Doubao's "Listening" skills unboxing live! See how Seed-ASR overcomes the speech recognition bottleneck
Doubao's "Listening" skills unboxing live! See how Seed-ASR overcomes the speech recognition bottleneck
Date
2024-08-22
Category
Tech
The 2024 Volcano Engine AI Innovation Tour recently took place in Shanghai. It showcased improvements in comprehensive scoring and speech recognition by the Doubao LLM and launched a conversational AI real-time interaction solution. The Doubao (Seed) Team has developed the Seed-ASR, which provides speech recognition capabilities.
Seed-ASR is an Automatic Speech Recognition (ASR) product. It accurately transcribes various speech signals, recognizing different languages, dialects, and accents. For people's names and new words, Seed-ASR can also combine text, speech, and other contexts to achieve more accurate transcription. It has been integrated into the Doubao App and Volcano Engine-related service modules.
This article highlights the features of Seed-ASR technology — high recognition accuracy, large model capacity, multiple language support, context-aware ability, and stage-wise training recipe. Team members also share the motivation for initiating the project, research and development processes, and their summaries and reflections, while looking forward to the impact and influence of Scaling Laws on speech recognition technology.
On August 21, the 2024 Volcano Engine AI Innovation Tour at the Shanghai station showcased the latest advancements in the Doubao large language model.
Public and internal assessments show that the latest version of the Doubao large language model has improved overall capabilities by 20.3% compared to the version released on May 15, with role-playing ability increasing by 38.3%, language comprehension by 33.3%, and mathematical ability by 13.5%. According to the QuestMobile report, Doubao, the app powered by Doubao large language model, has reached 27.52 million MAU in the first half of the year, ranking first among similar apps and 2.43 times larger than the second-place app.
Speech capability has been a key focus of this event. Among them, the speech recognition and speech synthesis models have been further upgraded, and the conversational AI real-time interaction feature has also been newly launched.
Specifically, the Doubao speech synthesis model has upgraded its streaming speech synthesis capability, enabling real-time response, accurate pauses, and support for "think-and-speak" functionality. The Doubao speech recognition model, with enhanced context awareness, delivers more accurate recognition results and supports recognition of Mandarin and various Chinese dialects like Cantonese, Shanghainese, Sichuanese, Xi’an, and Min Nan.
Based on achievements like speech synthesis and speech recognition, the Volcano Engine has integrated real-time audio & video technology of cloud service, enabling AI voice interaction to interrupt and interject like in human conversation, with an end-to-end latency as low as under 1 second. Even in poor network environments, with 80% packet loss, clarity and smoothness can still be maintained.
In the release above, the speech synthesis capability is powered by Seed-TTS. The speech recognition capability is powered by Seed-ASR, another achievement of the Doubao (Seed) Team.
1. Showcase of Seed-ASR Capabilities
Seed-ASR, powered by the large language model, can convert various types of speech into text information, enabling machines to "understand" human speech and "intelligently" recognize various types of information.
Experience its capabilities through the following demos.
(1) Contextual inference based on people's names
The model can recognize relevant information from speech with some historical figure introductions.
(2) Contextual inference based on terminologies
The model can automatically recognize terminologies in subsequent speech based on the user's subtitle editing history, such as "edging," "snowboard," and "skidding" in skiing.
(3) Dialect Recognition
Even in a voice chat featuring five different dialects, the model can still recognize and display relatively accurate results. If chat-related information is provided as prompts to the model beforehand, the recognition effect will be further improved.
Seed-ASR has been implemented in the Doubao app and used by netizens in various scenarios, such as English conversations, virtual chat companions, and replicating the voices of relatives and friends. Seed-ASR, powered by Volcano Engine, is deployed in scenarios such as voice interaction, content moderation, meeting transcription, and audio & video subtitles for a broader range of corporate clients.
Currently, the Seed-ASR technical report has been published, showing significant improvements over other end-to-end models across multiple domains, languages, dialects, and accents in comprehensive evaluation sets.
Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
For technical details and more demo shows, see the links below:
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Demo show: https://bytedancespeech.github.io/seedasr_tech_report/
2. Technical Highlights and Principles
The Seed-ASR project was initiated at the beginning of 2023. As ChatGPT emerged and Scaling Laws became prominent, researchers from various fields realized that significant increases in the number of parameters and data volume could empower models with robust understanding and generative capabilities.
Previously, speech has been closely integrated with NLP. The mutual conversion of speech and text is a task that is “instinctively performed” in the human brain, similar for machines as well.
Against this backdrop, the research team aimed to enhance the accuracy of ASR outcomes by leveraging the extensive knowledge from LLM, thus commencing the related work on Seed-ASR.
From a technical standpoint, the core highlights of Seed-ASR are twofold:
Firstly, based on the large language model, it introduces contextual understanding capabilities for ASR.
Seed-ASR, powered by LLM, can utilize a rich context to understand speech signals. Specifically, by creating effective and diverse training data, the team has activated the model's audio modality, allowing it to integrate with text and capture relevant information from speech. Furthermore, in the inference process, some decoding strategies are designed to alleviate the hallucinations and transcription errors introduced by context.
The above work allows the model to understand specific terminology when conversing with AI, and to "understand" the names of new participants in meeting minutes. The more communication occurs and the more contextual information is accumulated, the higher the transcription accuracy becomes over time.
Secondly, the All-in-One concept brings powerful generalization capabilities.
Traditional ASR systems are small models, with each domain requiring specific models to address niche problems. These systems also depend on tailored integration methods, and their performance degrades outside of specific scenarios. In contrast, Seed-ASR, built on the All-in-One concept, offers strong generalization capabilities, making it suitable for a wide range of scenarios with a more streamlined approach.
Beyond these aspects, Seed-ASR also boasts high recognition accuracy and support for multiple languages. The Chinese version supports 13 Chinese dialects, while the multilingual version supports English and seven other languages, with plans to expand to 40 languages.
These capabilities, particularly high-accuracy recognition and multilingual support, stem from the Scaling Laws principle. As model capacity increases and more diverse and extensive data are incorporated, the model achieves better generalization and emergent capabilities—similar to the evolution seen in the GPT series. Furthermore, the staged training approach endows the model with not only high-precision recognition abilities but also contextual reasoning capabilities.
3. Training Methodology
The development of Seed-ASR incorporates a staged training process, utilizing an audio-conditioned LLM framework referred to as AcLLM.
The process includes the following stages: Self-Supervised Learning (SSL) for the encoder, Supervised Fine-Tuning (SFT), Context Fine-Tuning (Context SFT), and Reinforcement Learning (RL). During pre-training, the model is trained on a large corpus of text data, enabling it to store extensive knowledge. In subsequent fine-tuning, the LLM is further refined using higher-quality, task-oriented datasets, which enhance its abilities in contextual reasoning and understanding task instructions. In the Reinforcement Learning with Human Feedback (RLHF) stage, the LLM is aligned more closely with human preferences, ensuring its responses and behaviors are better suited to human needs.

