Doubao Text-to-Image Technical Report Released! Full Disclosure of Data Processing, Pre-training, and RLHF Workflow
Doubao Text-to-Image Technical Report Released! Full Disclosure of Data Processing, Pre-training, and RLHF Workflow
Date
2025-03-12
Category
Technology Launch
Today, the Doubao (Seed) team officially released the technical report on text-to-image generation, unveiling the technical details of the Seedream 2.0 image generation model for the first time. The report comprehensively covers the full workflow, including data construction, pre-training framework, and post-training RLHF.
This report provides an in-depth introduction to key features of Seedream 2.0, such as its native bilingual understanding (Chinese-English), text rendering, high aesthetic appeal, resolution, and aspect ratio transformations.
This article presents the key highlights of the report. The full version can be accessed via the links below:
Technical demo page: https://team.doubao.com/tech/seedream
Technical Report:https://arxiv.org/pdf/2503.07703
Seedream 2.0, the text-to-image model developed by the Doubao (Seed) team, was launched on Doubao APP and Jimeng in early December 2024. It has already served hundreds of millions of C-end users and has become the preferred model for many professional designers in China for creative assistance.
Compared to mainstream models such as Ideogram 2.0, Midjourney V6.1, and Flux 1.1 Pro, Seedream 2.0 better addresses issues such as poor text rendering and insufficient understanding of Chinese culture. It supports native bilingual processing in Chinese and English while improving aesthetics, instruction adherence, and overall capabilities.
Specifically, the model supports high-precision understanding and adherence to prompts in both Chinese and English, generating highly aesthetic images.

For practical applications such as font rendering and poster design, the model significantly reduces text rendering error rate while making font variations appear more natural and visually appealing.

