Doubao (Seed) Team Launched SuperGPQA— an Open-source Benchmark Test Set Covering 285 Disciplines
Doubao (Seed) Team Launched SuperGPQA— an Open-source Benchmark Test Set Covering 285 Disciplines
Date
2025-03-04
Category
Technology Launch
Recently, the Doubao (Seed) team presented SuperGPQA, an open-source comprehensive and highly differentiated knowledge inference benchmark.
The dataset constructed an evaluation system covering 285 graduate-level disciplines and 26,529 professional questions. It encompasses not only mainstream disciplines but also long-tail fields such as light industry, agriculture and service science, showing a comprehensive range of disciplines and filling the gap in long-tail knowledge evaluation.
Today, SuperGPQA has been used to uncover significant performance gaps between open-source models and closed-source solutions, providing key assessment tools and interdisciplinary analysis frameworks for AI development.
As the performance of large language models (LLMs) in general disciplines approaches human level, the focus of research has shifted to their application in real-world professional domains. However, when it comes to long-tail disciplines in the field of human research, the boundaries of LLMs' capabilities remain unclear due to inadequate evaluation.
To comprehensively measure LLMs' abilities to generalize and the upper limit of their inference capabilities, the ByteDance Doubao (Seed) team, in conjunction with the M-A-P open source community, launched SuperGPQA, a benchmark that not only covers more than 200 graduate-level subjects, but also ensures that 42.33% of the questions require mathematical calculation or formal reasoning, creating a new paradigm of evaluation that combines broad subject coverage with complex problem design.
