Seed Research | Latest Breakthrough in Video Generation: Learning to Understand the World Through Vision Alone! Now Open Source
Seed Research | Latest Breakthrough in Video Generation: Learning to Understand the World Through Vision Alone! Now Open Source
Date
2025-02-10
Category
Seed Research

The experimental video generation model "VideoWorld" is jointly introduced by the Doubao (Seed) team, Beijing Jiaotong University, and University of Science and Technology of China. VideoWorld is the first in the industry to understand the world without relying on language models, unlike major multimodal models such as Sora, DALL-E, and Midjourney.
VideoWorld enables machines to master complex capabilities such as reasoning, planning, and decision-making solely through "visual information" (i.e., browsing video data), and this echoes what Professor Li Feifei mentioned in his TED talk nine years ago, "Babies can understand the real world without language." Experiments show that VideoWorld achieves impressive model performance with just 300 million parameters.
Existing models typically learn through language or labeled data and seldom learn purely from visual signals. However, language alone cannot capture all knowledge of the real world. For example, it is difficult to effectively convey complex tasks through words, such as origami or bow-tying.
As a general-purpose experimental video generation model, VideoWorld eliminates the need for language models and effectively handles complex tasks requiring reasoning and planning. It leverages a Latent Dynamic Model to efficiently compress visual changes between video frames, thereby greatly improving the efficiency and effectiveness of knowledge learning.
VideoWorld achieves a professional 5-dan level in 9×9 Go and successfully performs robotic tasks across various environments—all without relying on reinforcement learning search algorithms or reward mechanisms.
While challenges remain in generating and generalizing real-world videos, the team believes that video generation holds great potential as a universal approach to knowledge learning, serving as an artificial brain for reasoning and acting in the real world.
Currently, all codes and models are open-sourced. Feel free to explore and share your experiences!
Paper Link: https://arxiv.org/abs/2501.09781
GitHub Link: https://github.com/bytedance/VideoWorld
Project Homepage: https://maverickren.github.io/VideoWorld.github.io
1. Learning Knowledge Solely from “Vision”
In this study, the team builds two experimental environments: Video-based Go and Video-based robotic manipulation.
The team considers the Go game an ideal testbed for assessing a model’s ability to learn rules, reasoning, and planning: it not only has well-defined rules but also demands complex reasoning about the current state to determine the best move and forward planning to outmaneuver an opponent. Moreover, it disentangles low-level details (e.g., appearance and texture) from higher-level knowledge, making it particularly suitable for the team's investigation. Similarly, the team assesses the model’s capability to understand robotic manipulation rules and planning, trained solely on raw video data.
The team begins their investigation with a basic video generation model comprising a VQ-VAE and an autoregressive transformer. The raw task execution videos, collected from the environments described above, serve as the sole source of training data and hence the only source of knowledge.
During model training, the team converts video frames into discrete tokens using VQ-VAE and, similar to large language models (LLMs), trains an auto-regressive transformer on these tokens under the next-token (or next-frame) prediction paradigm. During testing, the model generates new frames based on previous ones, and task-specific operations—such as moves in Go or robotic actions—are inferred from the newly generated frames. This design enables the model to learn task knowledge without relying on any action annotations.
Through this basic framework, the team observes that the model can learn fundamental knowledge from raw videos, including Go rules, policies, and basic robotic operations.
However, as shown in the figure below, the team also finds that knowledge acquisition efficiency from video sequences lags significantly behind that of state-trained models.