Note: Seed-ASR Training Process
Detailed Breakdown of Each Stage:
- Self-Supervised Learning of the Audio Encoder
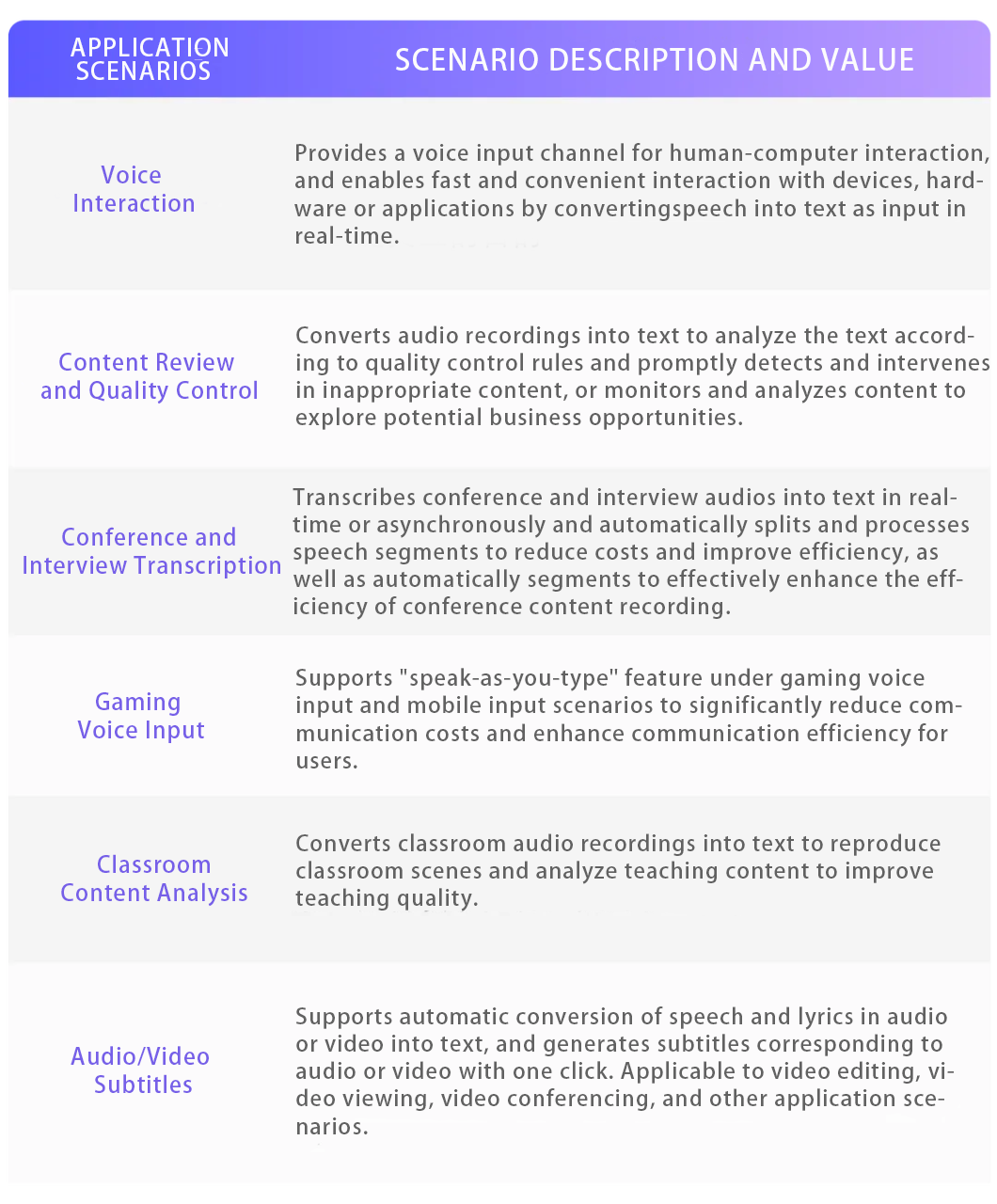
This step enables the encoder to capture rich information from speech. Inspired by the BERT-based speech SSL framework, the team developed a consistency-based model capable of capturing and storing both global and local information in audio signals. The trained audio is encoded into what the team calls LUISE, which stands for Large-scale Unsupervised Iterative Speech Encoder.
Inheriting the principles of BERT, LUISE adopts the masked language prediction learning paradigm. Specifically: Features are first extracted from the audio waveform and input into a tokenization module, producing discrete labels for each frame.The model is then trained using a cross-entropy objective function, where the loss is computed only for masked frames. After training, the softmax layer is removed, and the encoder component of LUISE is used for subsequent supervised fine-tuning.
Below is the training process for this encoder:
The team also employed an iterative fixed tokenizer method to extract discrete labels from continuous data, progressively optimizing the tokenization results through repeated iterations.