For Chinese cultural patterns and elements, such as traditional Chinese painting, clay sculptures, antiques, qipaos, and calligraphy, Seedream 2.0 is capable of producing high-quality visual outputs.

To ensure a comprehensive and objective evaluation of the model, the team has developed a Bench-240 benchmark focusing on text-image alignment, structural accuracy, and aesthetic quality.
Through testing, the team found that when handling English prompts, Seedream 2.0 demonstrates higher structural coherence and more accurate text understanding compared to mainstream models.
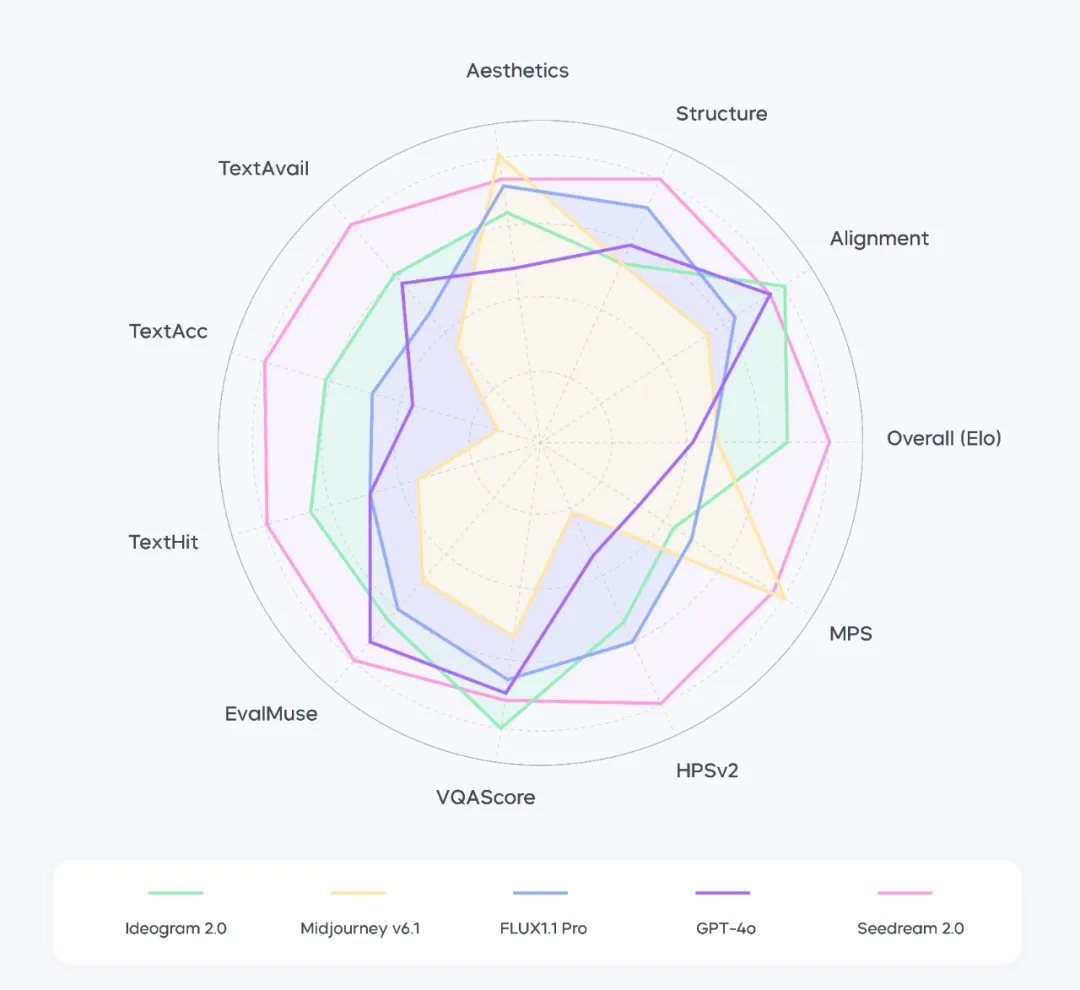
Note: Performance of Seedream 2.0 across different dimensions for English prompts. The data in this chart has been normalized using the best indicators as a reference.
Seedream 2.0 also excels in Chinese-language tasks, achieving a 78% usability rate for generated and rendered text, with a 63% perfect response rate, surpassing other models in the industry.
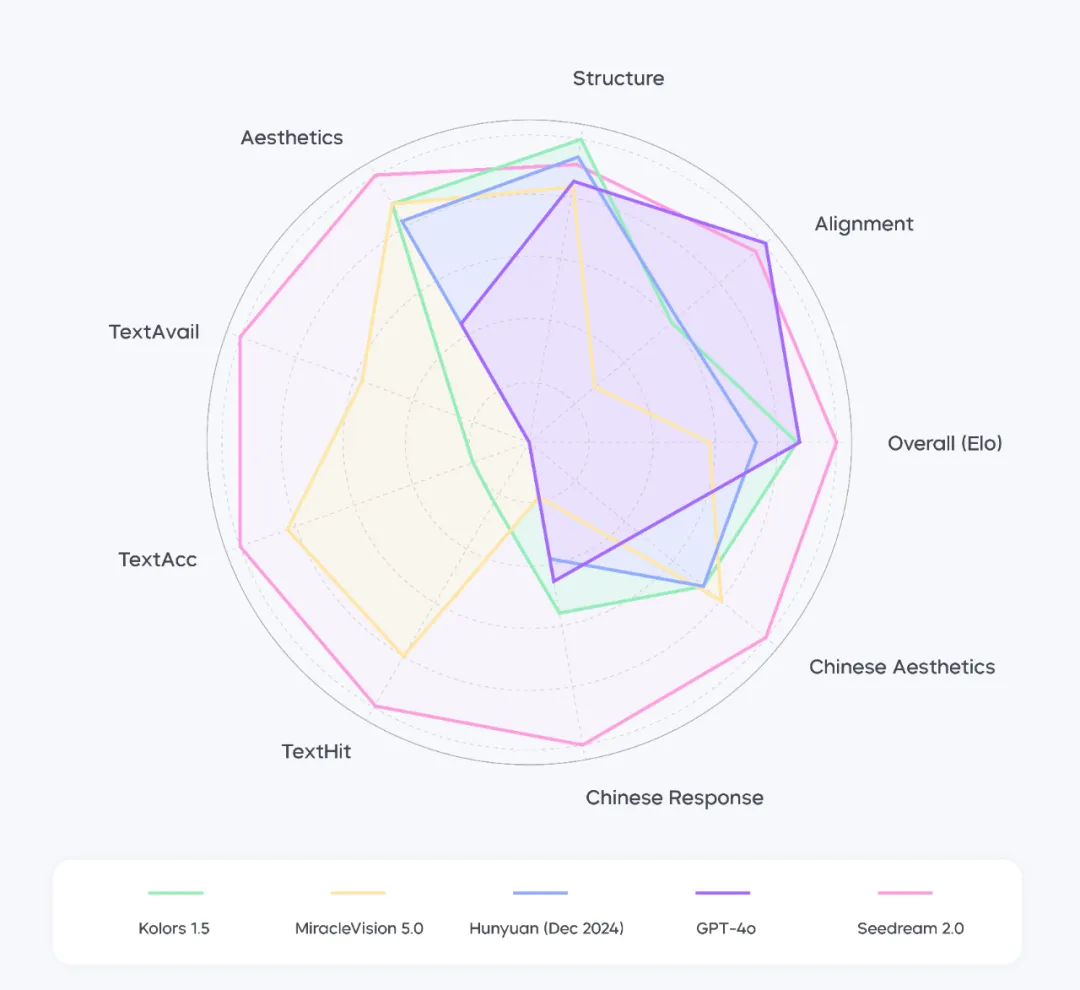
Note: Performance of Seedream 2.0 across different dimensions for Chinese prompts. The data in this chart has been normalized using the best indicators as a reference.
The following sections will detail the technical aspects of the model, covering data preprocessing, pre-training, and post-training.
1. Deep Integration of Knowledge in Data Preprocessing Framework
Generative AI technology is shifting from the brute-force approach of scale-driven "brute-force aesthetics" to "precision intelligence" that meets specific requirements. In tandem with this shift, data preprocessing has evolved into a complex system engineering process.
To handle tens of billions of multimodal Chinese-English data points, the Seedream 2.0 team has developed a preprocessing framework centered around "knowledge integration", achieving breakthroughs in three key areas.
4D Data Architecture: Achieving a Dynamic Balance Between Quality and Knowledge
Traditional image generation models often face the trade-off between data "quality – scale". While larger datasets improve model capabilities, expanding data volume frequently compromises quality, ultimately affecting model performance.
