Seed Research | New ultra-sparse architecture reduces inference costs by up to 83% compared to MoE!
Seed Research | New ultra-sparse architecture reduces inference costs by up to 83% compared to MoE!
Date
2025-02-12
Category
Seed Research

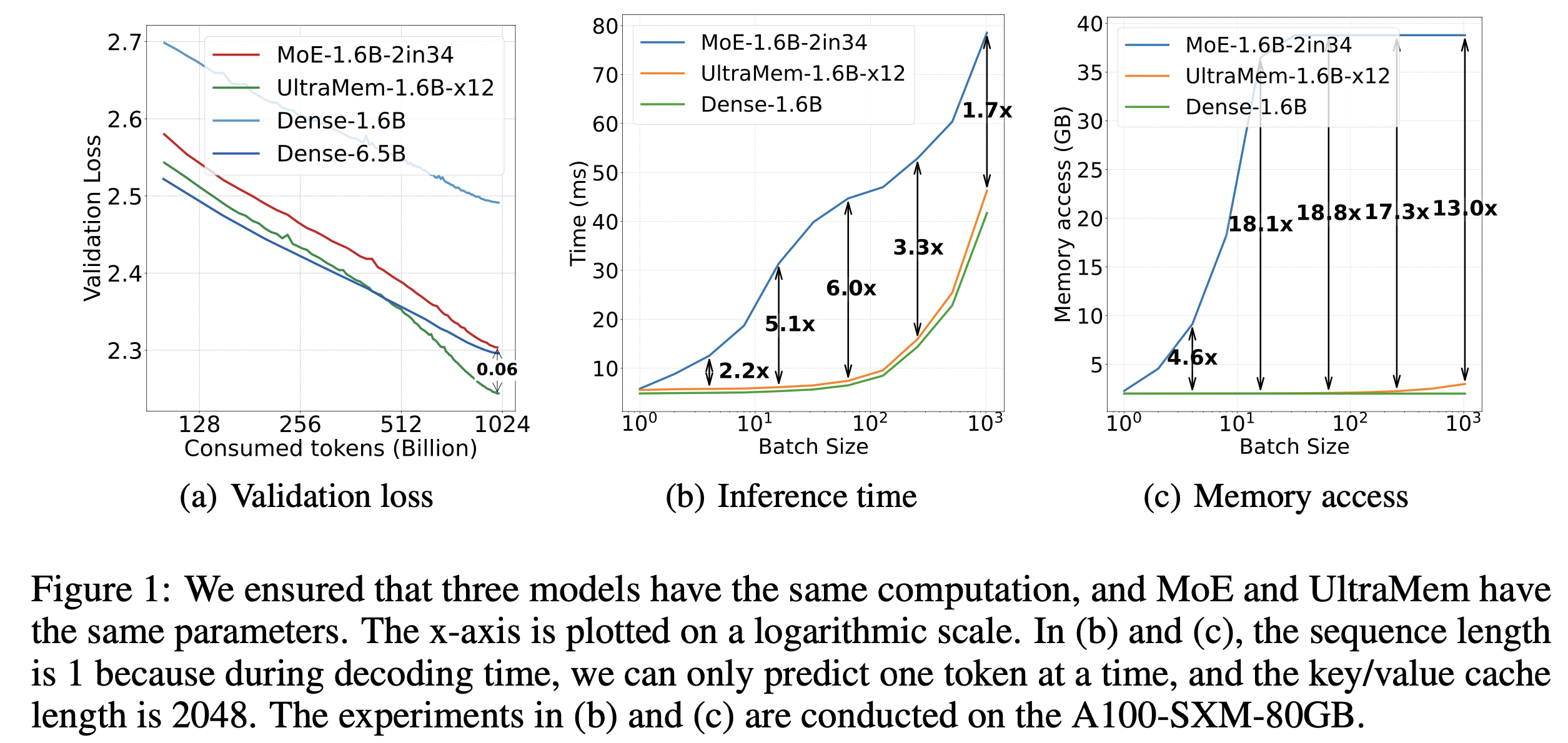
As the model scale expands, inference cost and memory access efficiency are major bottlenecks that limit the large-scale application of large models. ByteDance Doubao (Seed) team recently introduced UltraMem, a new sparse model architecture. UltraMem effectively addresses high inference costs and memory access issues during MoE inference, achieving 2-6x faster inference speeds and reducing inference costs by up to 83%. This research also reveals the Scaling Law of the new architecture, showing that it not only possesses excellent Scaling characteristics, but also outperforms MoE.