The experimental results show that the accuracy rate of DeepSeek-R1 on SuperGPQA is 61.82%, and the performance of current LLMs in different fields of knowledge still has significant room for improvement, which highlights the importance and necessity of SuperGPQA in evaluating the true abilities of models.

At present, the research results and data code repository have been publicly released for open-source usage.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Link to study: https://arxiv.org/pdf/2502.14739
Link to data: https://huggingface.co/datasets/m-a-p/SuperGPQA
Link to code: https://github.com/SuperGPQA/SuperGPQA
1. Inadequate Coverage of Disciplines in Existing Benchmarks, Less than 5% of Long-tail Disciplines Covered
The existing LLM evaluation system faces two core challenges: a severe lack of discipline coverage and the failure of benchmarks as challenging frontiers.
The traditional benchmarks, represented by MMLU and GPQA, encompass less than 50 disciplines and represent only the tip of the iceberg of human knowledge, despite having established standardized testing frameworks in mainstream domains such as mathematics and physics. According to statistics, existing benchmarks cover even less than 5% of long-tail disciplines such as light industry, agriculture, and service-oriented fields.

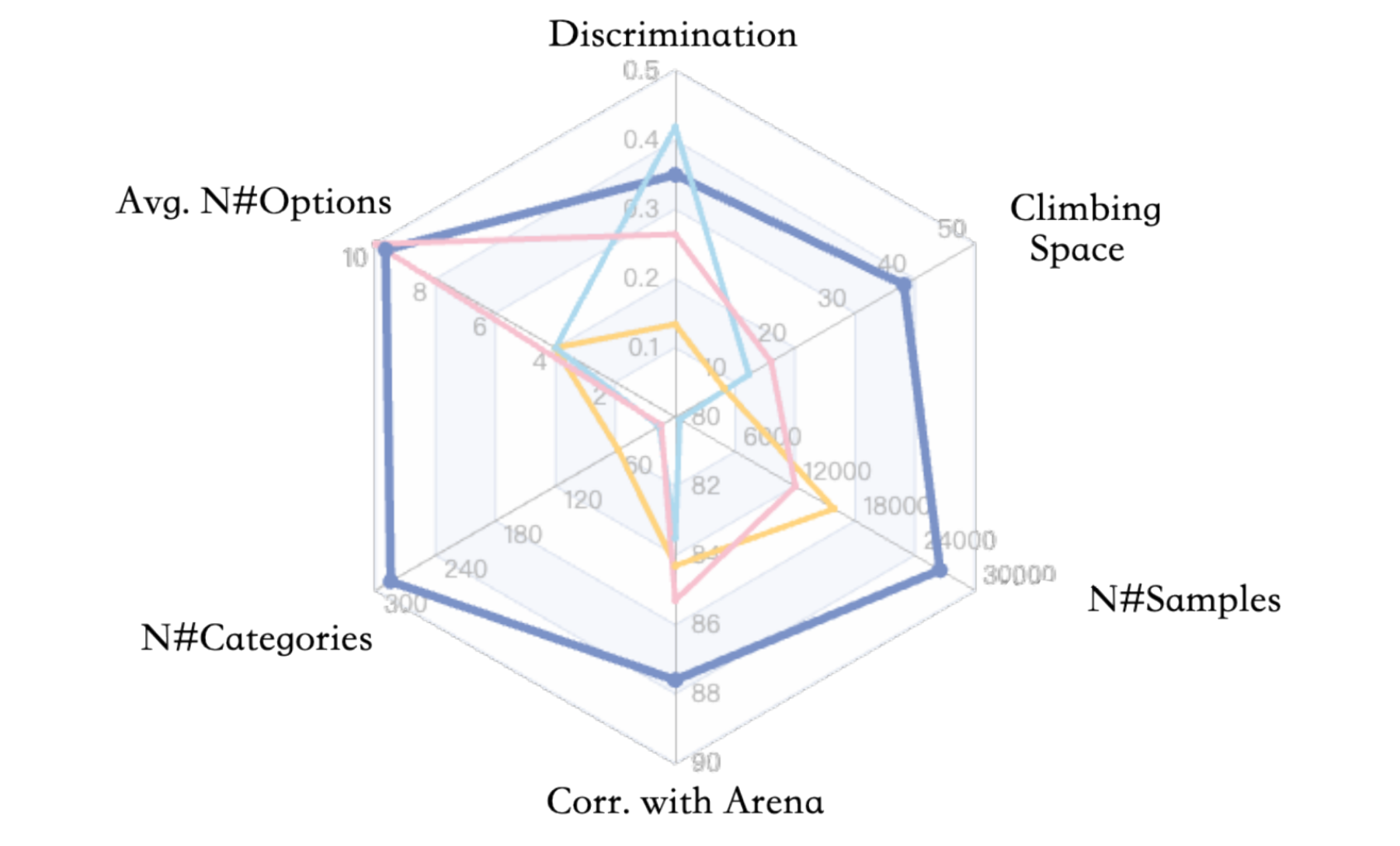
Radar chart of benchmark comparison across dimensions
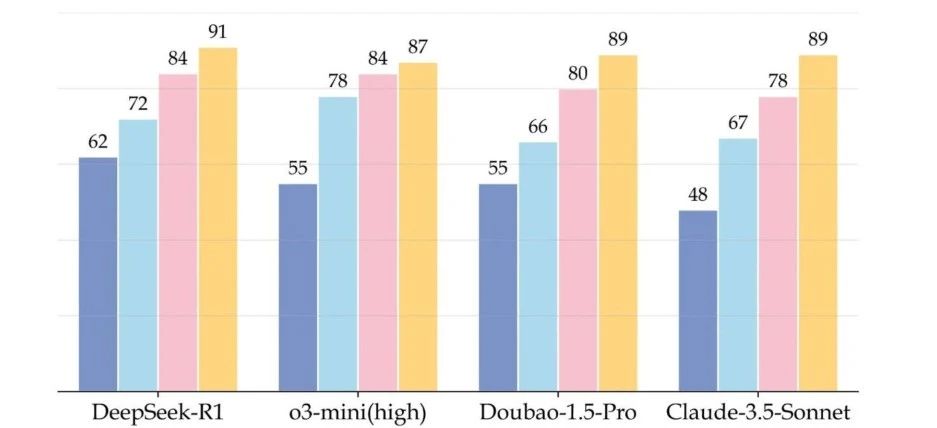
Performance comparison of SOTA models across different benchmarks
The greater challenge is that the current measurement systems are unable to effectively discriminate and measure the upper limit of a model's inference capacity in real-world, complex scenarios. For example, mainstream models such as GPT-4o and DeepSeek-R1 have surpassed 90% in accuracy on traditional benchmarks.
