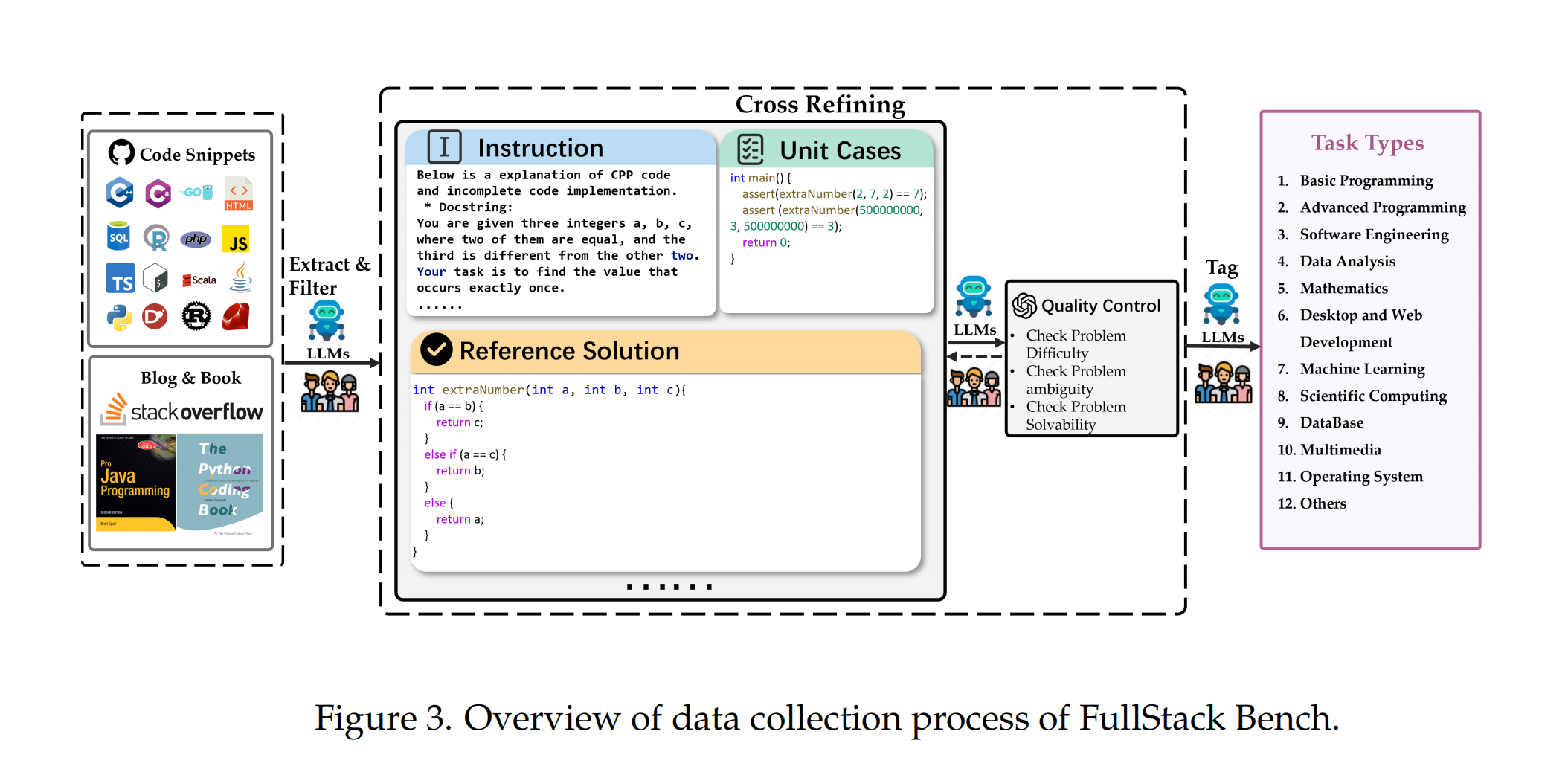
After the initial dataset construction, annotators assessed data quality based on problem difficulty, ambiguity, and solvability, and cross-refined to minimize subjective bias. Any discrepancies between annotators are resolved through consensus or with input from senior annotators to ensure data accuracy.
