A Better Performer than CLIP, without Text Encoders? Meet SuperClass, a Pioneering Model by the Doubao (Seed) Team
A Better Performer than CLIP, without Text Encoders? Meet SuperClass, a Pioneering Model by the Doubao (Seed) Team
Date
2024-11-20
Category
Technology Launch
Recently, the ByteDance Doubao (Seed) team unveiled SuperClass, an ultra-simple and efficient pre-training method. For the first time, this method forgoes text encoders and uses the tokens of original texts as multi-class labels directly without additional text filtering, making its training more efficient than CLIP's.
Experimental results showed that SuperClass performs remarkably in a variety of purely visual tasks, as well visual language multimodal downstream tasks, with the same or better scalability as CLIP when it comes to the model and dataset size. This article describes how SuperClass is implemented, its technical highlights, and experimental results.
CLIP is the "eye" of large AI models. By aligning images to text, the model enables understanding and association between images and languages. In recent years, CLIP has been widely used in areas such as visual understanding, image Q&A, and robotics/embodied intelligence.
However, the high requirements of CLIP's own structure on the computational volume also limit its further application and development.
The ByteDance Doubao Vision team recently announced its latest creation, SuperClass. For the first time, the model eliminates text encoders in its pre-training by using only a massive amount of image-to-text datasets, enabling powerful and better-performing visual models without text encoders and the need to build large batch sizes.
Replacing CLIP's contrastive learning approach, SuperClass not only solves the issue of huge computing burden, but also produces visually stunning models. The experimental results showed that SuperClass is superior to CLIP when generating pure visual scenes, as well as vision-language multimodal scenes, and that the model has comparable or even superior scalability to CLIP based on classification methods.

The results of the paper and the code repository have been made public and accepted by NeurIPS 2024.
SuperClass: Classification Done Right for Vision-Language Pre-Training
Link to study: https://arxiv.org/abs/2411.03313
Link to code: https://github.com/x-cls/superclass
1. CLIP limited by high computing volumes
Over the last few years, pre-training methods based on web-scale image-to-text datasets have revolutionized the field of computer vision, especially with Contrastive Language-Image Pre-Training (CLIP) and its series of models gaining increasing attention and becoming the default choice for most current vision-language models (VLMs).
CLIP's widespread use stems from three advantages: Firstly, its superior visual representation capability considerably improved both the accuracy of zero-shot visual recognition and the generalizability of downstream task adaptation. Secondly, CLIP has good scalability and continues to benefit, to some extent, from larger models and the additional data. The third is its powerful cross-modal ability. CLIP was essentially designed to connect text to images.
But despite the success of CLIP, to achieve better performance, the training of models still requires very large batch sizes for contrastive learning and massive amounts of computing resources for text encoding. Such high computational demands limit the application and further development of the technology.
2. First-of-its-kind ultra-simple multi-class classification approach, with no text encoders and decoders
In response to the above problems, the Doubao (Seed) team became the first in the industry to propose a new, ultra-simple multi-class classification method, SuperClass.
With no text encoders and decoders, no additional text filtering and selection, and using only raw text, the team achieved efficient training of a supervised visual model with a potential for further scalability.