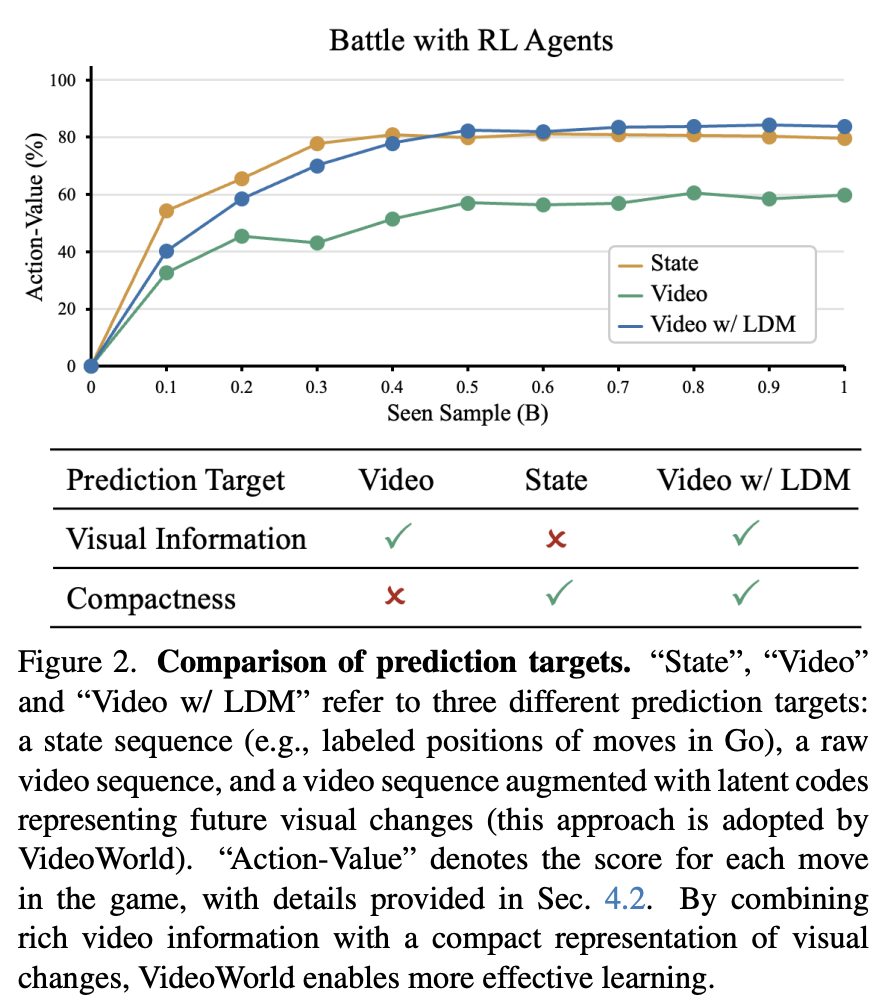
The team attributes this to the inefficient representation of visual changes tied to critical decisions and actions. For example, while moves in Go can be encoded by just a few positional tokens in a state sequence, raw video requires significantly more tokens after passing through a vision encoder. This discrepancy adversely affects both learning efficiency and performance.
2. Compressing Visual Changes for More Efficient Video Learning
Building on the observations above, the team proposes VideoWorld. It integrates rich visual information with a compact representation of visual changes for more effective video learning.
Video encoding typically requires hundreds or thousands of VQ tokens to capture the full range of visual information, leading to sparse embedding of knowledge across these tokens. To enhance efficiency, the team introduces a latent dynamics model (LDM) that uses query embeddings to represent visual changes across multiple frames.
For example, multi-step board changes in Go or continuous actions in robotics exhibit strong temporal correlations. By compressing these multi-step changes into compact embeddings, the team not only increases the compactness of policy information but also encodes guidance for long horizon planning.
The model employs a MAGVITv2-style causal encoder-decoder, while intentionally omitting temporal downsampling to preserve detail in each frame.
For a video clip, the LDM samples each frame along with a fixed number of subsequent frames. The encoder first extracts the feature maps in a causal manner. Importantly, these features are not quantized, allowing them to retain detailed temporal information.
Next, the LDM defines a set of attention blocks and corresponding learnable embeddings. Each query, via the attention mechanism, captures the change information from the first frame to the subsequent frames, yielding a continuous latent representation, which is then quantized with a discrete codebook by FSQ. The quantizer serves as an information bottleneck, preventing the LDM from merely memorizing the original content of the subsequent frames and instead encourages the compression of key dynamic information.
Finally, the decoder uses the feature map of the first frame and the latent change embeddings to predict the subsequent frames causally, ultimately enabling the prediction and planning of future actions and facilitating learning critical knowledge of tasks.
Below is an overview of the model architecture, with the overall architecture on the left and the Latent Dynamic Model on the right.