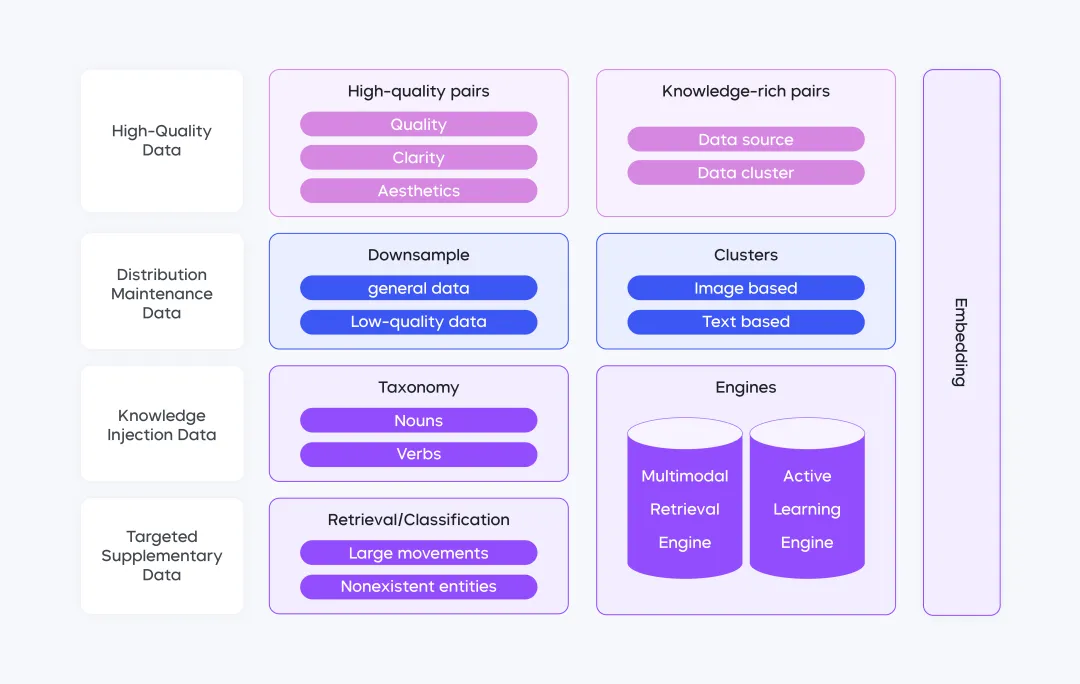
To address this, the team innovatively designed a four-dimensional topological network, breaking the limitations of single-modality data. This architecture consists of four data layers:
1) High-Quality Data Layer: Selects high-resolution, knowledge-dense data (e.g., scientific illustrations, artistic creations) to establish a strong quality foundation;
2) Distribution maintenance layer: Utilizing a dual-level downsampling strategy, the framework proportionally downsamples data from major platforms at the data source level, while maintaining semantic diversity through fine-grained clustering into over 100,000 categories;
3) Knowledge injection layer: Constructs a taxonomy of 30,000+ nouns and 2,000+ verbs, integrating cross-modal retrieval from a dataset of tens of billions to embed cultural characteristics into the data;
4)Targeted Enhancement Layer: Establishes a closed-loop system of "defect detection – data supplementation – performance validation" to optimize action sequences, counterfactual generation, and other scenarios.
This four-dimensional architecture effectively balances data quality and knowledge diversity, providing a robust foundation for model training.
Intelligent Annotation Engine: Three-Stage Cognitive Evolution
Traditional captioning systems are limited by single-modal understanding, often failing to provide comprehensive and precise image descriptions. Building upon these systems, the team has developed an intelligent annotation engine that undergoes a three-stage cognitive evolution, significantly enhancing the model's understanding and recognition capabilities.
First, a hierarchical description system is constructed, combining short captions, long captions, and special-scene captions to achieve multi-dimensional and multi-level precise image descriptions. This approach captures both the core content of images and provides rich details and artistic interpretations.
Second, a cultural-specific term mapping database is established to achieve cross-language alignment, reducing the quality gap between Chinese and English generations to within 2%. This significantly improves the model's performance in multilingual environments.