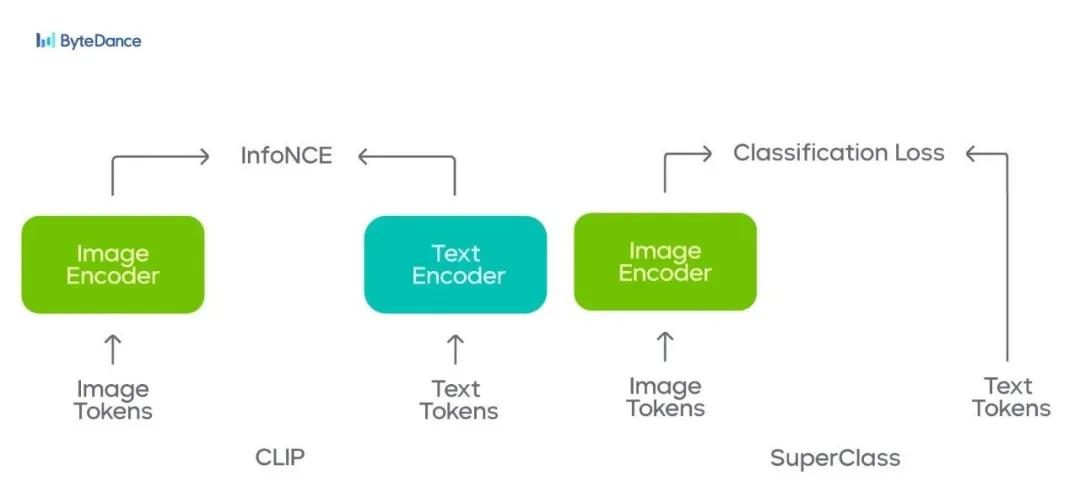
- How it works
We wanted to build a pre-training scheme based on the image classification that is simple, scalable, and efficient while still being as accurate as CLIP. Therefore, we used a vision transformer (ViT) as the backbone network of the visual encoder, connecting it to a global average pooling layer and a linear layer as classification headers.
In terms of training steps, our approach is similar to a typical supervised multi-label classification network: enter an image, extract global features, and obtain the logical vector x\textbf{x}x through the classification layers. Classification labels are derived from the text corresponding to the image, and the classification loss consists of a text-derived classification label and a forecasting vector.
- Mapping text into classification labels
Unlike previous classification-based methods, for an image-to-text dataset containing N pairs of image "I" and text description "T" D={(Ii,Ti) ∣ i∈[1,N]}\mathcal{D} = \left\{ (I_i, T_i)\ |\ i \in \left[1, N\right]\right\}D={(Ii,Ti) ∣ i∈[1,N]}, we directly used an existing subword tokenizer (like that used in CLIP or Bert), with a vocabulary size of VVV, and entered the text TTT to get a corresponding subword ID set C\mathbb{C}C as the classification label.
The tags in the set C\mathbb{C}C satisfyc∈[1,V]{c \in \left[1, V\right]}c∈[1,V]. The classification label C\mathbb{C}C will be converted into an N-hot vector y∈RV\textbf{y} \in \mathbb{R}^Vy∈RV , where when ccc is in the set C\mathbb{C}C, yc=1y_c=1yc=1, otherwise yc=0y_c=0yc=0.
Compared to previous classification-based pre-training methods, our approach does not require any pre-processing or manual threshold setting, while avoiding out-of-vocabulary problems as encountered by the previous methods.
- Classification loss functions
Numerous studies have explored multi-label classification loss functions. However, it is worth noting that our goal was to pre-train visual encoders rather than focusing on multi-label classification accuracy. Therefore, we performed ablation studies on several multi-label classification losses, including Softmax loss, BCE loss, soft margin loss, ASL, and two-way loss.
Surprisingly, simple Softmax losses produced the best pre-training results. This may be because current multi-label classification losses are based on the assumption that labels are accurate and complete, striving to optimize the spacing between positive and negative classes. However, inherent noise in image-to-text data, and the limitations of text in fully describing image content mean that all objects in an image are not always mentioned in the paired text.
In a multi-label scenario, Softmax losses are applied by describing the label probabilistically, where y^c\hat{y}_cy^c is the normalized weighted label.
ℓce=−∑c=1Vy^clogexc∑c′exc′\begin{equation} \ell{ce} = -\sum_{c=1}^{V}\hat{y}c \log\frac{e^{x_c}}{\sum{c'}e^{x_{c'}}} \end{equation}ℓce=−c=1∑Vy^clog∑c′exc′exc
- Inverse document frequency as class weight
In a subword vocabulary, each word carries a different amount of information, and different categories are not equally important. Also, given that a subword dictionary contains many common words of sentences, these words are not relevant to visual content and do not provide effective information for supervision.