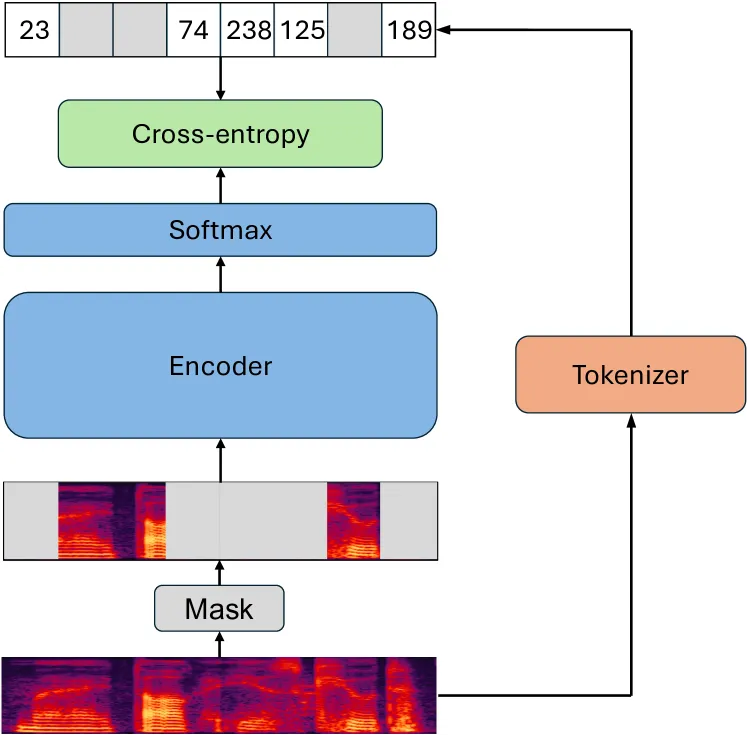
During the selection of intermediate layers, the team froze the encoder parameters from the first iteration of training, added a mapping layer, and used the Connectionist Temporal Classification (CTC) algorithm for greedy search to obtain the Word Error Rate (WER) results.
The figure below illustrates the experimental results of optimizing the semantic representation layer for LUISE. For the 2-billion-parameter LUISE model, the output from the 25th layer (out of a total of 30 layers) demonstrated the best semantic representation. In subsequent iterations, this layer was used to generate discrete labels.
- SFT
Large-scale training on pure speech data has endowed LUISE with powerful speech representation capabilities, enabling it to output rich speech and semantic information as continuous representations at a 40ms frame rate.
To allow the model to understand the corresponding textual content in speech, it is necessary to map the semantic information encoded by LUISE into the semantic space of the LLM. The team adopted two methods to achieve this:
Model Architecture: A transformer module was introduced to connect the audio encoder LUISE with the LLM. When context is provided, the model identifies relevant speech information and, combined with the context, produces accurate text. Otherwise, it directly transcribes the speech into text.
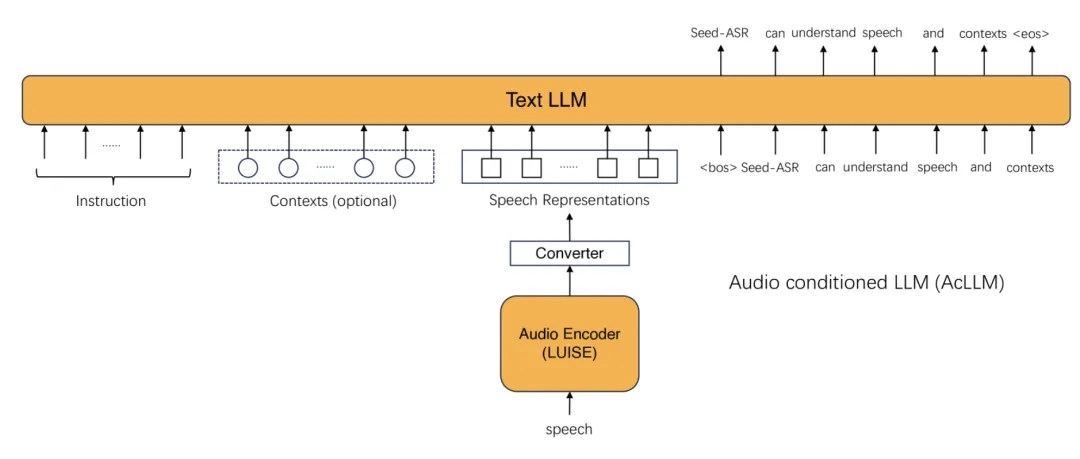
Regarding training approaches, the team implemented a strategy involving a "trainable encoder + trainable transformer + fixed LLM". This method preserves LLM's extensive semantic knowledge and inferential capabilities. Training the encoder and transformer parameters aligns the semantic information in speech with the LLM's semantic framework.