Following the completion of FullStack Bench, the researchers conducted statistical analysis, as shown in the figure. The researchers used the LLaMA3 tokenizer to calculate the token lengths of the problem descriptions and correct code, with an average problem description length of 210.2 tokens. To ensure evaluation accuracy, the dataset contains a total of 15,168 unit tests, with an average of 4.5 unit test cases per problem.
SandboxFusion: A High-Efficiency Code Sandbox Execution Tool
To facilitate systematic testing of LLM code capabilities by developers, the Doubao LLM team also open-sourced SandboxFusion, a high-efficiency code sandbox execution tool for evaluating various programming tasks across different languages. In addition to FullStack Bench, SandboxFusion is compatible with over 10 widely used code evaluation datasets and supports 23 programming languages. Developers can easily deploy SandboxFusion on a single server or experience it directly on GitHub.
SandboxFusion primarily comprises two modules: a dataset module and a sandbox execution module. The dataset module is responsible for implementing various datasets and extracting reusable common components. The sandbox execution module focuses on executing code in different languages, controlling resource usage, and ensuring execution safety.
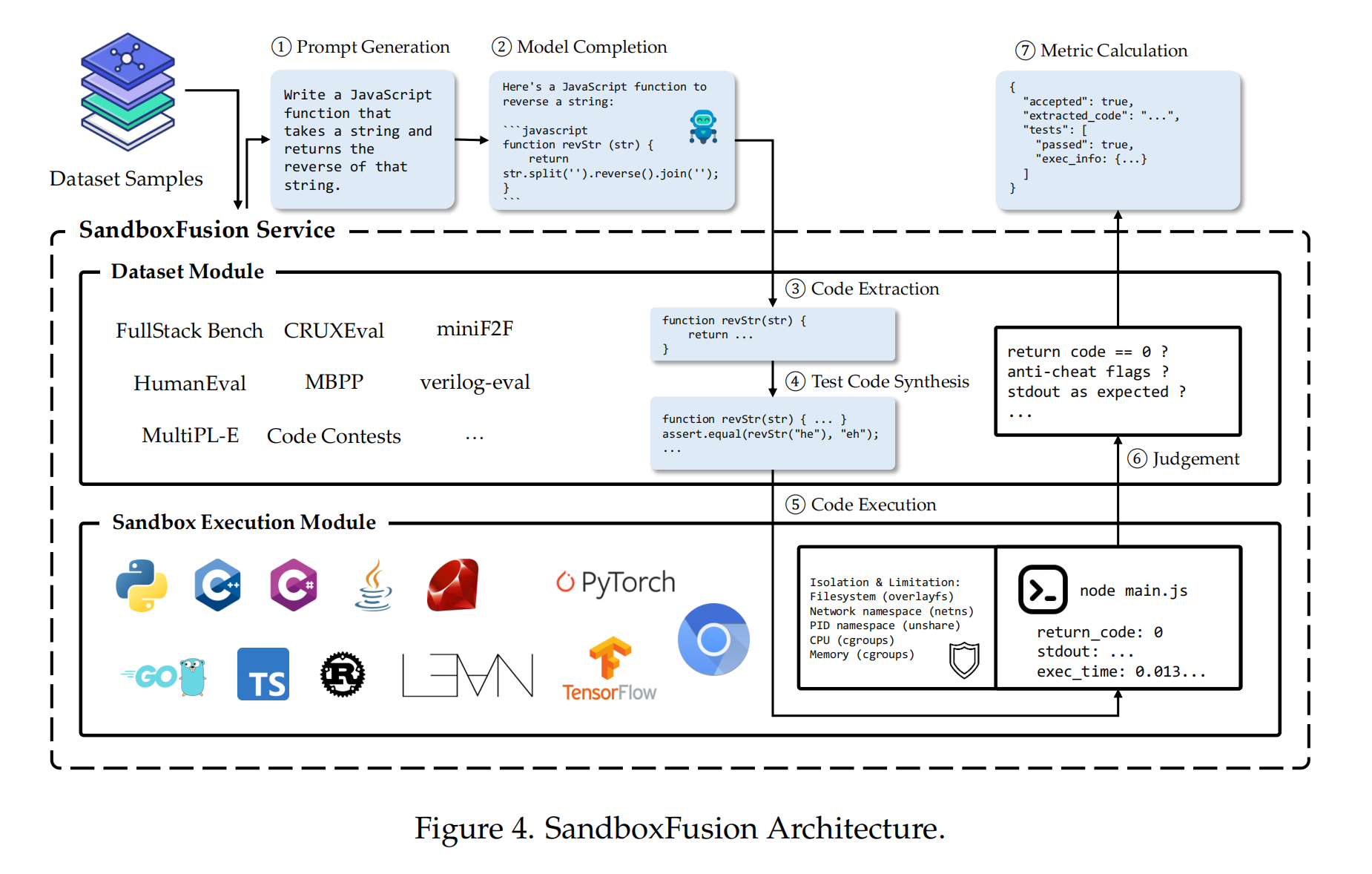
As illustrated, the evaluation process of SandboxFusion includes the following steps:
Prompt Generation: Generates different prompts based on the original data and testing mode (e.g., few-shot, zero-shot).
Model Completion: Users need to independently use the generated prompts for model completion; the sandbox does not have a built-in inference module.
Code Extraction: The system extracts executable code segments from the model output, primarily focusing on code contained within markdown.