Lastly, a dynamic quality control mechanism is introduced, utilizing LLM-based pre-screening to filter data and improve annotation precision. The model iterates prompt templates based on bad case analysis, optimizing description quality to ensure data accuracy and reliability.
Engineering Reconstruction: Pipeline Parallelism for Large-Scale Data Handling
From an engineering perspective, traditional ETL (Extract, Transform, Load) pipelines suffer from computational resource misallocation and slow iteration cycles.
This leads to non-core tasks occupying high-computation resources, limiting critical tasks and causing workflow inefficiencies that hinder adaptability to business and data changes.
The team has restructured the engineering system from two key aspects.
First, heterogeneous scheduling is implemented, migrating non-core tasks (such as watermark detection) to low-computation clusters, thereby freeing high-performance computing resources for essential operations. Second, a three-tier pipeline processing method is adopted, following a "Sharding–Validation–Loading" process in parallel. This innovation has improved data packaging speed by 8 times, significantly enhancing data processing efficiency and quality. These improvements lay a solid foundation for large-scale data management and utilization.
2. Pre-training Focus: Bilingual Understanding and Text Rendering
During the pre-training phase, based on extensive user research and technical forecasts, the team determined that breakthroughs in multilingual semantic understanding, bilingual text rendering, and multi-resolution adaptability are crucial for advancing image generation technology. These improvements significantly enhance model applicability, user experience, and usability across different linguistic and cultural backgrounds while expanding the range of practical applications.
As a result, Seedream 2.0 adopts an entirely new pre-training architecture, as outlined in the diagram below.
