Optimized by up to 529 times! Doubao's Large Model Teams Up with The University of Hong Kong (HKU) to Launch a New Checkpoint System to Optimize Training Efficiency
Optimized by up to 529 times! Doubao's Large Model Teams Up with The University of Hong Kong (HKU) to Launch a New Checkpoint System to Optimize Training Efficiency
日期
2024-08-08
分类
技术解读
As LLM's iteration speed increases and the scale of training datasets expands, frequent hardware failures and software bugs have become a pain point that hinders AI training efficiency. The checkpoint system, which is responsible for status storage and recovery during the training process, has become the key to overcoming training failures, ensuring progress, and improving efficiency.
Recently, the ByteDance Doubao (Seed) Team and HKU jointly proposed the ByteCheckpoint system. This is a PyTorch native LLM checkpointing system that is compatible with multiple training frameworks, supports checkpoint efficient read/write and automatic resharding. It significantly outperforms existing methods in terms of performance and convenience. This article introduces the challenges faced by Checkpoint in LLM training efficiency, and summarizes ByteCheckpoint's solutions, system design, I/O performance optimization techniques, and experimental results in storage performance and read performance testing.
As the scale of training clusters and the size of models continue to grow, hardware and software failures during large model training have become increasingly common. Addressing these frequent failures and boosting training efficiency have become the keys to rapid iteration of large language models.
The Checkpoint system, which saves and restores training states, marks a significant advancement in mitigating failures and enhancing efficiency. The ByteDance Doubao (Seed) Team, in collaboration with HKU, has unveiled their latest innovation: ByteCheckpoint. This system, native to PyTorch and compatible with multiple training frameworks, supports efficient Checkpoint operations and automatic resharding.
ByteCheckpoint outperforms traditional methods, enhancing performance by up to 529.22 times in saving and 3.51 times in loading speeds. Its user-friendly interface and automatic resharding significantly lower barriers to entry and operational costs, making the system more accessible.
The research findings have been made public.
ByteCheckpoint: A Unified Checkpointing System for LLM Development

1. Challenges of Checkpoint Technology in Large Language Model (LLM) Training
Currently, checkpoint-related technologies face four challenges in enhancing LLM training efficiency:
(1) The current system design has flaws, significantly increasing the extra I/O overhead for training
During the training process of industrial-grade large language models (LLMs), the training states need to be saved and persisted through checkpointing technology. Typically, a Checkpoint includes five components: model, optimizer, dataloader, random number generator (RNG), and user-defined configurations. This process often causes minute-level blockages in training, severely impacting training efficiency.
In large-scale training scenarios using remote persistent storage systems, existing checkpointing systems have not fully utilized the independent execution of stages during the checkpoint saving process: GPU to CPU memory copying (D2H copying), serialization, local disk writing, and uploading to storage systems.
Additionally, the potential for parallel processing of Checkpoint access tasks shared by different training processes has not been fully explored. These system design flaws increase the additional I/O overhead brought by the Checkpoint system in training.
(2) Checkpoint resharding is difficult, and the development and maintenance costs of manual resharding scripts are too high
During the different training stages of LLM (from pre-training to SFT or RLHF) and various tasks (pulling checkpoints from different stages of the training task for automatic evaluation), checkpoint migration often involves the resharding of checkpoints stored in the persistent storage system. This is necessary to adapt to new parallel configurations for downstream tasks and available GPU resource quotas.
Existing Checkpointing systems [1, 2, 3, 4] assume that parallelism settings and GPU resources remain unchanged during storage and loading, and cannot handle the needs for resharding. A common solution in the industry is to create custom Checkpoint merging or resharding scripts for different models. This approach incurs substantial development and maintenance costs and offers poor scalability.