Test Code Synthesis: The system combines the extracted code with predefined test cases to create executable test programs. This process handles language-specific features, such as splitting classes into files in Java or adjusting entry functions for unit tests.
Code Execution: The system executes the synthesized code and all dependency files, capturing the program output.
Judgment: The system evaluates the correctness of the model output based on the execution results, typically through standard unit testing frameworks, where a zero return value indicates successful execution.
Metric Calculation: Evaluation metrics are aggregated and calculated outside the sandbox, primarily focusing on the pass rate.
Evaluation Results: Closed-Source Models Still Outperform Open-Source Models in Solving Difficult Problems
Along with the release of the evaluation benchmark and sandbox, the research team evaluated the programming performance of over twenty global code and language models based on FullStack Bench. These models include open-source models like Qwen2.5-Coder, DeepSeek-Coder-v2, and CodeLlama, as well as closed-source models like GPT-4o, OpenAI-o1, and Doubao-Coder-Preview. For open-source models, they were divided into five groups based on model size: 1B+, 6B+, 13B+, 20B+, and 70B+. For more experimental configurations and testing details, please see the paper.
- Cross-Domain Performance: Largest Discrepancies in Mathematical Programming
Unsurprisingly, OpenAI o1-preview leads thanks to its powerful reasoning capabilities. However, some open-source models also performed well. For instance, DeepSeekCoder-v2-Instruct achieved high scores in AP (Advanced Programming), OS (Operating System), and other categories, widening the gap with other open-source models. OpenCoder-1.5B-Instruct, Qwen2.5-Coder-7B-Instruct, and Qwen2.5-Coder-14B-Instruct topped their respective open-source groups and surpassed some models with higher parameter counts.