- Context SFT
Context SFT (Supervised Fine-Tuning) is not only about understanding background information in speech-based conversations but also plays a significant role in addressing ambiguous elements in speech recognition, such as accents, unclear pronunciation, homophones, and uncommon words. To enhance these capabilities, the team introduced context-aware training and a joint beam search method.
Context-Aware Training: The team used a self-developed language model to generate context related to speech transcriptions and constructed a dataset containing three elements: context, speech, and text. This dataset was mixed with general ASR data in specific proportions for training. During training, both context and speech representations were fed into the LLM.
Joint Beam Search Decoding: To address the hallucination issues often seen in traditional beam search, the team proposed a joint beam search decoding strategy to mitigate hallucinations and find the optimal score P(y∣x,c)P(y∣x,c)P(y∣x,c), where: yyy represents the predicted hypothesis, xxx represents the speech information, ccc represents the given context information. A hyperparameter ααα was introduced to balance the weight of speech information and context information during decoding. Additionally, the team implemented a pruning strategy to filter out semantically unreasonable candidate words, further improving decoding accuracy.
Pjoint(y∣x,c)=a1+a∗P(y∣x,c)+11+a∗P(y∣x)P_{joint}(y|x,c)=\frac{a}{1+a}*P(y|x,c)+\frac{1}{1+a}*P(y|x)Pjoint(y∣x,c)=1+aa∗P(y∣x,c)+1+a1∗P(y∣x)
The figure below illustrates examples of speech transcription with and without context. As seen in the output of the second row, in the context-aware case, the model aligns its output with previously occurring words such as "ceaseth" and "sufficeth."

- RL
The introduction of Reinforcement Learning (RL) enables the model to learn relatively optimal decision-making strategies for sequence modeling tasks. The team introduced RL into Seed-ASR by constructing a reward function based on ASR metrics. Moreover, the team also uses the weighted word error rate (WER) as an additional reward function to make the model pay more attention to the errors of keywords.
Specifically, during the training process, the team initializes the model parameters using the context SFT from the previous phase of training and conducts thousands of hours of reinforcement learning training using high-quality data to ensure contextual awareness. The training data also includes a certain proportion of triplet data, namely "context, speech, and text" .
In the ablation study, the model that uses the weighted WER as a reward function (last two rows) performed excellently across three evaluation sets, and the final row of training was further enhanced by adding a dataset of three elements to maintain contextual capabilities.