(3) Different training frameworks have fragmented Checkpoint modules, posing challenges for unified management and performance optimization of Checkpoints
In the industrial training platforms, engineers and scientists often choose the appropriate frameworks (Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) based on task characteristics, and save the Checkpoint to the storage system. However, these different training frameworks each have their own independent Checkpoint formats and read-write modules. The design of Checkpoint modules differs across various training frameworks, posing challenges for unified Checkpoint management and performance optimization in the underlying systems.
(4) Users of the distributed training system face multiple challenges
From the perspective of training system users (AI research scientists or engineers), they are often troubled by three issues regarding checkpoints when using distributed training systems:
- How to efficiently store checkpoints without affecting training efficiency.
- How to reshard a Checkpoint stored under one parallelism and correctly load it according to the new parallelism.
- How to upload the output of the training to a cloud storage system (HDFS, S3, etc.)? Manually managing multiple storage systems is costly for users to learn and use.
To address these issues, the ByteDance Doubao (Seed) team collaborated with Professor Chuan Wu's lab at The University of Hong Kong (HKU) to introduce ByteCheckpoint.
ByteCheckpoint is a high-performance distributed checkpointing system that unifies multiple training frameworks, supports various storage backends, and possesses automatic checkpoint resharding capabilities. ByteCheckpoint offers a user-friendly interface, implements numerous I/O performance optimization techniques to enhance the performance of storing and reading, and supports flexible migration of Checkpoints across tasks with different parallelism configurations.
2. System Design
(1) Storage Architecture
ByteCheckpoint adopts a storage architecture that separates metadata from tensor data, decoupling checkpoint management from training frameworks and parallelism.
Model and optimizer tensor shards from different training skeletons are stored in storage files. While metadata, including TensorMeta, ShardMeta, and ByteMeta, is stored in a globally unique metadata file.
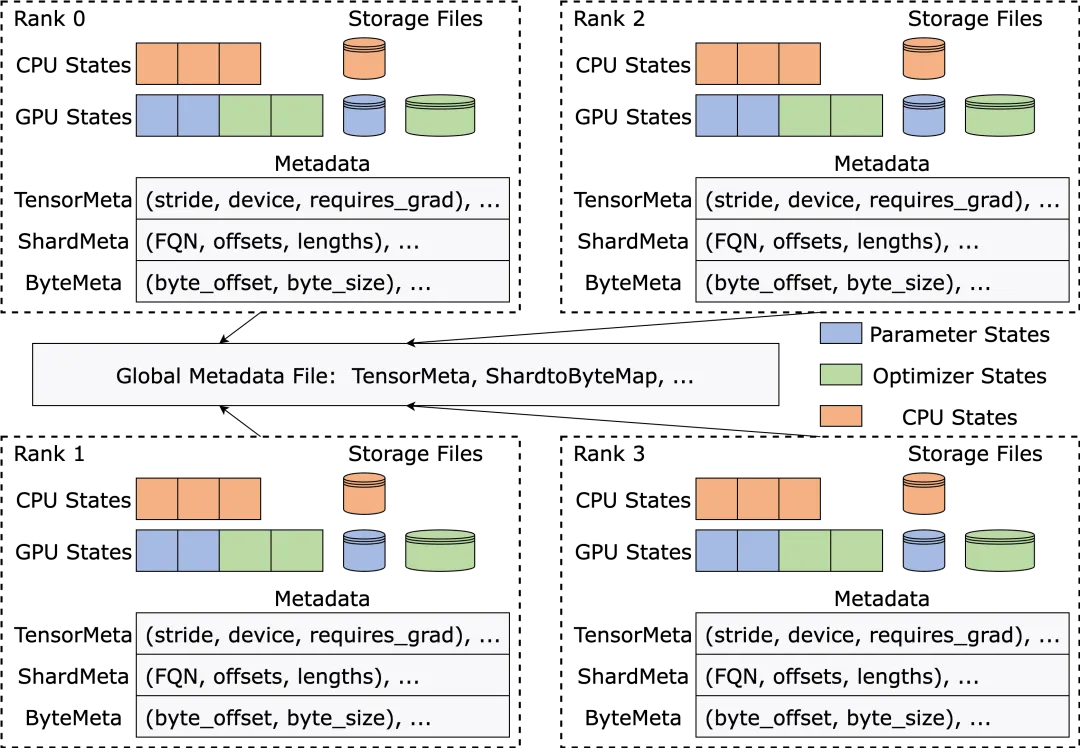
When reading a Checkpoint with different parallelism settings, as shown below, each training process only needs to query the metadata according to the current parallelism settings to locate the storage position of the tensors required by the process. Then, by accessing these locations directly, automatic Checkpoint resharding is achieved.