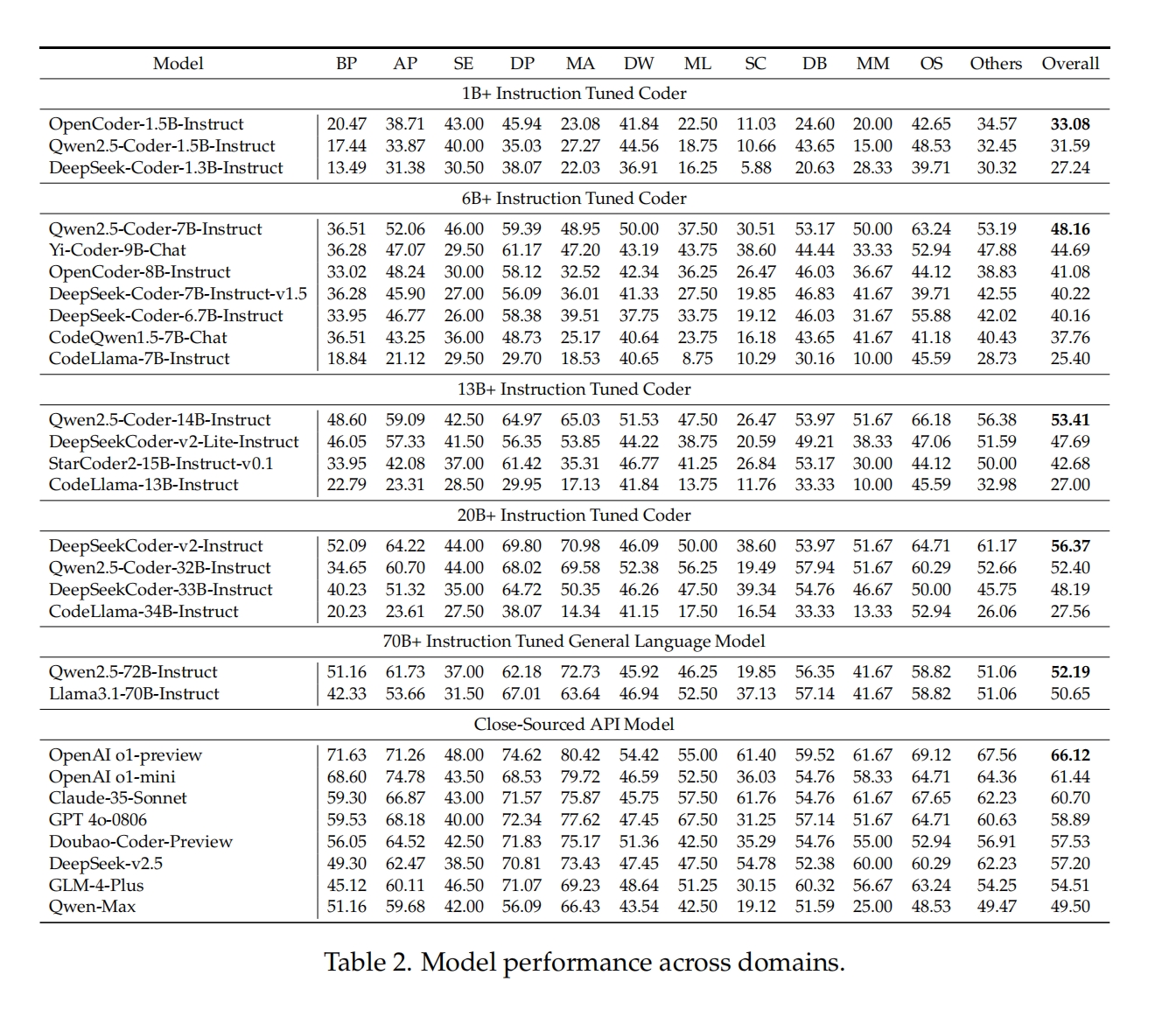
To comprehensively evaluate the performance of existing LLMs in different scenarios, the research team visualized the model performance across various domains in FullStack Bench. Significant performance differences were observed in domains like BP (Basic Programming), AP (Advanced Programming), MA (Mathematical Programming), ML (Machine Learning), and MM (Multimedia), with the largest gap in the MA domain. The best performer was OpenAI o1-preview (score 80.42), while the worst was CodeLlama-34B-Instruct (score 14.34). Mathematical programming requires models to possess both mathematical and programming capabilities, and models trained on highly specialized code corpora often perform poorly in the MA domain. This result further demonstrates that FullStack Bench can more comprehensively evaluate the overall programming capabilities of models.