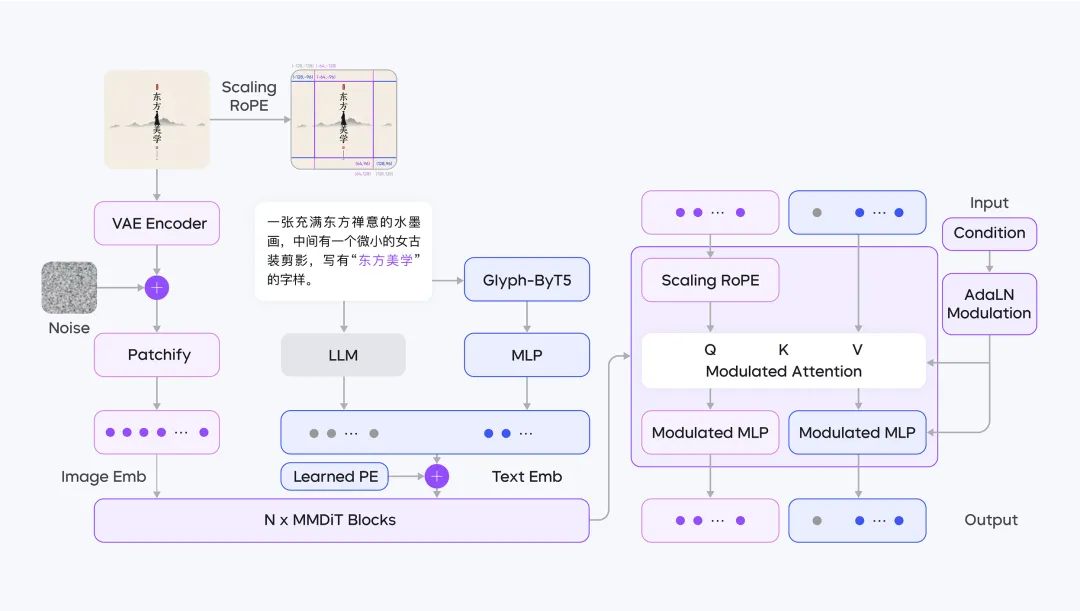
Specifically, Seedream 2.0 has achieved key technological upgrades in three areas.
Native Bilingual Alignment: Breaking the Language-Vision Barrier
In bilingual text-to-image generation, traditional CLIP/T5 encoders struggle to capture Chinese semantics and cultural nuances, while large language models (LLMs), despite their multilingual capabilities, face spatial distribution mismatches between text embeddings and image features, making diffusion model training difficult to converge.
To address this, the team developed an LLM-based bilingual alignment strategy. By leveraging a large-scale text-image paired dataset, they fine-tuned a Decoder-Only LLM architecture, ensuring spatial alignment between text embeddings and visual features.
Additionally, a specialized dataset was constructed to enhance the model's understanding of cultural symbols, covering areas such as Chinese calligraphy, dialect slang, and technical terms.
This dual-track approach—"pre-training alignment + domain enhancement"—enables the model to "directly" learn authentic linguistic and cultural knowledge from massive bilingual datasets. As a result, Seedream 2.0 accurately generates images with nuanced cultural aesthetics in both Chinese and English, effectively bridging the gap between language and vision.
Enabling the Model to Understand Text Meaning and Font Style
In previous models, text rendering in image generation faced a trade-off: Relying on ByT5 and similar font models often leads to layout inconsistencies in long text, while incorporating OCR image features requires an additional layout planning module.
To address this, the team developed a dual-modal encoding fusion system, where the LLM interprets "what the text conveys", while ByT5 focuses on "what the text should look like."
Specifically, an MLP projection layer was introduced to align ByT5's font features with the semantic space of the LLM. The fused representations are then fed into the diffusion model.
With this approach, font attributes such as typeface, color, size, and positioning no longer rely on preset templates. Instead, the LLM directly describes the text's visual properties, allowing for end-to-end training.
This enables the model to learn text rendering features from training data, while also efficiently capturing font characteristics for text generation.