This is mainly due to the singular data sources and unrefined quality screening of traditional benchmarking paradigms. For example, an indiscriminate reliance on textbook examples or online question banks (e.g., 42% of GPQA questions came from Wikipedia) led to questions that lack professional depth and are easily “cracked” by models through memory mechanisms. The experiment found that GPT-4o had a 67.3% repeat rate of answers to online exercise websites, suggesting that its performance improvement could be due to data leakage rather than real inference.
In addition, the unreliability of benchmarks is further compounded by the varying level of expertise and the difficulty of subjective question evaluation in crowd-sourcing annotation. In early attempts, only 37% of crowd-sourced annotated questions passed expert review, resulting in a more than 60% waste of labeling resources.
This prevents us from accurately assessing the generalization and inference capabilities of models, which seriously hinders further improvement of model performance.
2. Full Coverage of 285 Disciplines for the First Time, Exploring the Boundaries of LLMs' True Abilities
To overcome these limitations, the Doubao (Seed) team and M-A-P introduced SuperGPQA, a comprehensive benchmark covering 285 graduate-level disciplines, to explore the boundaries of the potentials of SOTA LLMs.
- Comprehensive subject coverage: SuperGPQA spans 13 disciplines, 72 fields, and 285 subfields with a total of 26,529 questions, far exceeding the existing GPQA (448 questions) and MMLU-Pro (12,032 questions). It also provides an average of 9.67 options per question, which is significantly more challenging than the conventional 4-option format. At the same time, it goes beyond the limitations of the traditional review set to focus only on STEM disciplines, and combines STEM disciplines such as science, engineering, and medicine with non-STEM domains such as philosophy, literature, and history, with a high degree of discrimination.
- Diverse difficulty distribution: The difficulties of questions are evenly distributed across disciplines, especially in engineering and science where there are a higher proportion of difficult questions. 42.33% of the questions require mathematical computation or rigorous inference to ensure a model's performance in difficult tasks.
- Rich semantic structure: Through t-SNE visualization, the SuperGPQAevaluation set shows a clustering pattern across disciplines, with engineering and science questions highly semantically similar, while the humanities remain distinct centers of knowledge, reflecting domain-specific linguistic features.
- Consistent question design: The average question length is 58.42 words. The consistent length of the options increases confusion and challenge, ensuring the fairness and reliability of the evaluation.
3. Expert-LLM Collaboration to Improve Question Bank Quality
SuperGPQA's core architecture consists of three key phases: Source Screening, Transcription, and Quality Inspection. The process involves more than 80 expert annotators, interactive expert-LLM collaborative systems, and provides methodological guidance for future research projects of similar scale.
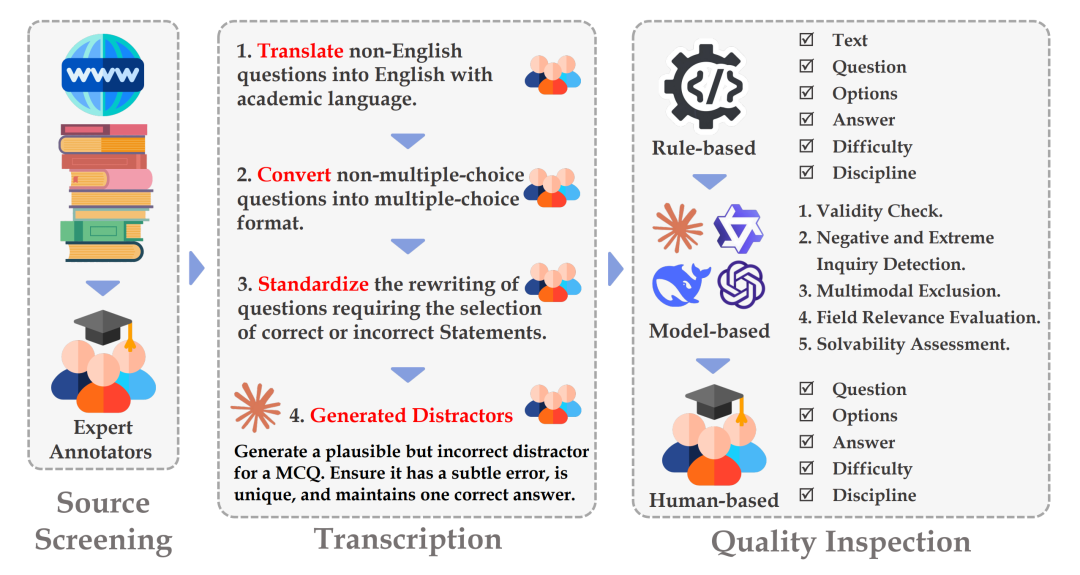
SuperGPQA Data Collection Process Flow
- Source Screening
To ensure a high standard of quality, instead of relying on crowd-sourcing annotators to gather resources, the team entrust expert annotators to screen and gather original questions from trusted sources (such as textbooks and authoritative exercise websites) and require them to provide source screenshots. This strategy avoids the early generation of numerous invalid questions, improving the efficiency and accuracy of quality inspection.