The experimental results show that the UltraMem model with a training scale of 20 million values can achieve both industry-leading inference speed and model performance using the same computing resources. This paves the way for building models with billions of values or experts.
In the Transformer architecture, model performance has a logarithmic relationship with the number of parameters and computational complexity. As the scale of LLM continues to increase, the inference cost will rise sharply, and the speed will slow down.
Although MoE architecture has successfully decoupled the computation from the parameters, a small batch size during the inference proces activates all experts, leading to a dramatic rise in memory access, which in turn greatly increases inference latency.
To address this issue, the ByteDance Doubao Foundation Model team has proposed UltraMem, a sparse model architecture that also decouples computation from the parameters. UltraMem solves the problem of memory access during the inference process while ensuring model performance.
The experimental results show that, under the same conditions of parameters and activations, UltraMem outperforms MoE in terms of model performance and increases the inference speed by 2-6 times. In addition, under the common batch size scale, the memory access cost of UltraMem is almost equivalent to that of the Dense model with the same computational amount.
Currently, this paper has been accepted by ICLR 2025.
Ultra-Sparse Memory Network
Link to study: https://arxiv.org/abs/2411.12364
1. Limitations of MoE and PKM
Expanding the capabilities of LLM requires exponential growth in computing resources, which poses a significant challenge in environments with limited resources such as real-time applications. To solve the computational problem, previous researchers have proposed MoE and Product Key Memory (PKM) solutions, but both have limitations.