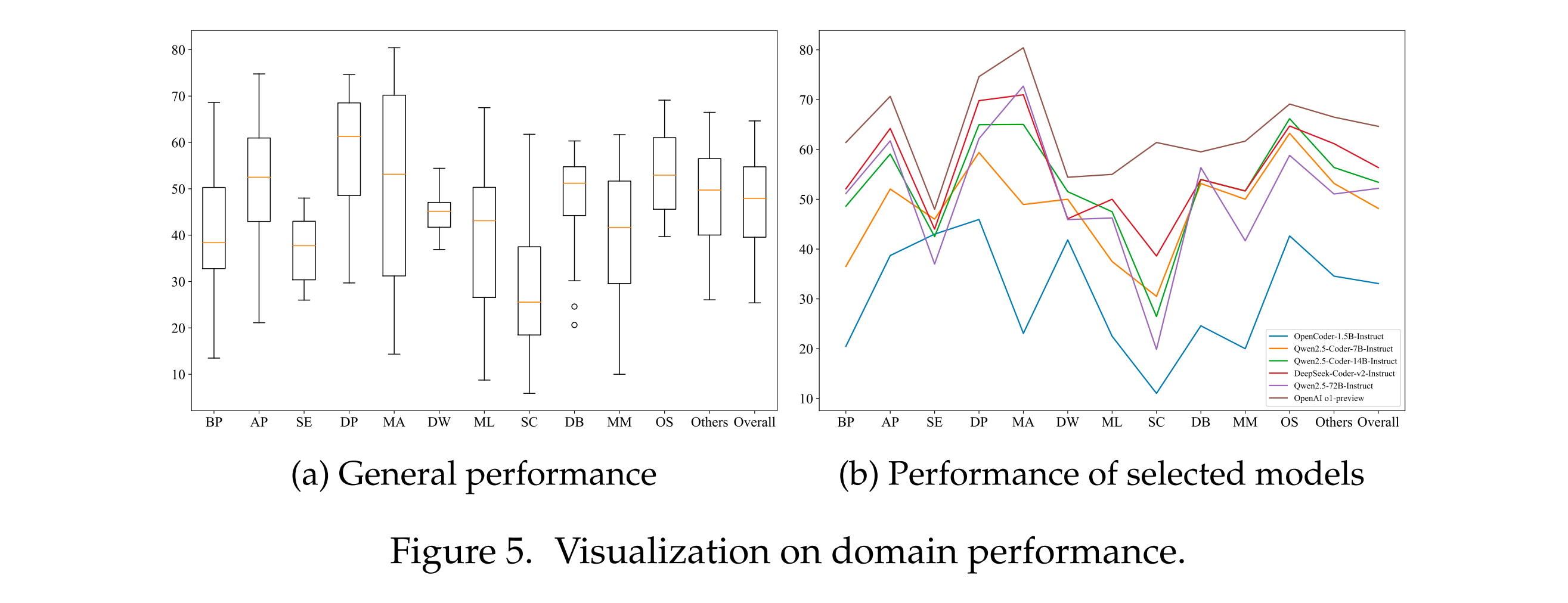
- Cross-Lingual Performance: Significant Differences in C++, C, and Ruby
The research team analyzed the performance of different models across various programming languages, as shown in the figure. Most models performed well in Bash programming tasks. However, significant performance differences were observed in C++, C, and Ruby, suggesting that model designers may have selectively sampled these languages in the training corpora. Some smaller 1B+ models performed poorly in D, R, and Scala, with pass rates below 10%, indicating weaker multilingual processing capabilities.