- Transcription
During the transcription phase, expert annotators linguistically normalize and format the collected raw questions, ensuring that all questions have a uniform academic language and standard multiple-choice format. The team found that even the LLMs had vulnerabilities when generating distractions, therefore they needed to be rewritten uniformly by experts to improve the accuracy and validity of the distractions and ensure that the questions were challenging and differentiated.
- Quality Inspection
The team uses a three-tier inspection mechanism during the quality inspection phase to ensure the overall quality of the dataset:
1) Rule-based Preliminary Filtering: Identifies and filters items that clearly do not match the format.
2) LLM-based Quality Inspection: Utilizes several advanced LLMs such as GPT-4 and Gemini-flash for validity checks, negative and extreme inquiry detection, multimodal exclusion, field relevance evaluation, and discrimination tagging. Multimodal collaboration increases efficiency and reduces the risk of data leakage.
3) Expert Review: Expert annotators perform a second review of suspicious questions to ensure high reliability and discrimination of the final question bank.
4. Most Advanced Models Still Have Room for Improvement
While releasing the benchmark, the research team also evaluated six inference models, 28 chat models and 17 basic models worldwide based on SuperGPQA, covering closed-source, open-source and fully open-source models.
Among them, the inference models and the chat models were evaluated with zero samples, the base models were evaluated with five samples (a similar approach to MMLU-Pro), and the temperature parameter was set to 0. The maximum number of tokens is set to 32K for inference models, and 4K for other models.