MoE decouples computation from parameters by sparsely activating experts, but it suffers from slow inference speed. The reason is that the model can only generate text word by word during the inference process, so both the batch size and the sequence length are very small. In this scenario, all the experts in MoE are usually accessed, leading to memory access bottlenecks and a sharp increase in inference latency.
PKM first proposed the large memory layer, which consists of a large number of sparse parameter values. In this context, a value refers to a vector. Each token is located to the values with the highest scores using a "row routing" and a "column routing". After activating these values, a weighted sum pooling is performed as the output of the memory layer. Since this approach activates only a minimal number of values per token during inference, it avoids memory access bottlenecks. However, it suffers from poor performance, and has limited scaling ability.
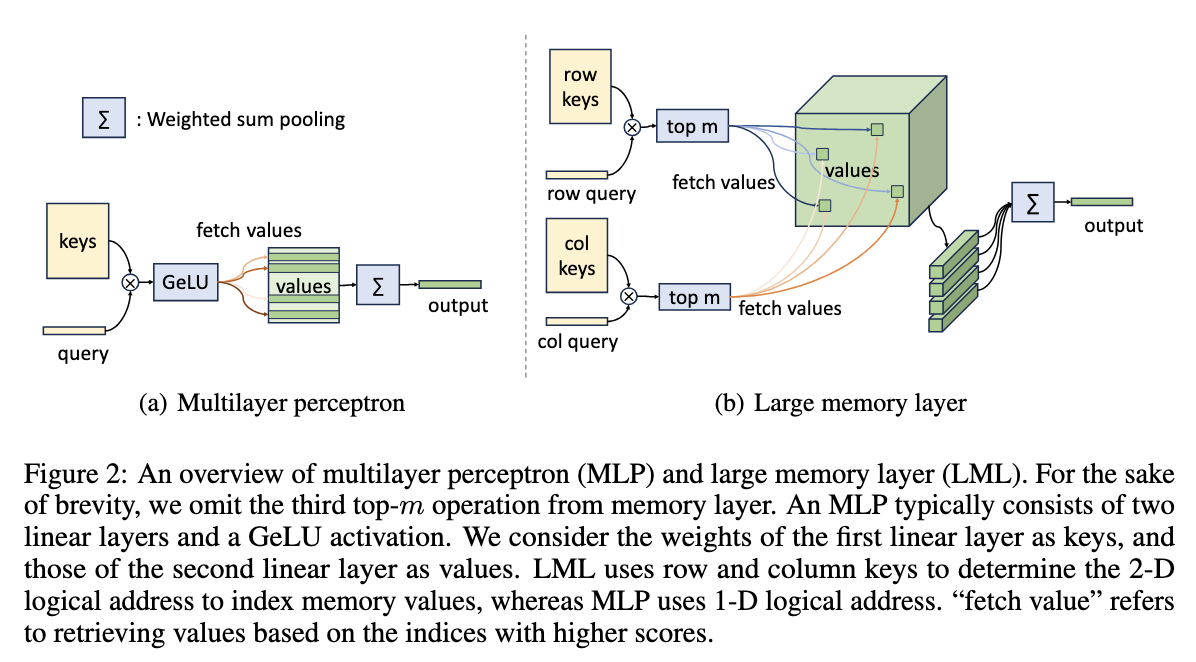
2. UltraMem has the advantages of both high memory access efficiency and performance.
UltraMem refers to the design of PKM, but complements the 3 deficiencies of PKM to achieve more efficient memory access, better value retrieval, and simultaneously reduce video memory and deployment costs.
① Optimizing Model Architecture
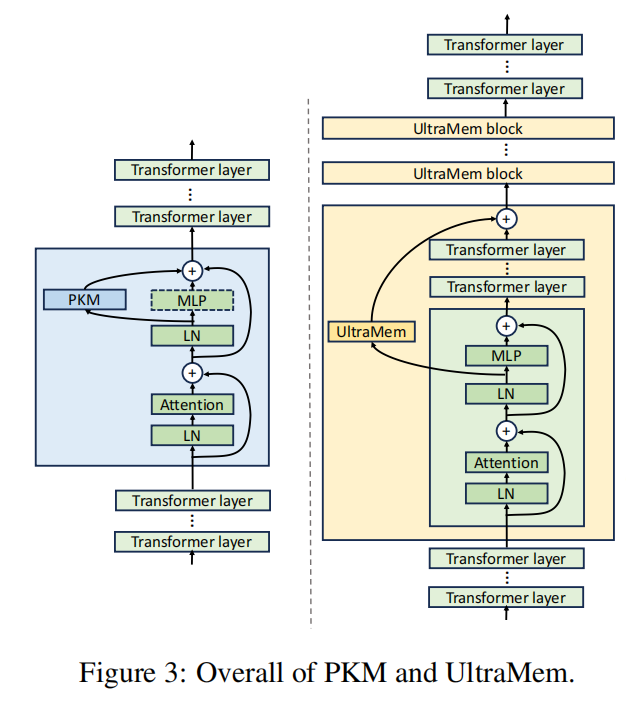
In the design of PKM, the memory layer consists of only 1 layer and is inserted in the middle layer of the entire Transformer. This design is not ideal for large-scale training, and such a large number of sparse parameters should be involved in each residual connections as much as possible.
Therefore, the research team splits into multiple small memory layers, which are distributed in the transformer layer at regular intervals. Moreover, a skip-layer operation is added, that is, the output of the memory layer in the current layer will be added to the output of a certain subsequent transformer layer. This enables the model to perform memory access of memory layer and computation of transformer layer in parallel.