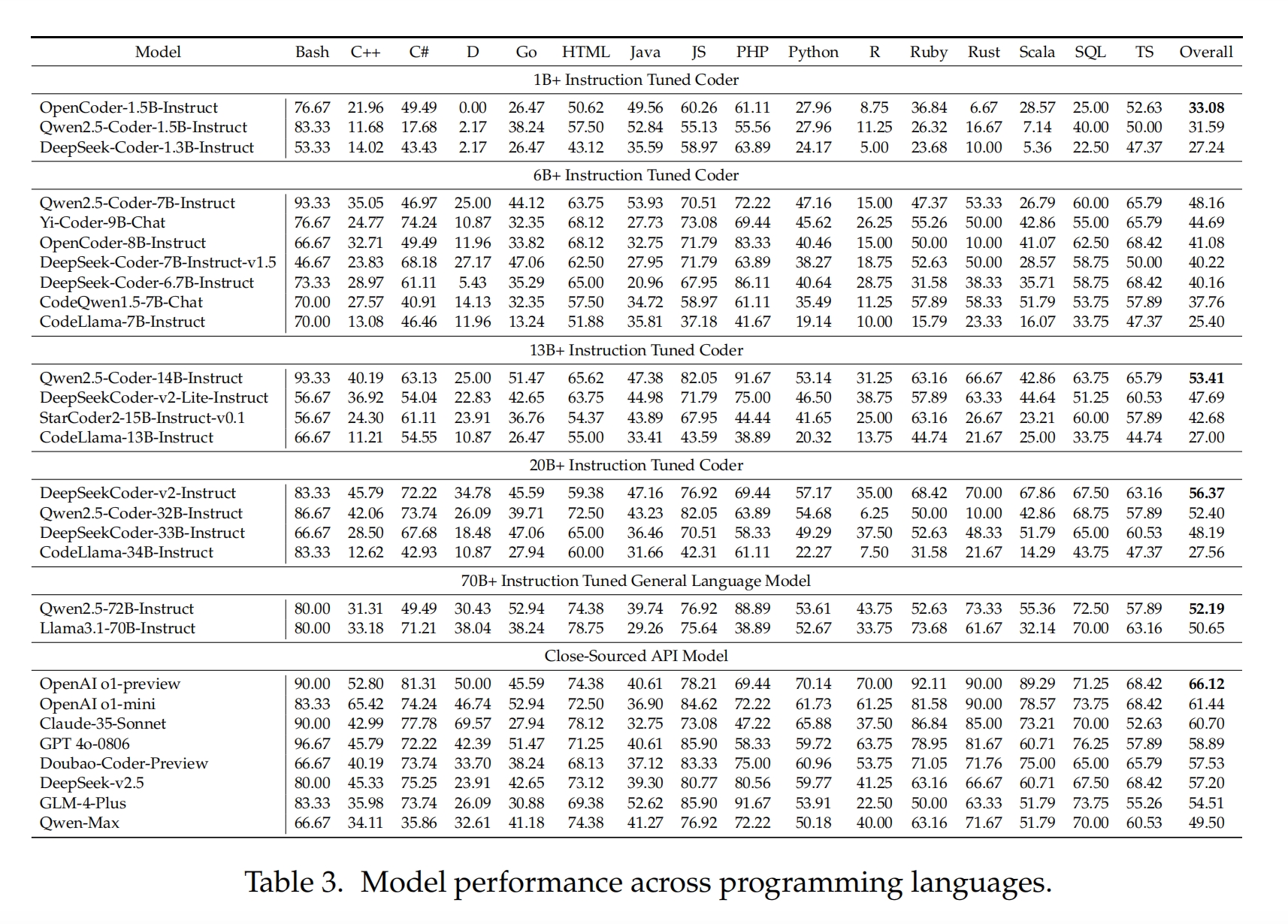
As SandboxFusion provides feedback from the compiler, the researchers evaluated the compilation pass rates of models in some programming languages. The experimental results showed a positive correlation between compilation pass rate and test pass rate, but successful compilation does not guarantee passing the tests. The researchers also explored the impact of Chinese and English expressions on model performance.