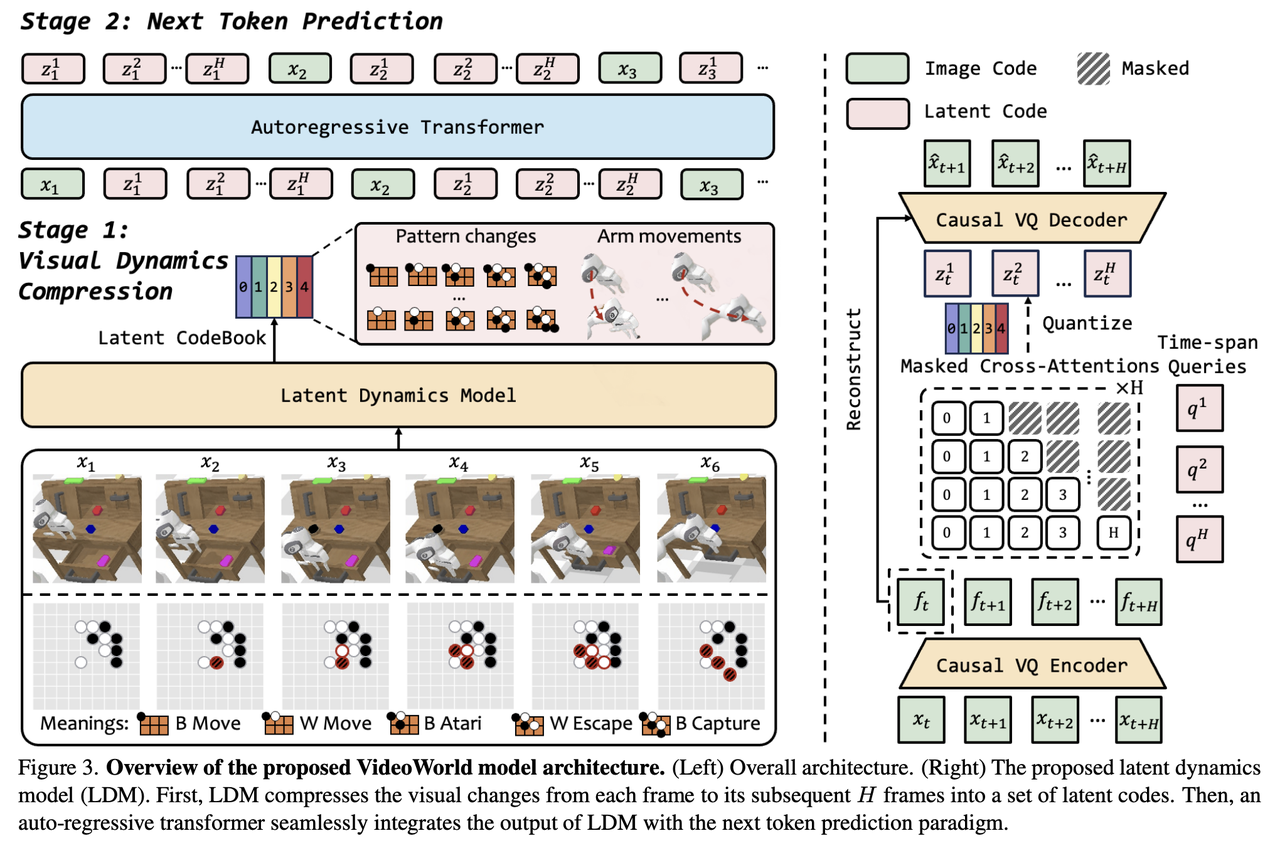
By using multiple embeddings to encode the dynamic changes from the first frame to subsequent frames, VideoWorld achieves a compact yet information-rich visual representation that captures both short-term and long-term dependencies in the visual sequence. This is crucial for long-term reasoning and planning tasks.
With the help of LDM, VideoWorld achieves a professional 5-dan 9x9 Go level with only 300M parameters, without relying on any search or reward function mechanisms typically used in reinforcement learning. In robotic tasks, VideoWorld also demonstrates strong generalization capabilities across multiple tasks and environments.
For more details, please refer to the paper.
3. Pure Visual Models can "Predict" the Future and "Understand" Causality
The team conducts a more detailed analysis of why the LDM made video learning more efficient and reached the following three conclusions:
- LDM learns patterns in the training set.
The diagram below shows a UMAP projection of the learned latent codes on the Go (left) and CALVIN (right) training sets. Each point represents the continuous (pre-quantization) latent code generated by the LDM.
UMAP is a popular dimensionality reduction algorithm used to map high-dimensional data to a lower-dimensional space, showcasing the model's feature learning capabilities.