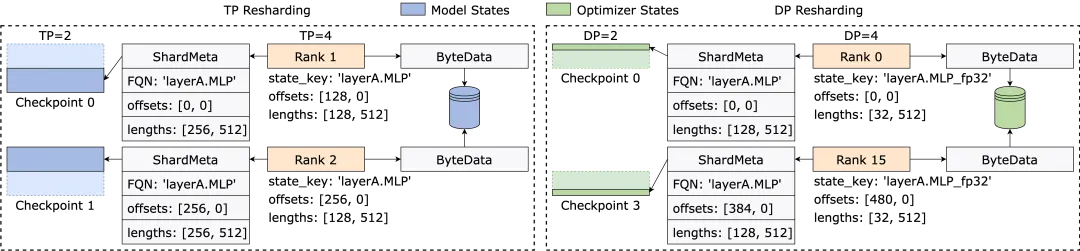
(2) Smartly Addressing Irregular Tensor Sharding
Different training frameworks often flatten the shapes of tensors in a model or optimizer into one dimension during runtime, thus improving collective communication performance. This flattening operation poses challenges for checkpoint storage due to irregular tensor sharding.
As shown in the diagram, in Megatron-LM (a distributed large model training framework developed by NVIDIA) and veScale (a PyTorch native distributed large model training framework developed by ByteDance), the optimizer states corresponding to model parameters are flattened into one dimension, merged, and then split according to data parallelism. This results in tensors being split irregularly across different processes. The metadata of the tensor video cuts cannot be represented by offset and length tuples, posing challenges for storage and retrieval.
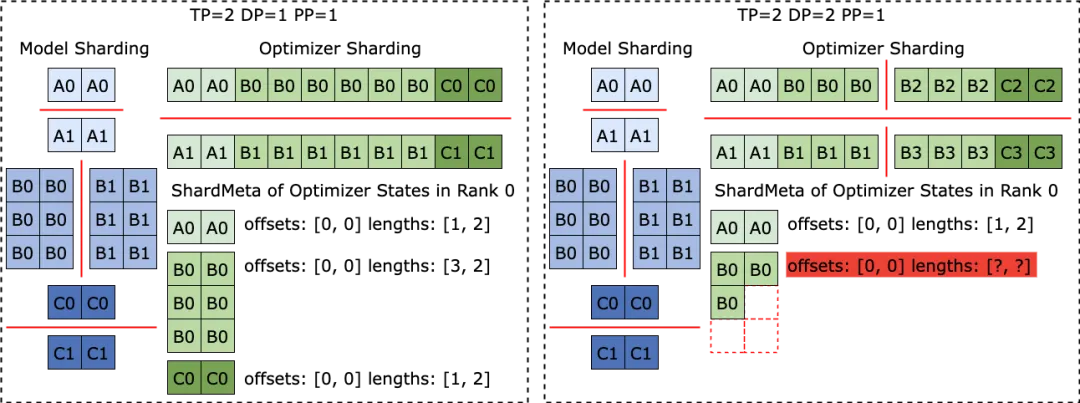
The issue of irregular tensor sharding also exists in the FSDP framework.
To eliminate irregular tensor sharding, the FSDP framework performs all-gather communication operations on all processes before storing the checkpoint and copies the data from the device to the host to obtain the complete irregularly sharded tensor. This solution results in significant communication overhead and frequent GPU-CPU synchronization, severely impacting the performance of Checkpoint storage.