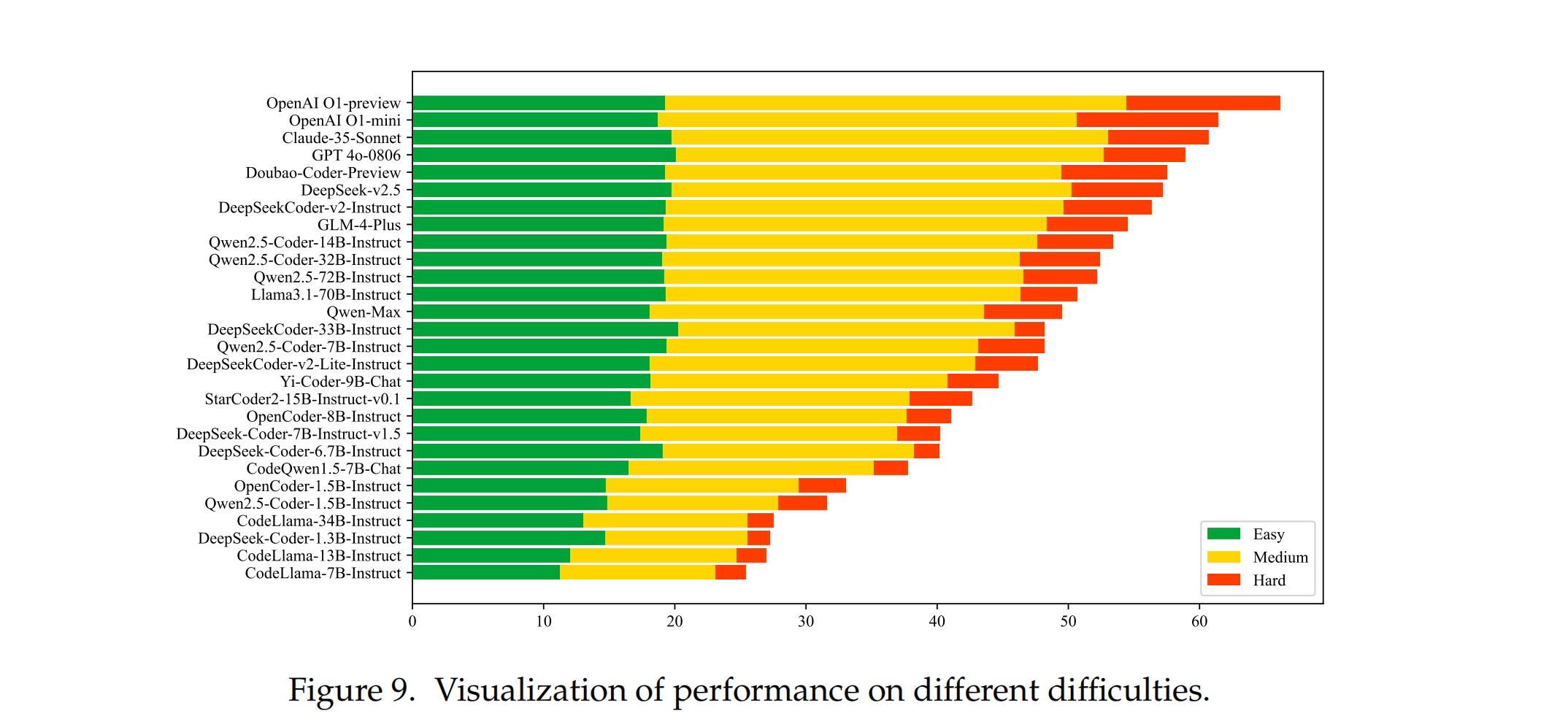
- Closed-Source Models Generally Outperform Open-Source Models in Solving Difficult Problems
Different models exhibit significant performance variations on problems of varying difficulty. Overall, 1B+ models and the CodeLlama series performed poorly across all difficulty levels. The remaining models performed similarly on easy problems, but there were some gaps on medium-difficulty problems. For more difficult problems, closed-source models generally outperformed open-source models.