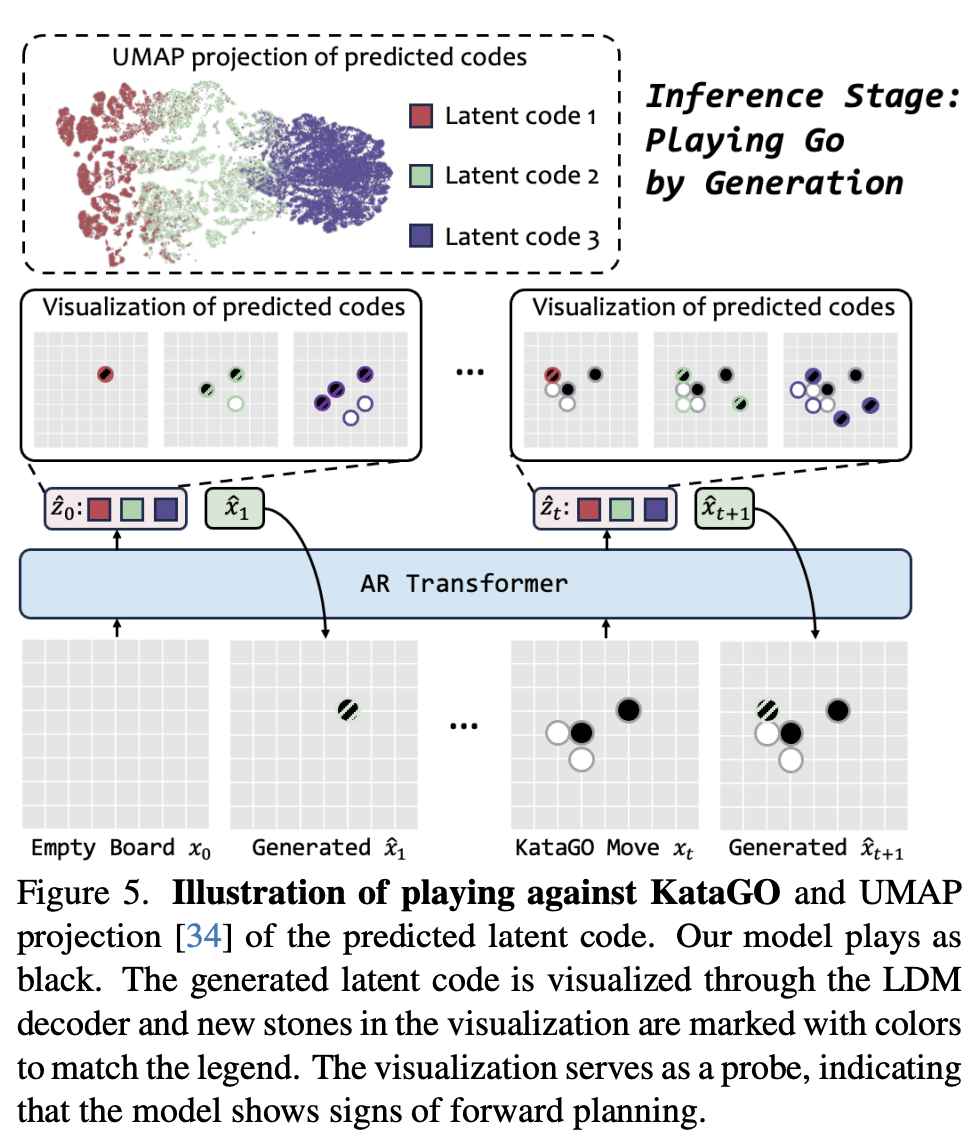
In the Go examples, odd steps represent the white’s moves, and even steps represent the black’s moves. The legend displays examples of common patterns learned for new black moves. For clarity, these moves are highlighted on the board with added colors and lines to indicate new patterns. The UMAP visualization shows that the latent codes in the training set capture both short- and long-term dependencies, demonstrating the model's ability to represent knowledge at different temporal scales.