② Optimizing value retrieval method
During retrieval, only m values with the highest score will be activated, and the score of PKM is obtained by adding the "row score" and "column score". The team further explored a more complex multiplication method, Tucker Decomposed Query-Key Retrieval(TDQKR). This method was inspired by Tucker Decomposition. Specifically, given the values with a shape of (n, n, h), where h is the hidden size, the score S_grid of values can be decomposed as follows:
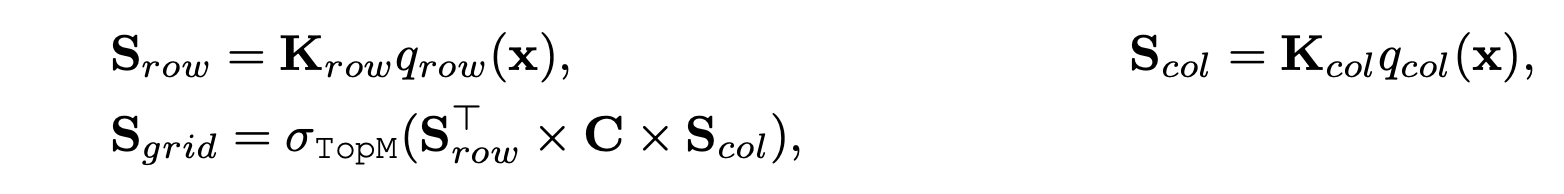
whereSrow,Scol∈Rr×n\mathbf{S}_{row}, \mathbf{S}_{col} \in \mathbb{R}^{r\times n}Srow,Scol∈Rr×n,C∈Rr×rC\in \mathbb{R}^{r\times r}C∈Rr×r are learnable tucker cores. Under this structure, the score of each value is obtained by multiplying the combination of r row scores and r column scores, which has a higher level of complexity.