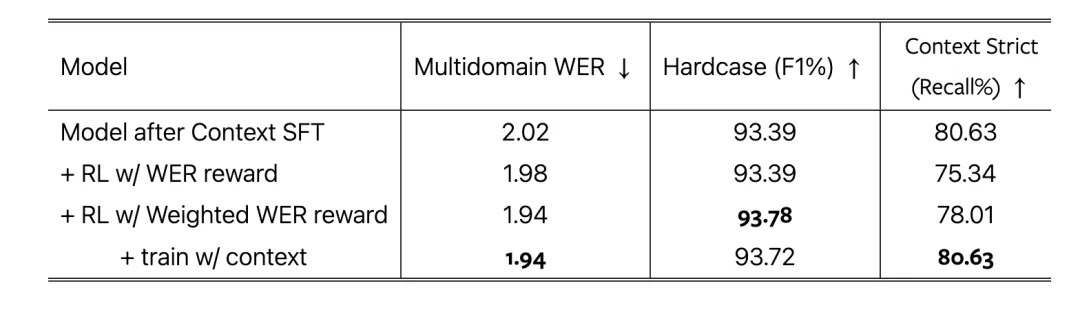
4. Experimental Results and Technological Outlook
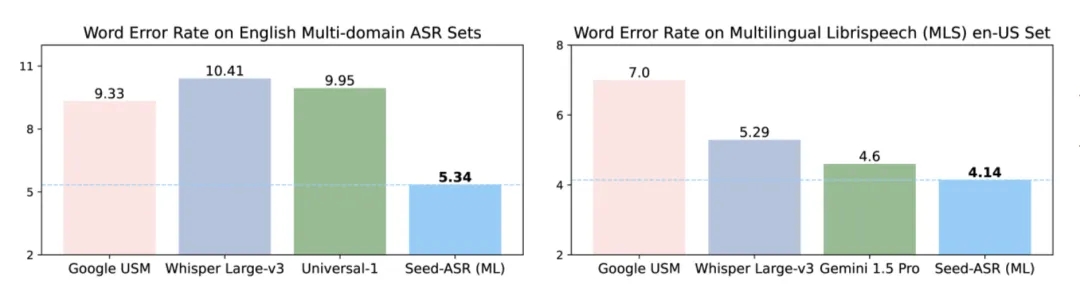
The figure below shows the average word error rate of Seed-ASR compared to other similar models in the Chinese domain. For both the general Mandarin recognition error rate across multiple domains and the six Mandarin test sets, Seed-ASR maintains a lower average error rate than other models.

The performance is also excellent for English, both in multi-domain English recognition evaluations and in the MLS public test datasets, showing outstanding results.
Beyond objective evaluations, the team also introduced subjective evaluations, selecting three transcriptionists to conduct manual recognition and compare the texts with Seed-ASR.
The results show that in the fields of voice search and voice assistants, the two are comparable; whereas in LIVE, video, and conference scenarios, Seed-ASR (CN version) demonstrates better subjective intelligibility than humans.

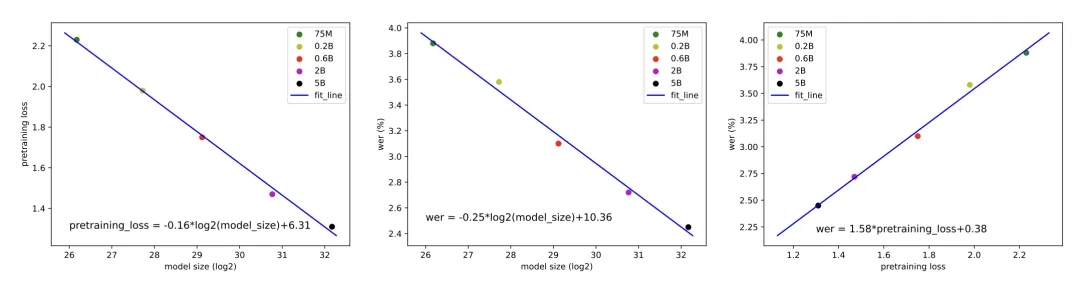
Throughout the research testing process, the team also observed that larger models could continually reduce loss values by increasing the scale of training data.
According to the team, there is no research on audio encoder Scaling Laws based on the LLM framework. The team selected models of five magnitudes during the training phase and trained them using 7.7 million hours of unsupervised multi-domain pure Audio data to observe Loss values and Word Error Rates (WER).
As shown in the figure below, as the model size increases (taking logarithm base 2 on the horizontal axis), both cross entropy pre-training loss value and error rate decrease, and there is a positive correlation between pre-training loss and error rate.