Therefore, the team believed that words carrying a great amount of information should be given more weight during training. We measured the amount of information using Inverse Document Frequency (IDF). The fewer the samples containing a particular word in an IDF, the stronger the word's ability to distinguish between different samples.
We use the IDF statistics for categories (subwords) as weights for classification labels, assigning different weightscccto the classification labelswcw_cwc:
y^c=wcyc∑c′wc′yc′,wc=log(∣D∣1+df(c))\begin{equation}\begin{aligned}\hat{y}_c &= \frac{w_cy_c}{\sum_{c'}w_{c'}y_{c'}}, &w_c &= \log\left(\frac{|\mathcal{D}|}{1+\text{df}(c)}\right)\end{aligned}\end{equation}y^c=∑c′wc′yc′wcyc,wc=log(1+df(c)∣D∣)
where∣D∣|\mathcal{D}|∣D∣is the total number of image-to-text pairs anddf(c)\text{df}(c)df(c)is the document frequency (DF) of the subwordccc, which is the number of texts containing the subwordccc. For easier use, we implemented online IDF statistics during training to remove the need for offline statistics before training. This makes SuperClass more user-friendly and easier to import/export.
3. SuperClass is not only simple and efficient, but also learns better visual representations
By eliminating the need for text encoders and building huge similarity matrices, SuperClass can save about 50% of memory usage with an acceleration of more than 20%.
To better measure its visual representation ability obtained from pre-training, we fixed the parameters of the trained visual model, applied them to classification tasks such as linear probing, zero-shot and 10-shot learning, and connected them to an LLM for evaluation of vision and language multi-modal downstream tasks.
In all experiments, we used the same model and training parameter settings as in CLIP.
- Better visual representations
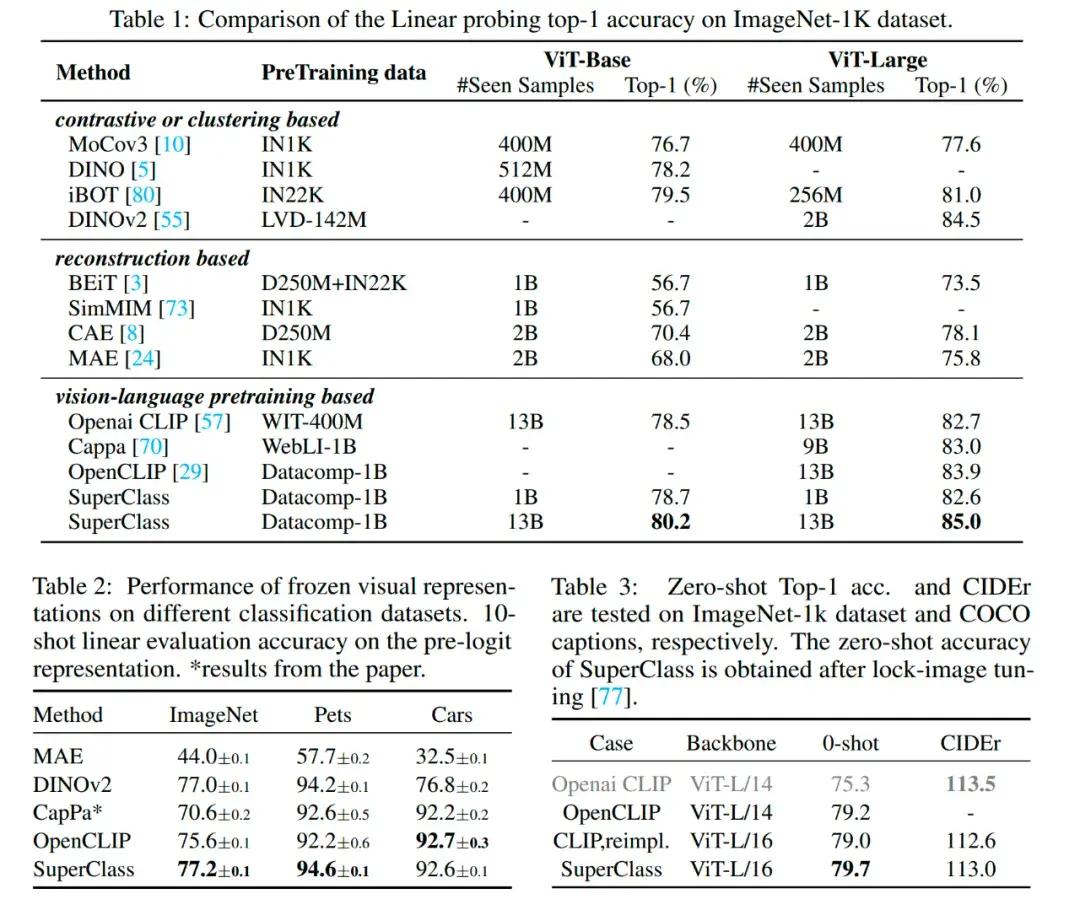
The results showed that SuperClass achieved good accuracy across a wide range of model and data sizes. Unlike other unsupervised methods, SuperClass relies on semantic information as a supervised source, resulting in a diverse set of training data, with better accuracy across a wide range of image classification datasets and different classification tasks.