Three-Tier DiT Architecture Upgrade: Scalable Image Generation
Multi-resolution image generation is a common requirement in various scenarios. The team built upon SD3's MMDiT architecture, introducing two major upgrades:
First, in terms of training stability. The team introduced QK-Norm to suppress numerical fluctuations in the attention matrix. Combined with the Fully Sharded Data Parallelism (FSDP) strategy, this improvement accelerated model convergence speed by 300%.
Second, the team designed the Scaling ROPE technique. Traditional 2D Rotary Position Embedding (RoPE) may cause misalignment of position identifiers when resolution changes. Seedream 2.0 dynamically adjusts encoding using a scaling factor, ensuring spatial consistency in the central region of images across different aspect ratios. This allows the model to generate previously unseen image sizes and various resolutions during inference.
3. Post-Training RLHF: Breaking Through Performance Bottlenecks
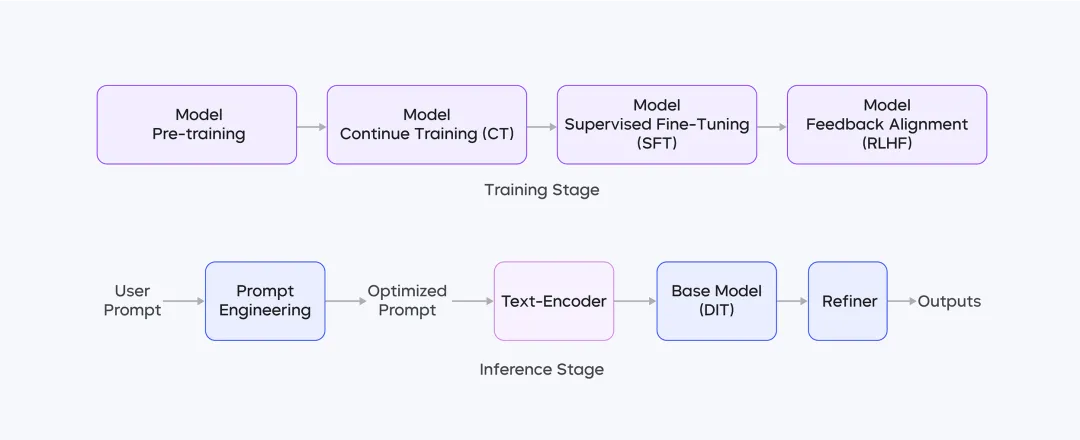
The post-training process of Seedream 2.0 consists of four stages:
Among them, CT (Contrastive Tuning) and SFT (Supervised Fine-Tuning) enhance the model's aesthetic appeal; RLHF utilizes a self-developed reward model and feedback algorithm to improve the model's overall performance; Prompt Engineering leverages fine-tuning of a large language model to optimize aesthetic quality and diversity; Super-resolution models increase image resolution and correct minor structural errors.
Among these, the most notable breakthrough is the development of an RLHF-based optimization system, significantly improving the overall performance of Seedream 2.0.
Its core tasks include the following three aspects:
Multi-Dimensional Preference Data System: Expanding Model Preference Limits
The team collected and curated a multi-functional prompt set, specifically designed for reward model (RM) training and feedback learning. By constructing cross-version and cross-model annotation pipelines, they enhanced RM's domain adaptability and expanded the model's preference limits.
During the annotation stage, a multi-dimensional fusion annotation approach was implemented. This successfully expanded the preference representation boundaries of a single reward model, allowing the model to achieve Pareto optimality across multiple dimensions.
Three Distinct Reward Models for Specialized Enhancements
Seedream 2.0 directly utilizes CLIP embedding space distance as a fundamental reward value, eliminating the need for redundant regression heads and unstable training structures.
Additionally, the team developed and trained three specialized reward models: Image-Text Alignment RM, Aesthetic RM, and Text Rendering RM.
The Text Rendering RM incorporates a triggered activation mechanism. When detecting "text generation"-related labels, the model enhances character detail optimization, improving Chinese character generation accuracy.
Iterative Learning to Drive Model Evolution
The team maximized multiple RM reward functions to refine the diffusion model. By adjusting learning rates, selecting optimal denoising timesteps, and applying exponential moving average (EMA) weighting, they achieved stable feedback learning training.