To address this problem, ByteCheckpoint introduced Asynchronous Tensor Merging technology.
ByteCheckpoint first identifies tensors that are irregularly sharded across different processes. It then uses asynchronous P2P communication to distribute and merge these irregular tensors across different processes. All P2P communication waits and tensor D2H copy operations for these irregular tensors are deferred until they are about to enter the serialization stage. This approach eliminates frequent synchronization overhead and increases the overlap between communication and other checkpoint storage processes.
(3) System Structure
The chart below shows the system structure of ByteCheckpoint:
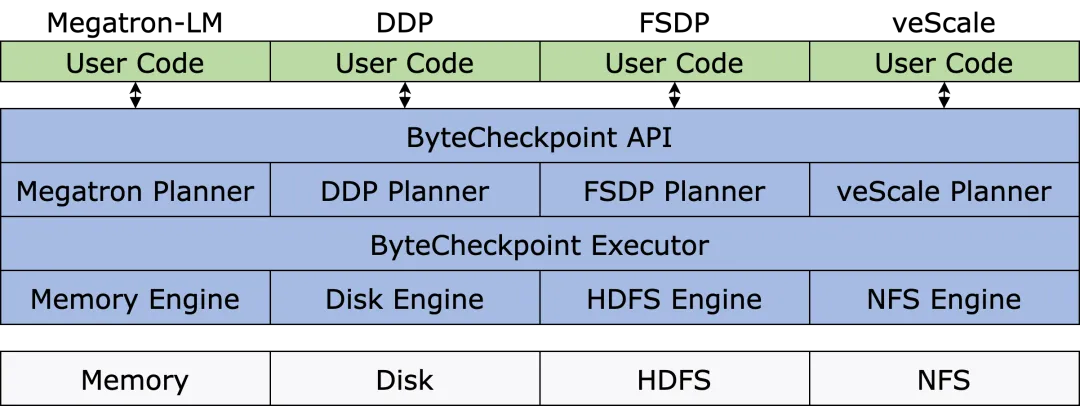
The API layer provides simple, user-friendly, and unified Save and Load interfaces for different training frameworks.
The Planner layer generates access plans for different training processes based on the access objects and delegates the execution of actual I/O tasks to the Execution layer.
The Execution layer performs I/O tasks and interacts with the Storage layer, utilizing various I/O optimization techniques for high-performance checkpoint access.
The Storage layer manages different storage backends and applies corresponding optimizations during I/O tasks based on the specific storage backend.
This layered design enhances the system's scalability, allowing for future support of more training frameworks and storage backends.
(4) API Use Case
API use cases of ByteCheckpoint are as follows:

ByteCheckpoint offers a minimalist API, reducing the learning curve for users. When storing and loading checkpoints, users only need to call the save and load functions, providing the content to be stored or loaded, the file system path, and various performance optimization options.
3. I/O Performance Optimization Technology
(1) Checkpoint Storage Optimization
Pipeline Execution
As shown in the figure below, ByteCheckpoint has designed a fully asynchronous Save Pipeline, which breaks down the different stages of checkpoint storage (P2P tensor transfer, D2H copy, serialization, dump, and file system upload) to achieve efficient pipeline execution.