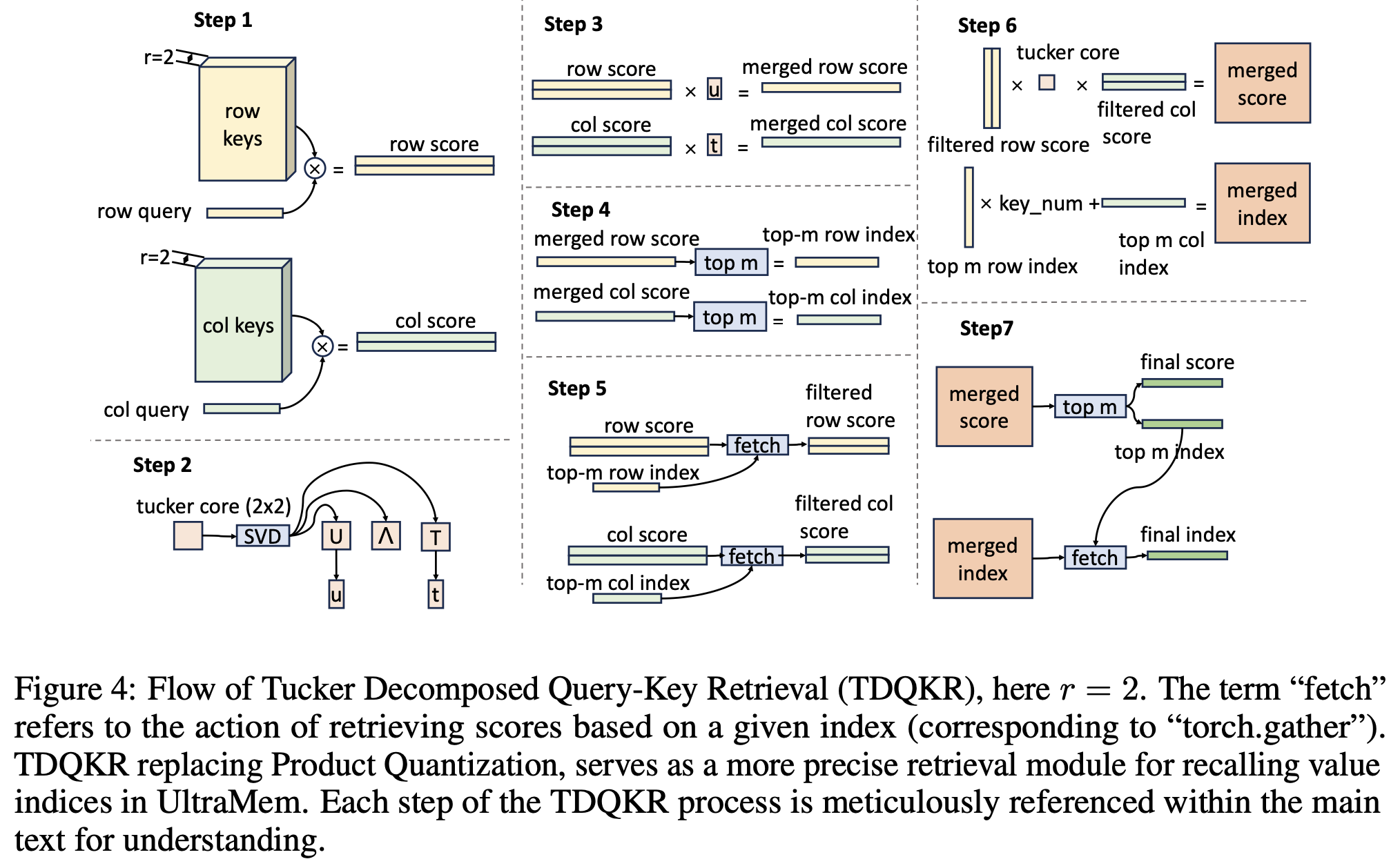
③ Implicit Expanding Sparse Parameters
More sparse parameters usually lead to better results, but too many parameters can cause problems with video memory and deployment. To address this issue, the research team proposed the Implicit Value Expansion (IVE) method to implicitly extend sparse parameters, and introduced the concepts of virtual memory and physical memory.
Take the 4x expansion as an example (as shown in the figure below), the number of virtual memory is 4 times that of physical memory. Given multiple pairs (score, index), first, a lookup is performed according to the virtual memory address table. The 4 virtual blocks query the same physical memory table. Then, each performs weighted sum pooling, and passes through different linear layers. Finally, the results are summed up for output.