Our experimental results show that the performance of SOTA LLMs in different knowledge domains still has substantial room for improvement. For example, the current most advanced model DeepSeek-R1 is only 61.82% accurate on SuperGPQA. The specific evaluation results are shown in the figure below:
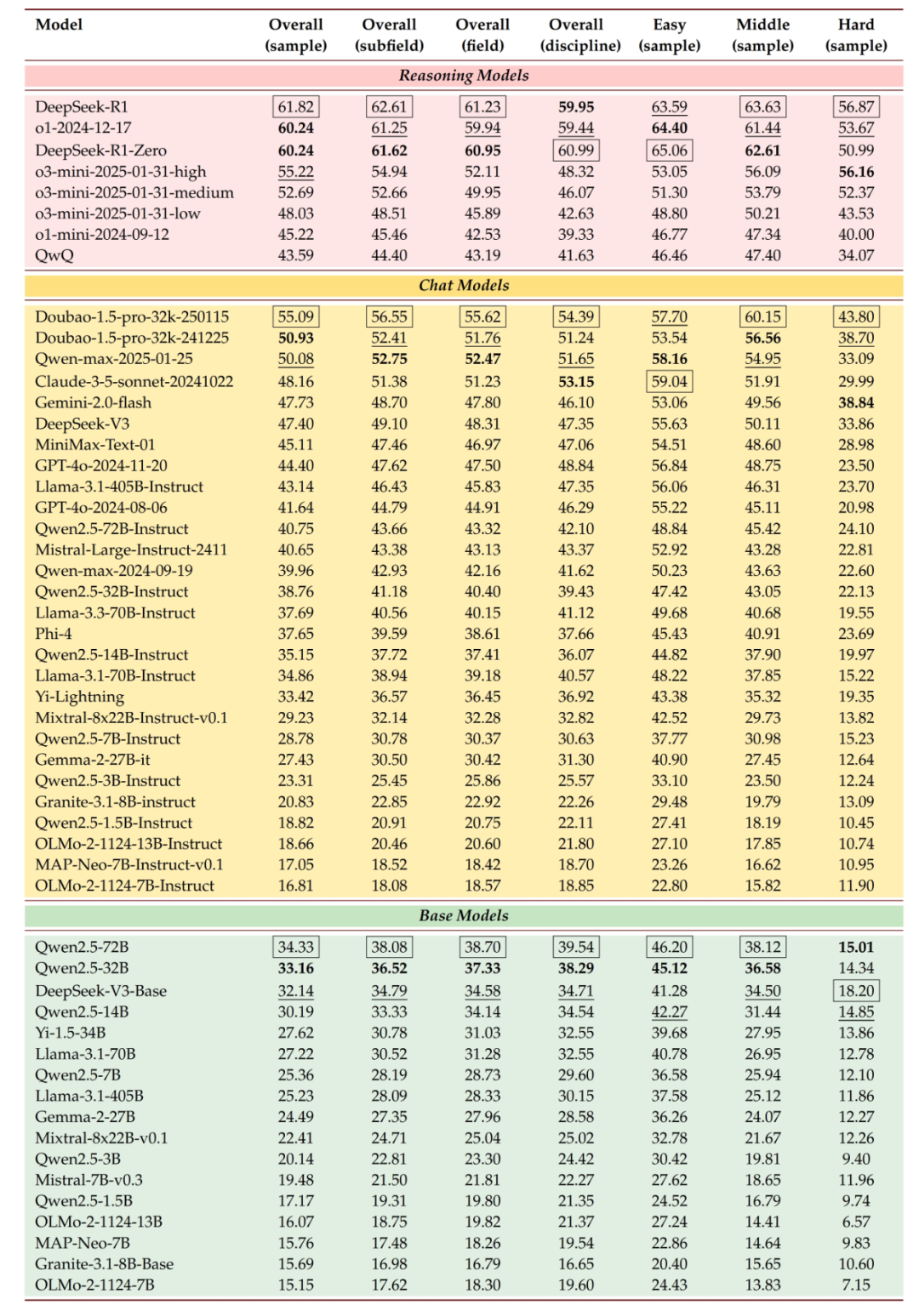
Performance of LLMs at different levels of segmentation
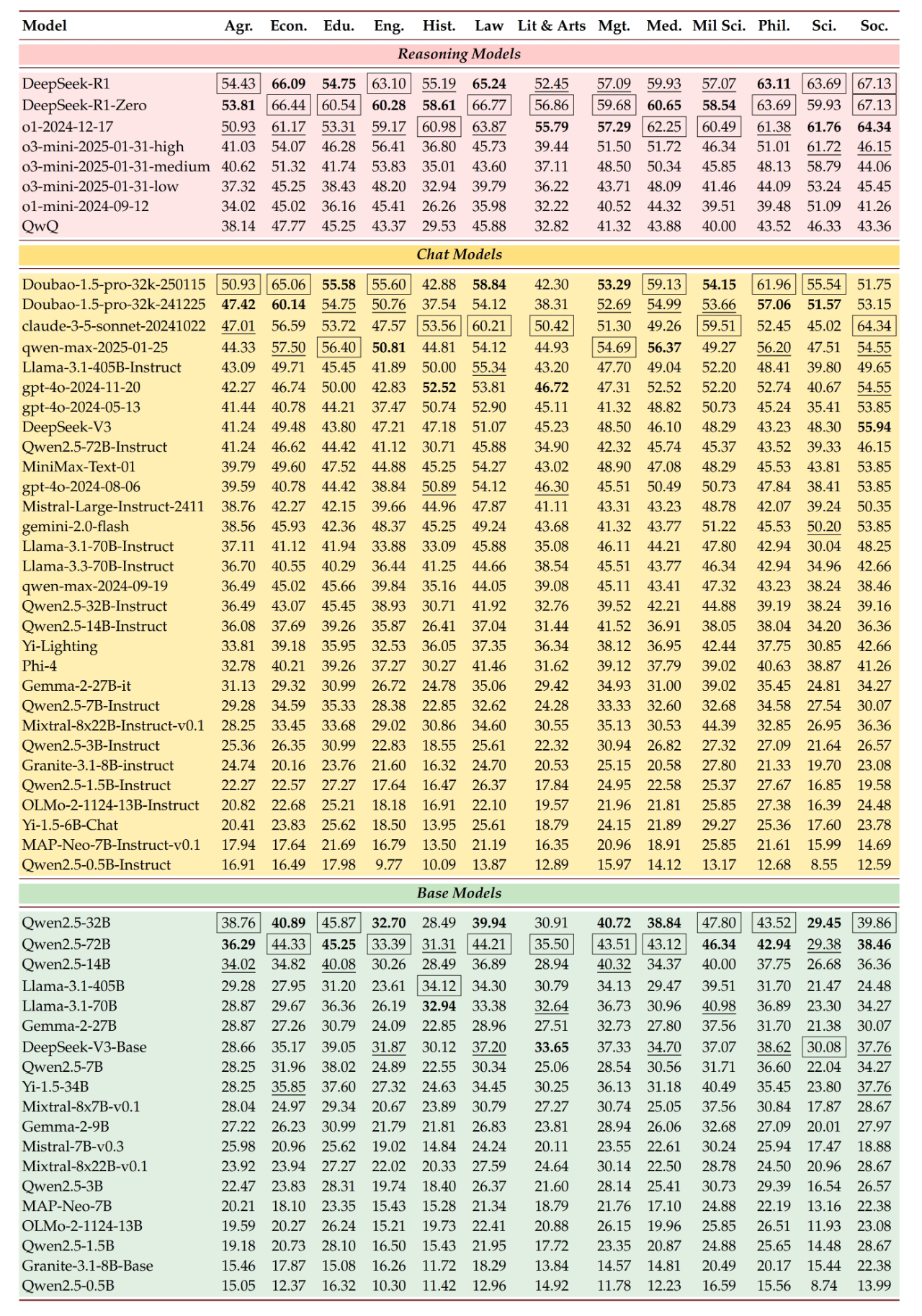
Performance of LLMs across disciplines
- Instruction tuning improves performance dramatically
The results of DeepSeek-V3 and Qwen2.5-72B-Instruct are (47.40 and 40.75) far better than the results of their basic versions (32.14 and 34.33) respectively, proving the effectiveness of instruction tuning.
- More powerful LLMs lead to more balanced results
DeepSeek-R1 performed well on simple (63.59), middle (63.63), and hard (56.87) questions. In contrast, Qwen2.5-14B-Instruct showed large performance gaps oin the same categories (44.82, 37.90, 19.97).
- Inference model training paradigms still to be optimized
The performance gap between DeepSeek-R1 and DeepSeek-R1-Zero is small, especially in science and engineering. The latter model is slightly more advanced, suggesting that the best training method has yet to be determined.
- Continuous optimization of pre-trained corpora
LLMs such as the Qwen-max and GPT-4o series have improved significantly over time on SuperGPQA, demonstrating the high value developers place on the long-term integration of knowledge.
- Open-source models face challenges