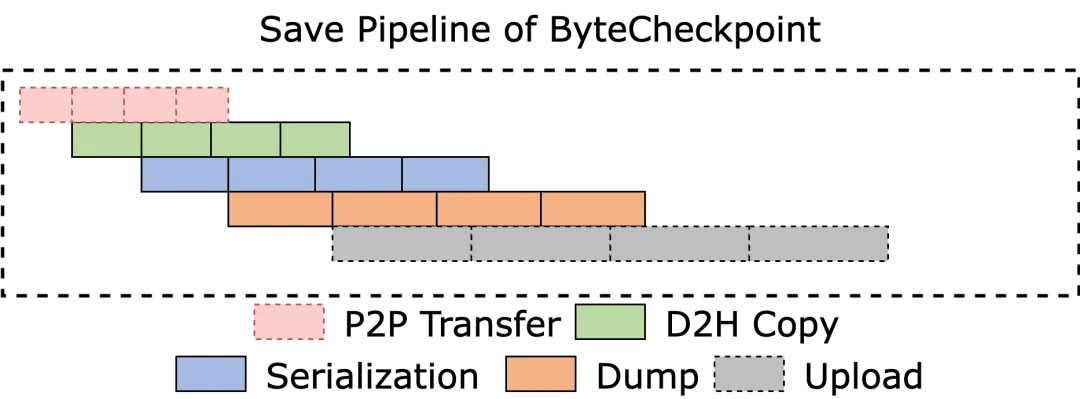
Avoiding Memory Reallocation
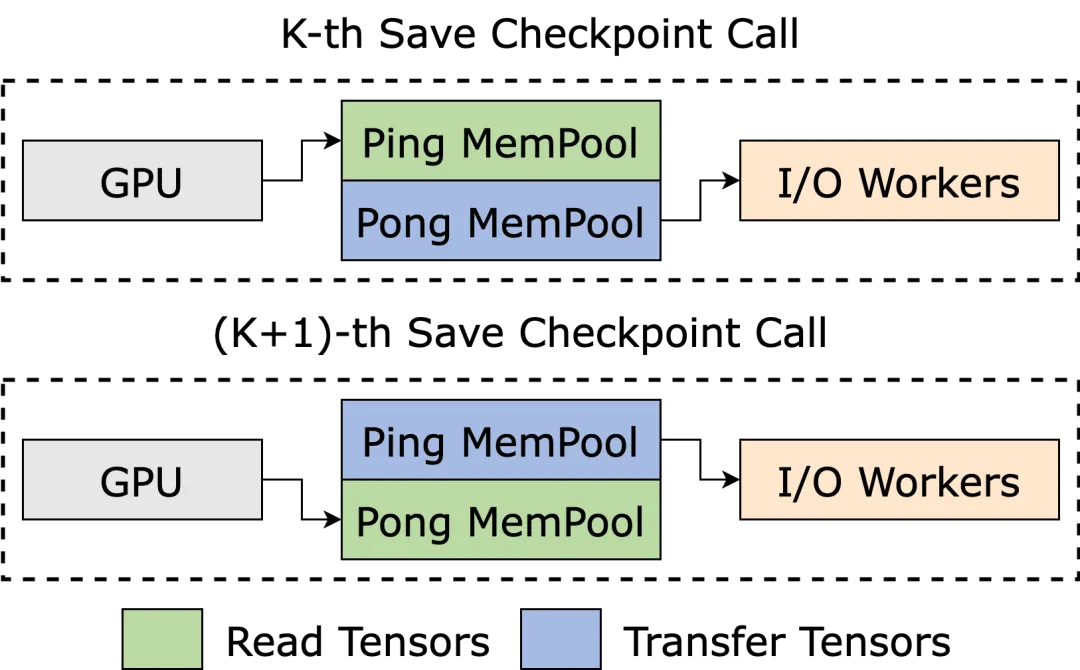
During the D2H copy process, ByteCheckpoint uses a Pinned Memory Pool to reduce the time overhead caused by repeated memory allocations.
Additionally, to minimize the extra time overhead in high-frequency storage scenarios caused by waiting for the Pinned Memory Pool to be reclaimed, ByteCheckpoint incorporates a Ping-Pong buffering mechanism. Two independent memory pools alternately serve as read and write buffers, interacting with the GPU and I/O workers performing subsequent I/O operations, further enhancing storage efficiency.
Load Balancing
In Data-Parallel (DP) training, the model is redundant across different data parallel process groups (DP Group). ByteCheckpoint employs a load balancing algorithm to evenly distribute the redundant model tensors across different process groups for storage, effectively improving checkpoint storage efficiency.