Using the same set of training parameters, SuperClass is also far more accurate in image classification than CLIP models, such as ImageNet linear probing classification, with SuperClass's accuracy being 1.1% higher than CLIP's (85.0 vs. 83.9). Without the need for text encoders and massive batch sizes, SuperClass is ideal for large model pre-training scenarios.
- Superior cross-modal capabilities
Another scenario in which CLIP is widely used is multimodal understanding, where it demonstrates good cross-modal capabilities as a visual encoder in a multimodal large model. During the pre-training process, SuperClass features are also aligned to text spaces, rendering them applicable to multimodal understanding tasks.
In this article, we used two large language models to evaluate image captioning ability on COCO captions using GPT-2 as the decoder based on the settings in clipcap. As shown in Table 3, SuperClass achieved slightly better CIDEr results than CLIP.
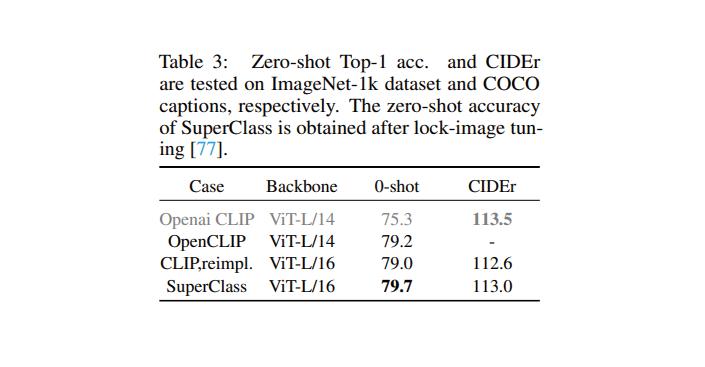
In addition, we also evaluated more multimodal downstream tasks using 7B LLMs based on LLaVA settings, where SuperClass again delivered better accuracy.

For more experimental configurations and test details, please refer to the full paper (https://arxiv.org/abs/2411.03313).
- Greater scalability
The team compared the accuracy of SuperClass and CLIP at different model sizes and data scales, even for purely visual tasks and multimodal downstream tasks:
- SuperClass and CLIP have similar scalability for both types of tasks.
- In the Text-VQA task, SuperClass clearly achieved better accuracy and scalability than CLIP, which led the team to conclusion that SuperClass can be trained to learn more OCR capabilities.

4. Looking to the future
The team will continue to advance the image-text pre-training technology and train stronger visual models based on text sequence information, to better serve visual and multimodal related tasks. Interested in the team's research and exploring the frontiers of the large visual models? Visit our careers page to find out more about the job positions available.