Although transparent LLMs such as MAP-Neo-7B and OLMo-2-1124-13B perform satisfactorily, they are still inadequate on difficult questions, especially when compared to non-transparent open- and closed-source models in the industry.
- Model performance varies across different competencies
Doubao-1.5-pro ranked first among chat models with a 55.09% accuracy. We found that general LLMs (such as the Doubao series) performed well in terms of knowledge recall for common professional questions, but had difficulty in inference for long-tail domains.
The o3-mini series scored lower than Doubao-1.5-pro on simple and moderately difficult questions, but significantly outperformed it on difficult questions, indicating that inference models excel on difficult questions yet lack coverage of broad knowledge.
5.Exploring the Boundaries of Models' True Abilities over Half a Year
The SuperGPQA evaluation set was set up over half a year, with nearly 100 academic scholars, Master's and PhD students, and industry engineers participating in its annotation. Through a LLM-expert collaborative process, comprehensive 285-discipline coverage, and diverse difficulty distribution design, SuperGPQA addresses the gap in professional evaluation in long-tail domains and is poised to be a key tool for measuring LLMs' abilities to generalize and the upper limit of their inference capacities.
Our experimental results not only reveal a huge gap still existing between current model capabilities and general AI, but also provide an interdisciplinary analytical framework for AGI development. In the future, we will expand the scope of our datasets and improve the collaborative annotation mode between humans and models to meet the challenges of rapidly evolving AI technology.