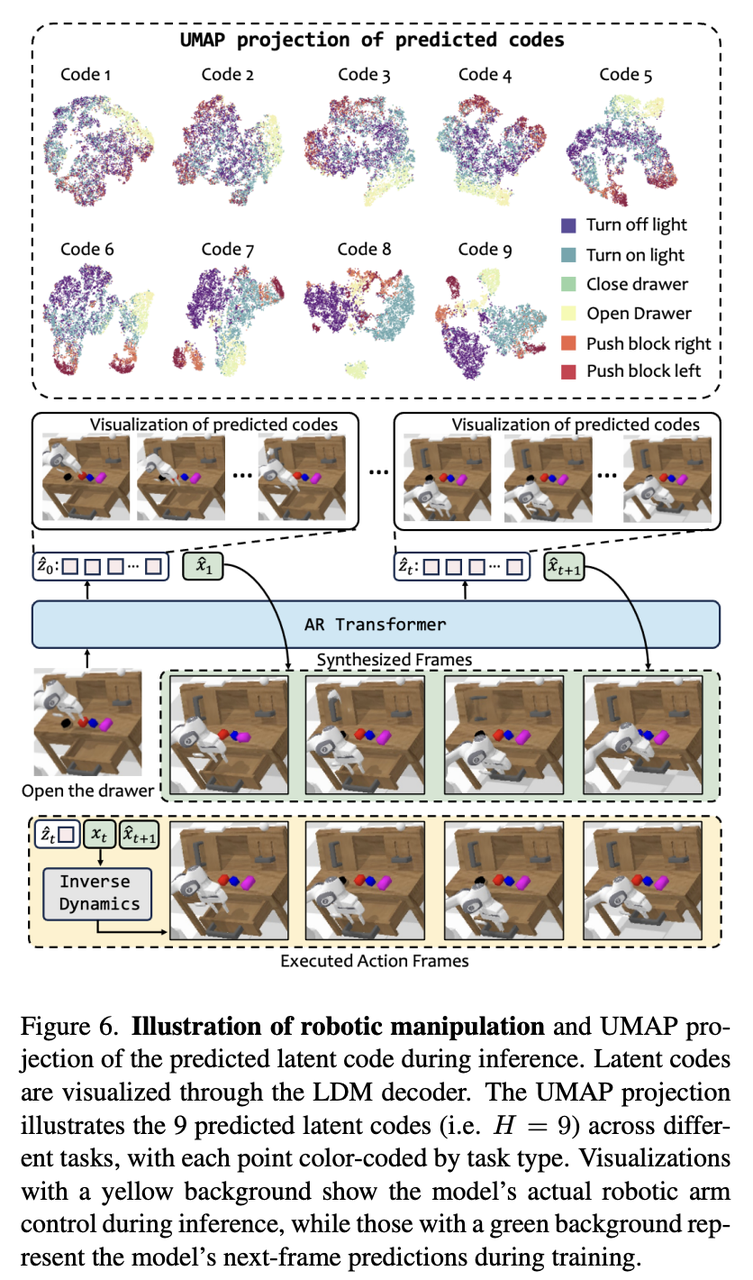
Similarly, the latent codes of the robot arm along the X/Y/Z axis are visualized on the right. The clustering of latent codes across steps reveals key dynamic dependencies over various time ranges, benefiting diverse manipulation tasks.

- LDM enables forward planning during testing.
The team also examines the role of LDM codes during inference.
The visualization below shows that codes from different steps group by output positions, suggesting that VideoWorld models long-range changes progressively, similar to human forward-planning.
Similar findings are observed in the robotic scenario.
The following figure visualizes the predicted latent codes during inference across different tasks. As shown, the latent codes for different prediction steps are grouped by task type, indicating that they effectively capture task-relevant dynamics.
- LDM generates causally interrelated codes.
To further investigate the impact of the learned latent codes, the team conducts an intervention experiment. They replace latent codes at different time steps with random tokens and observe the effect on model performance.
The results suggest that intervening with the first code has the greatest effect, likely due to the causal dependencies among the codes. The team believes that altering the first code, which represents the optimal decision for the immediate next time step, influences all future decisions. This indicates that the model generates causally related codes and understands causal relationships.
4. Final Thoughts
Although VideoWorld demonstrates exceptional performance in Go and simulated robotic manipulation tasks, the team also recognizes that its application in real-world settings still faces challenges, such as high-quality video generation and generalization across multiple environments.
In the future, the team will focus on addressing these issues, advancing video generation models to become general knowledge learners in real-world scenarios.
If you are also interested in solving complex problems in the field of large models and are eager to explore cutting-edge topics, we invite you to visit our careers page for more details about available positions.