During the feedback learning stage, both DiT and the text encoder were fine-tuned simultaneously. This joint training process significantly improved image-text alignment and aesthetic enhancements.
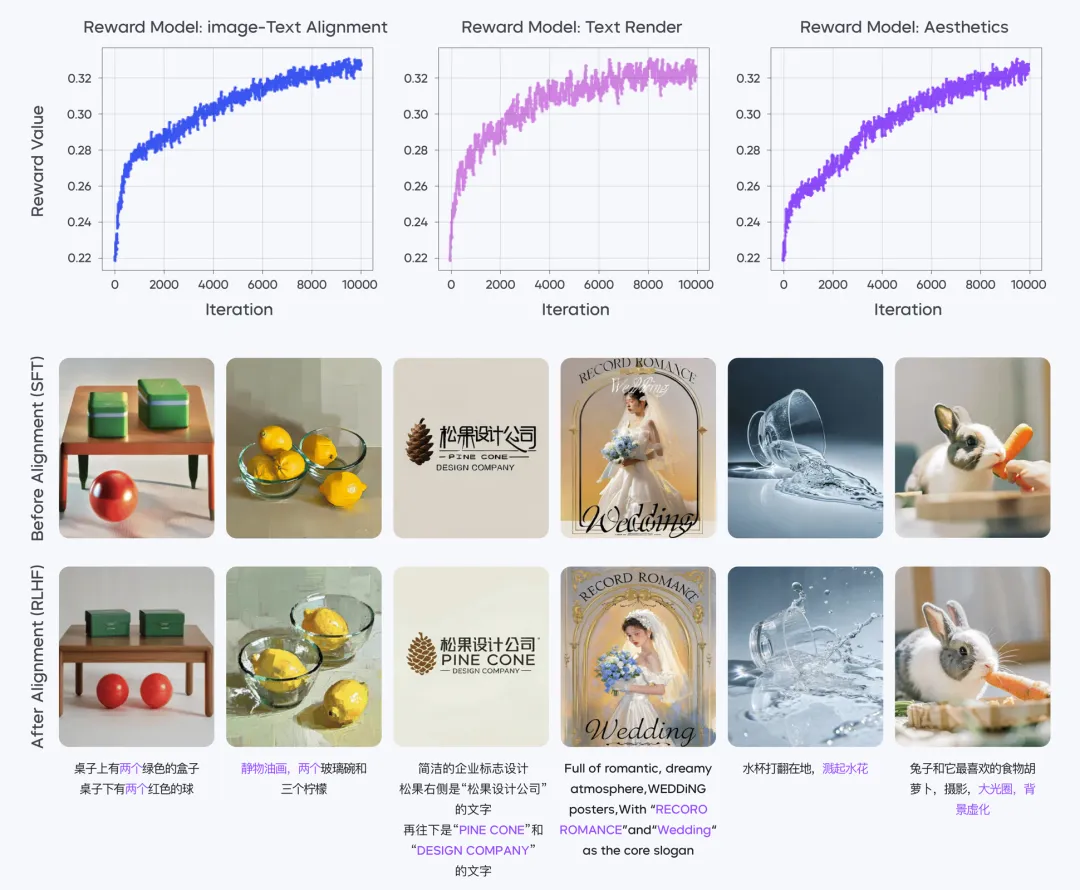
Through multiple iterative cycles of RLHF optimization on both the diffusion model and reward models, the team further enhanced model performance.
Reward curves indicate that throughout the alignment process, all reward models exhibited a stable and consistent upward trend in performance scores.
4. Final Thoughts
The release of this technical report aims to advance image generation technology and strengthen industry-wide collaboration.
Looking ahead, the team will continue to explore more efficient scaling techniques for both model parameters and data, further pushing the boundaries of model performance.
As the reinforcement learning revolution gains momentum in 2025, the team will actively explore reinforcement learning-based optimization mechanisms, focusing on designing better reward models and data construction strategies.
Moving forward, the Doubao (Seed) team will continue sharing technical insights to drive industry growth together.
Click the link to learn more about Seedream 2.0 and access the full report.