Since there is no non-linear operation between the final Linear and value retrieval, each Linear can be merged with the physical memory table to generate a new memory table. In this example, the number of value is actually implicitly expanded by 4 times.
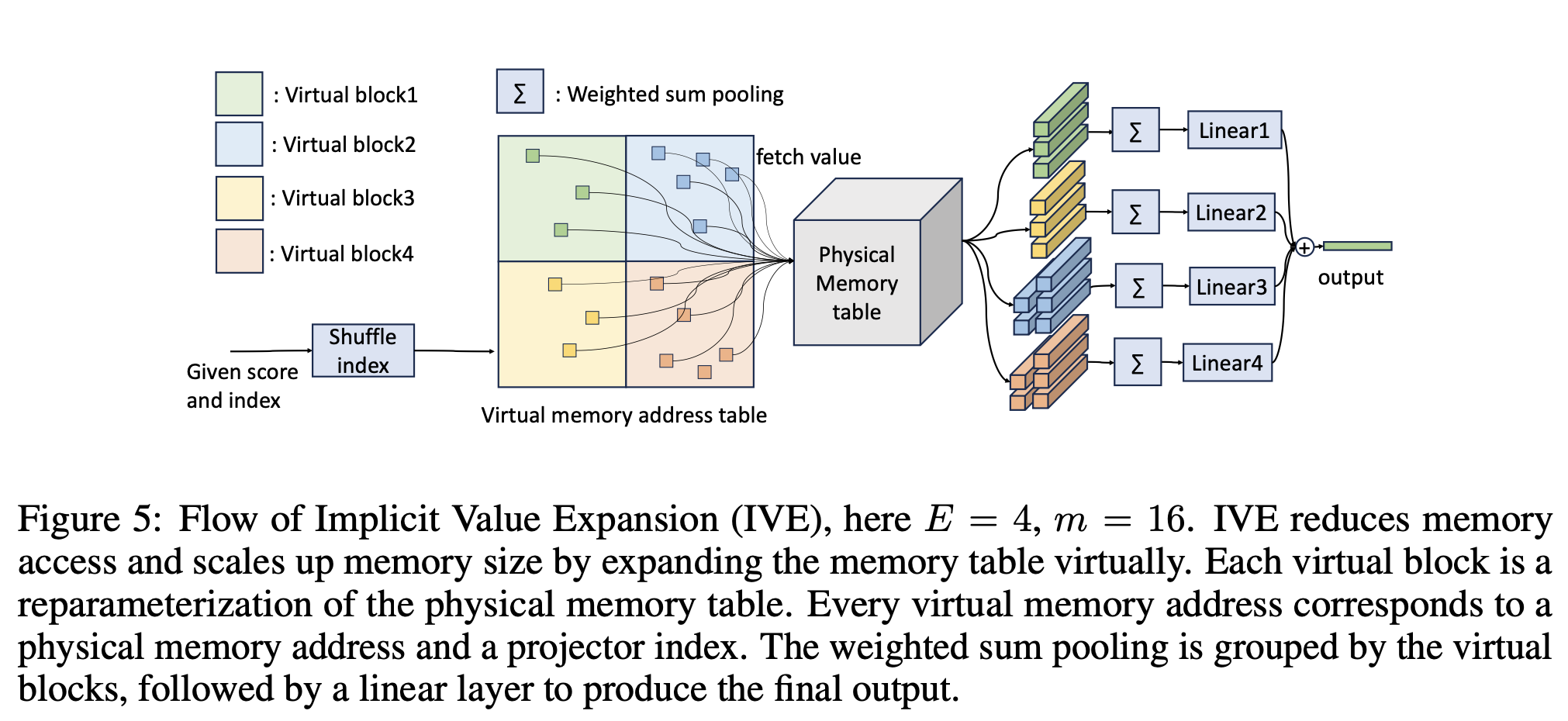
3. Experimental results: The inference speed is increased by up to 6 times compared with MoE
① Model performance evaluation
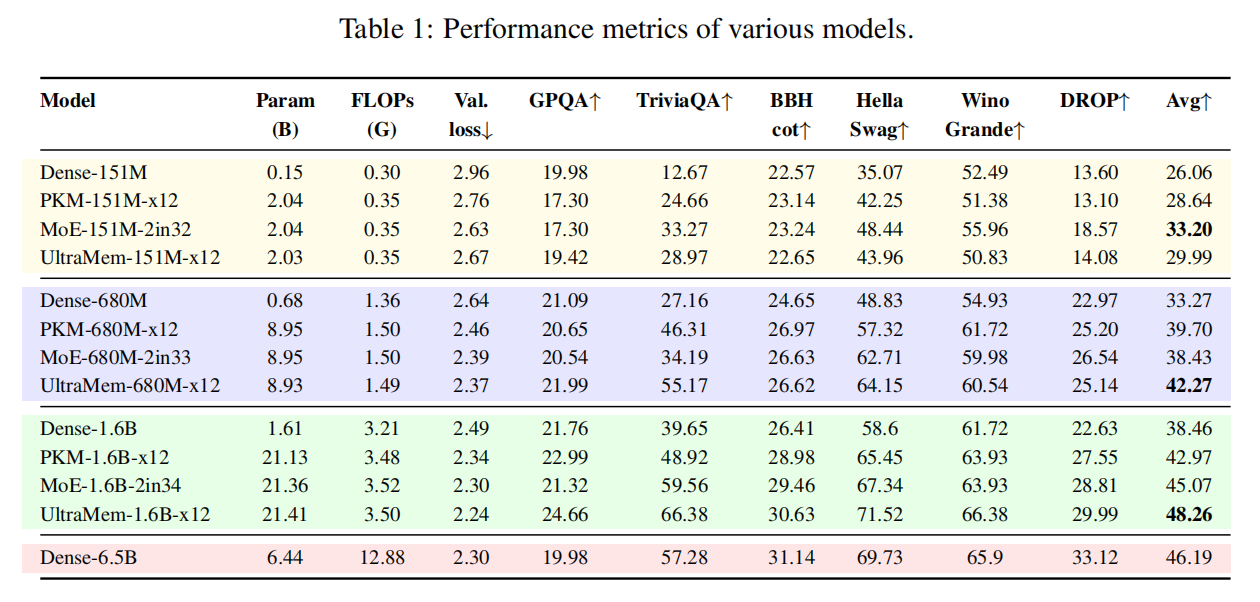
The research team conducted extensive experiments on activation parameters of three sizes: 151M, 680M, and 1.6B. Among them, the total sparse parameters of MoE, PKM, and UltraMem remained at 12 times of the activation parameters.