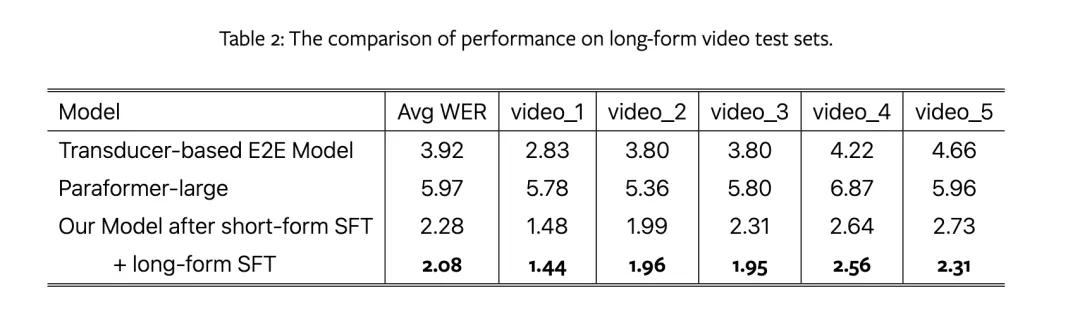
To explore the impact of long audio data on the model surface, the team also built a series of datasets, using long audio data directly for fine-tuning, while the control group used segmented short audio for fine-tuning, and compared them with other ASR models.
The results show that long audio SFT performs better. The team believes that segmentation may lead to the loss of boundary information, reducing recognition accuracy, and affecting the consistency of global context, thereby reducing the accuracy and consistency of recognition results.
Lin is one of the main participants in the project. Looking forward to the potential unleashed by Seed-ASR, he believes that further improvements in accuracy of audio content understanding as an entry point will make user interaction more "intelligent." ASR's enhanced compatibility with minority languages, accents, and pronunciations can further democratize technology for culturally diverse or communication-impaired minority groups.
On the prospect of technological development, Lin is quite optimistic: "The potential of Scaling Laws has not yet been exhausted, and we still see considerable benefits from the upgrades in data and model structures, and we will continue to explore."
5. "Pragmatic" and "focusing on technology" define the team's core values.
In fact, Seed-ASR has already been implemented in the real-world scenario of the Doubao APP, progressing from project initiation to public launch in less than half a year. The model has continuously improved in performance through ongoing optimizations.
"The project is progressing efficiently," this is what left the deepest impression on Lin.
He recalled that the rapid progress was partly attributed to the forward-thinking choice of the technical approach. The framework of Seed-ASR has great continuity; it initially opted for continuous speech representation, and has maintained this focus, allowing the team to avoid detours and conduct further in-depth research and optimization.
On the other hand, it also originated from efficient cross-functional collaboration.
In this process, algorithm team members initiated preliminary validation and technical direction planning, and as the model demonstrated corresponding capabilities, more teams joined in. Among them, the engineering team provided support in training reliability and inference acceleration, the data team quickly supported feature production, and evaluation team members constructed a hexagonal set of evaluation dimensions. The leaders stay actively involved on the front lines, closely monitoring cutting-edge work and technological progress. They maintain close communication with team members across functions on technical details to better coordinate resources and guide project advancement. With everyone's close cooperation, the model was rapidly iterated.
"Everyone was so focused on optimizing actual effects that they did not have time to test on public sets, which resulted in the delay of the technological report," Lin added.
Ultimately, the team’s collaborative atmosphere is also a key factor driving the project’s efficient progress.
"The keywords for our team are pragmatic and a strong emphasis on technology," said Lin. It is this atmosphere that motivates everyone to be more self-driven and proactive in advancing the project.
"Every team member has the opportunity to engage in activities that suit them and gain a sense of achievement. Seeing the technology implemented and unlocking value, as well as providing new perspectives to peers, gives us the motivation to refine our technological skills," he added earnestly.
As of now, the Doubao (Seed) team has released multiple technological outcomes in the field of voice technology, such as Seed-TTS and Seed-ASR. The team hopes to attract self-driven, pragmatic top talents who aspire to "use technology to change the world," and it welcomes their applications.
Note: The team member interviewed for this article used a pseudonym.