(2) Checkpoint Reading Optimization — Zero Redundancy Loading
When changing the parallelism level to read a checkpoint, new training processes may only need to read a portion of the original tensor slices.
ByteCheckpoint utilizes Partial File Reading technology to directly read the required file segments from remote storage, avoiding the download and reading of unnecessary data.
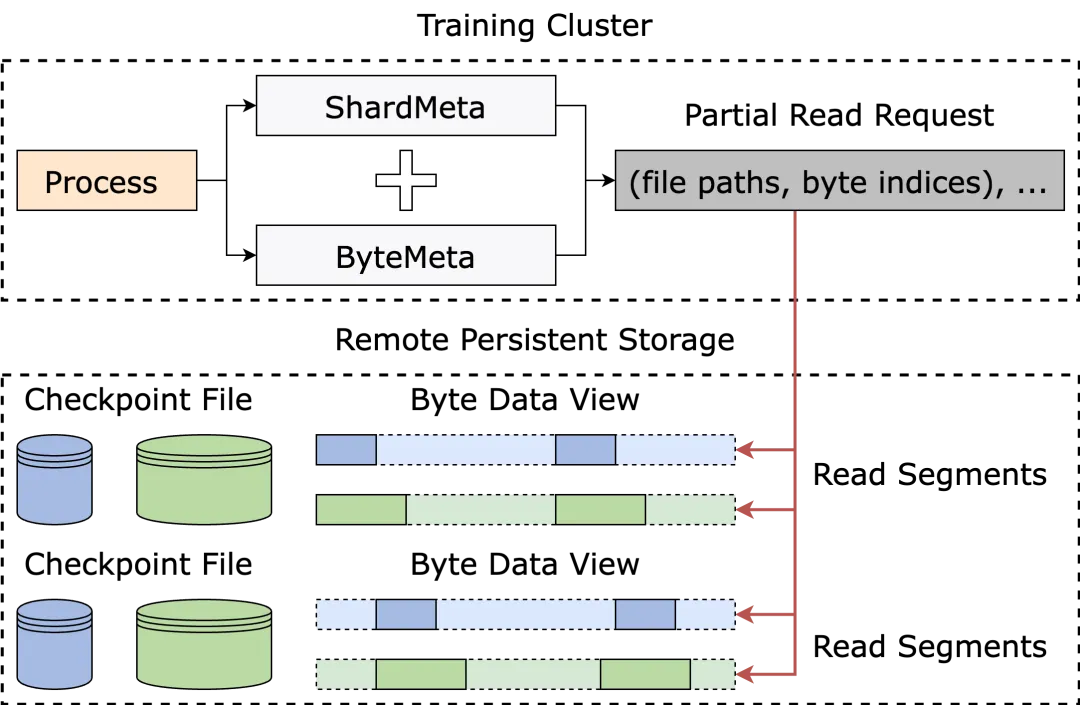
In Data-Parallel (DP) training, the model is redundant across different data parallel process groups (DP Groups), and different process groups repeatedly read the same tensor slices. In large-scale training scenarios, different process groups simultaneously sending a large number of requests to a remote persistent storage system (such as HDFS) can put immense pressure on the storage system.
To eliminate redundant data reading and reduce the number of requests sent to HDFS by the training processes, thereby optimizing loading performance, ByteCheckpoint evenly distributes the tasks of reading the same tensor slices across different processes. While reading from remote files, it utilizes the idle bandwidth between GPUs to transfer tensor slices.

4. Experiment Result
(1) Experiment Configuration
The team evaluated ByteCheckpoint for its checkpoint access correctness, storage performance, and reading performance using DenseGPT and SparseGPT models (implemented based on the GPT-3[10]architecture) across different model parameter sizes, training frameworks, and scales of training tasks. For more details on the experimental setup and correctness tests, please refer to the full paper.