As shown in the table below, UltraMem demonstrates significant performance advantages at 680M and 1.6B.
How do performance and inference speed of UltraMem change with increase of sparse parameters?
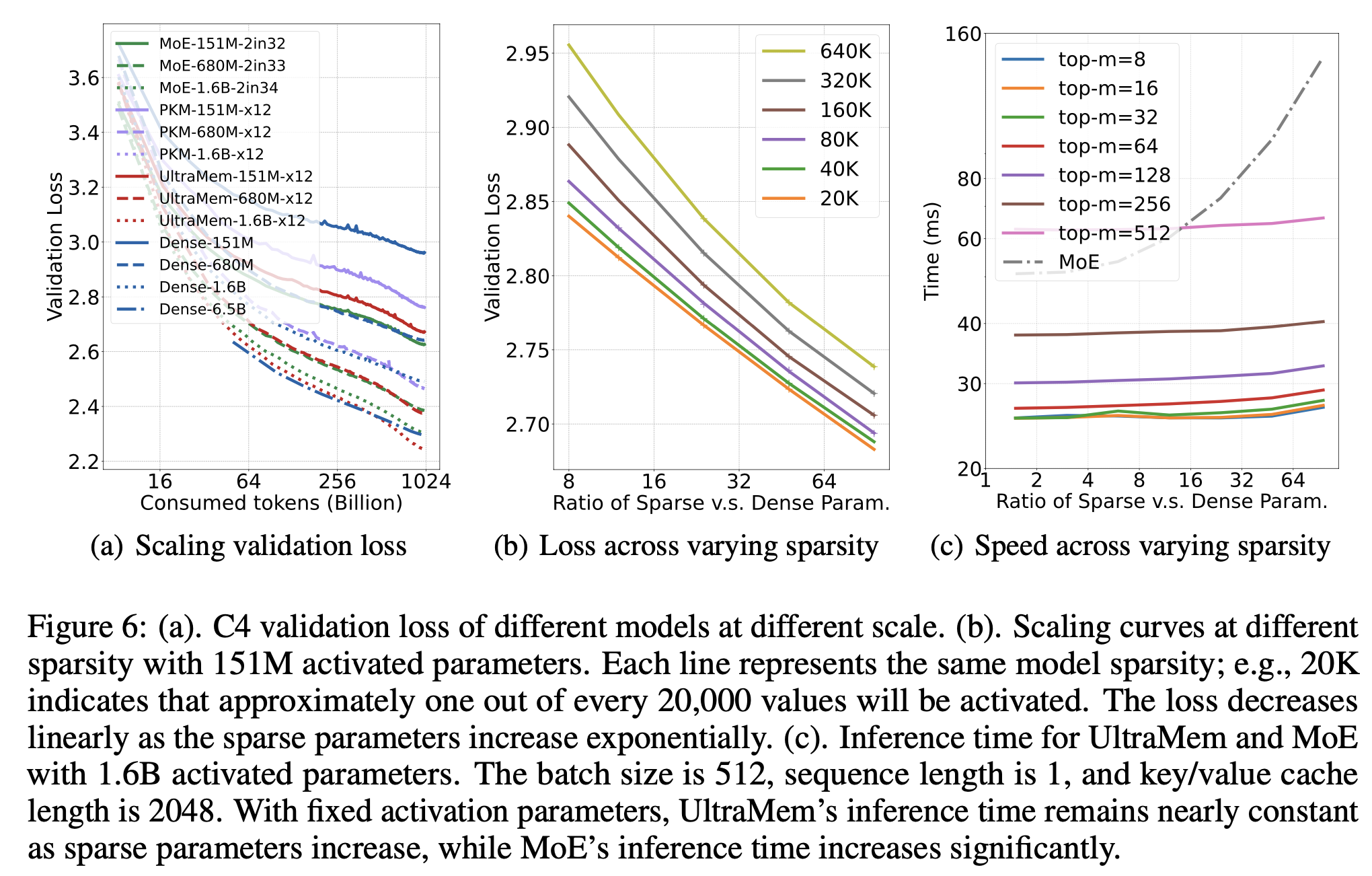
The graph below (b) shows the performance trend of UltraMem. The x-axis represents the ratio of sparse parameters to dense parameters, and each colored line represents a different sparsity level. Sparsity is defined as the number of values divided by the number of values activated by each token. It is observed that there is a logarithmic relationship between the continuous increase of sparse parameters and the decrease in loss. The lower the sparsity, the better the model performance. However, the benefits brought by the continuous decrease of sparsity are gradually saturating.