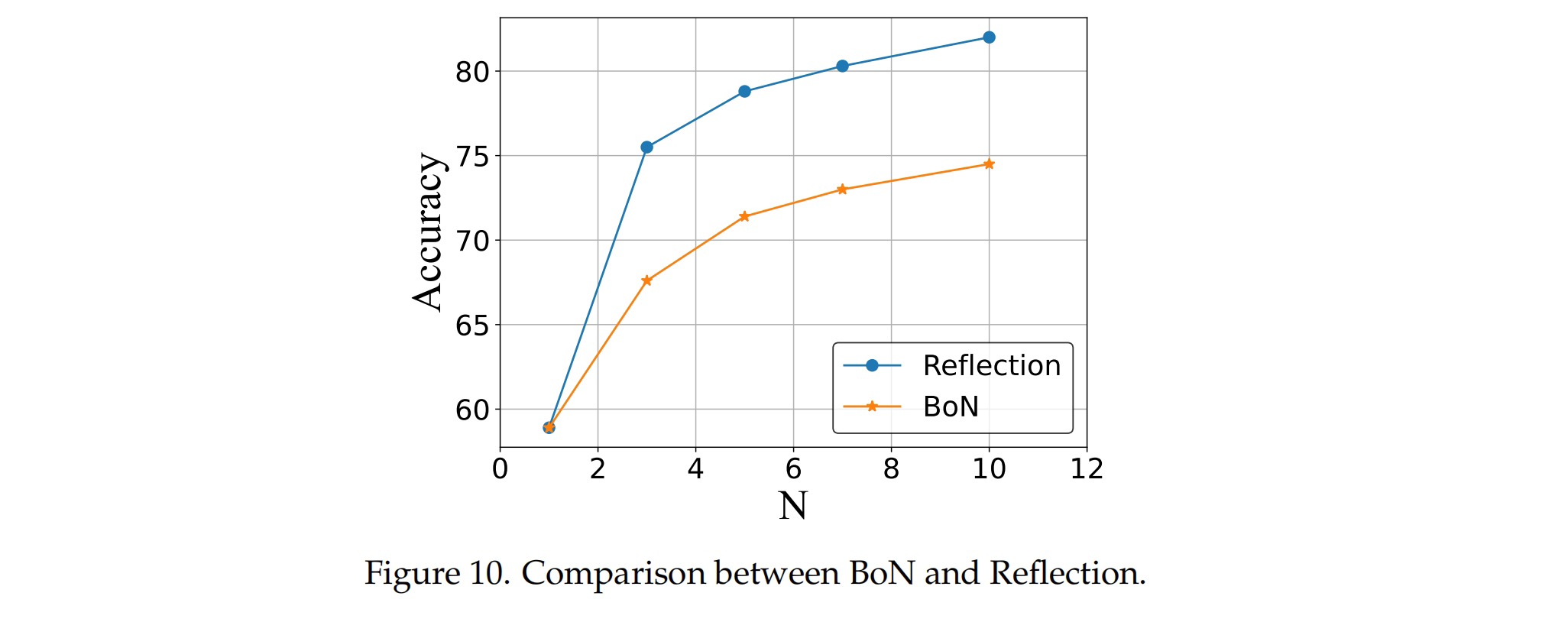
- Using SandboxFusion Can Improve Model Performance
Using SandboxFusion for feedback can significantly improve model performance. The researchers compared two strategies: "Reflection" and "BoN". In the "Reflection" strategy, the answer is refined N times by leveraging the feedback context from SandboxFusion, replicating the self-refinement strategy [Madaan et al., 2024]. In the "BoN" strategy, only N inferences are performed to obtain the result. As shown in the figure, the "Reflection" strategy significantly outperformed "BoN", indicating the high effectiveness of the feedback context provided by SandboxFusion.
Conclusion
The newly proposed code LLM evaluation benchmark, FullStack Bench, and the sandbox execution tool, SandboxFusion, aim to provide a rapid evaluation reference for the potential of AI in real-world programming scenarios, thereby driving the development of code LLMs.
If you are also interested in solving complex problems in the field of LLMs and aspire to explore cutting-edge topics, please visit our careers page for job details.