(2) Storage Performance Test
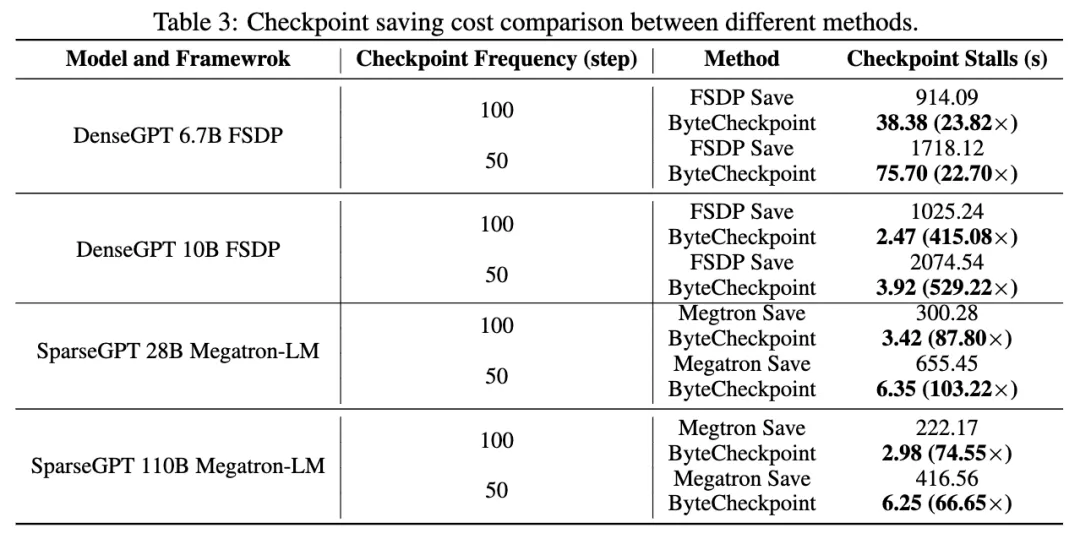
In the storage performance tests, we compared the total checkpoint stalls caused by ByteCheckpoint and baseline methods during training across different model sizes and training frameworks, with checkpoints saved every 50 or 100 steps.
Thanks to deep optimizations in write performance, ByteCheckpoint consistently demonstrated high performance across various experimental scenarios. It achieved a 66.65 to 74.55 times performance improvement over baseline storage methods in the 576-GPU SparseGPT 110B - Megatron-LM training task, and even up to a 529.22 times improvement in the 256-GPU DenseGPT 10B - FSDP training task.
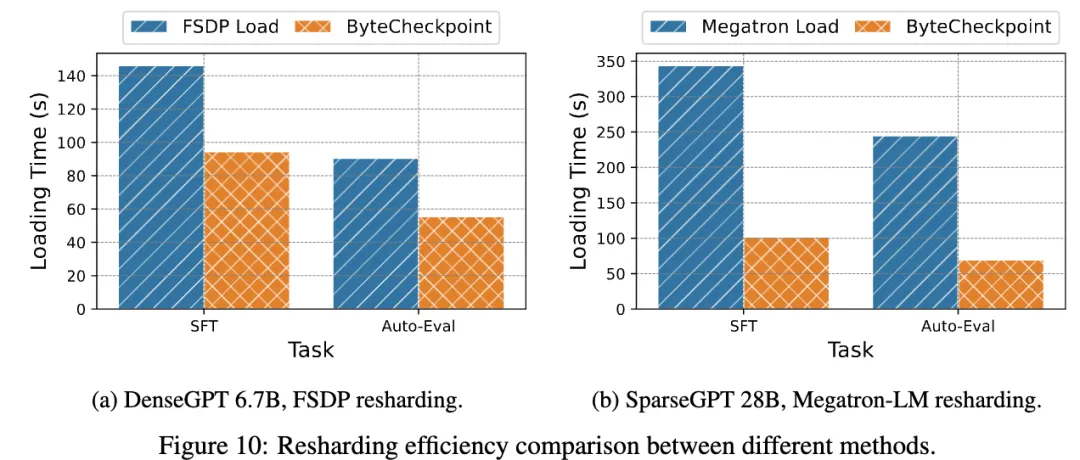
(3) Read Performance Testing
In the read performance tests, the team compared the loading times of checkpoints by different methods based on the parallelism of downstream tasks. ByteCheckpoint achieved a 1.55 to 3.37 times performance improvement over the baseline methods.
The team observed that ByteCheckpoint's performance improvement was more significant compared to the Megatron-LM baseline method. This is because Megatron-LM requires running offline scripts to reshard distributed checkpoints before reading them into a new parallel configuration. In contrast, ByteCheckpoint can automatically reshard checkpoints directly without running offline scripts, efficiently completing the reading process.
Finally, regarding the future plans for ByteCheckpoint, the team aims to focus on two aspects:
Firstly, to achieve the long-term goal of supporting efficient checkpointing for ultra-large-scale GPU cluster training tasks.
Secondly, to realize checkpoint management throughout the entire lifecycle of large model training, supporting all scenarios from pre-training, to supervised fine-tuning (SFT), reinforcement learning (RLHF), and evaluation.
5. The Team's Commitment to Impactful and Technically Challenging Work
ByteCheckpoint was developed through a collaboration between the Doubao Foundation Model team and the University of Hong Kong. From the outset, the team aimed to integrate research with practical application, setting goals to address real-world efficiency issues in LLM training and striving to undertake work that is both impactful and technically challenging.
The first author from the university side is Ray, an intern from the University of Hong Kong, who participated in the development and optimization of the entire system, providing innovative technical insights. The team invited university professors to participate, organized regular discussions, and collaboratively sought solutions to problems encountered during the research process.
Reflecting on this experience, Ray stated, "The Doubao (Seed) Team not only provided ample computational resources for my research but also offered opportunities for me to tackle various issues related to the industrial implementation of large model checkpoint systems."
"In terms of specific work, the team provided thorough technical guidance and inspiration, while also giving me enough freedom to explore innovative solutions," he further added.
The team's atmosphere is characterized by being hardcore, open, and filled with innovation. Currently, the Doubao (Seed) Team is continuously attracting talented individuals. Particularly in the area of pre-training frameworks, the team is looking for individuals with a deep understanding of parallel-related technologies and storage, who are proactive, responsible, and capable of identifying and solving infrastructure problems. They invite such individuals to join and contribute to advancing efficiency in large model training.
Interested candidates are welcome to submit their resumes for more information.
References:
[1] Mohan, Jayashree, Amar Phanishayee, and Vijay Chidambaram. "{CheckFreq}: Frequent,{Fine-Grained}{DNN} Checkpointing." 19th USENIX Conference on File and Storage Technologies (FAST 21). 2021.
[2] Eisenman, Assaf, et al. "{Check-N-Run}: A Checkpointing system for training deep learning recommendation models." 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). 2022.
[3] Wang, Zhuang, et al. "Gemini: Fast failure recovery in 分布式 training with in-memory Checkpoints." Proceedings of the 29th Symposium on Operating Systems Principles. 2023.
[4] Gupta, Tanmaey, et al. "Just-In-Time Checkpointing: Low Cost Error Recovery from Deep Learning Training Failures." Proceedings of the Nineteenth European Conference on Computer Systems. 2024.
[5] Shoeybi, Mohammad, et al. "Megatron-lm: Training multi-billion parameter language models using model parallelism." arXiv preprint arXiv:1909.08053 (2019).
[6] Zhao, Yanli, et al. "Pytorch fsdp: experiences on scaling fully sharded data parallel." arXiv preprint arXiv:2304.11277 (2023).
[7] Rasley, Jeff, et al. "Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[8] Jiang, Ziheng, et al. "{MegaScale}: Scaling large language model training to more than 10,000 {GPUs}." 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024.
[9] veScale: A PyTorch Native LLM Training Framework https://github.com/volcengine/veScale
[10] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.