The graph below (c) shows the variation in inference time of UltraMem. The horizontal axis represents the ratio of sparse parameters to dense parameters. It was observed that when continuously increasing the sparse parameters, the inference time of UltraMem hardly changes, while MoE shows a significant upward trend.
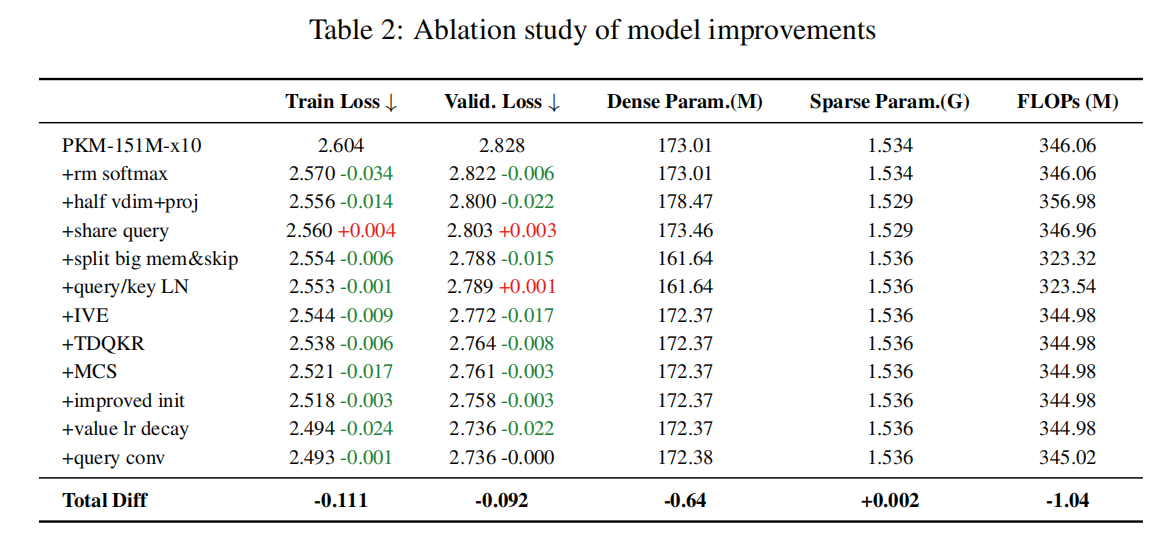
② Ablation experiments
The research team conducted comprehensive ablation experiments on a sparse model with 151M activations and a total parameters of 1.5B. Starting from the original PKM, they progressively incorporated some tricks and the structural improvements mentioned earlier. This resulted in a significant benefit of -0.092 in C4 validation loss, while the sparse parameters and calculation amount are almost unchanged.
In summary, the UltraMem proposed by the research team offers extremely low memory access. As a result, it achieves a speedup of up to 6 times compared with MoE, and reduces the inference cost by up to 83%。 At the same time, in terms of performance, as the model capacity increases, UltraMem outperforms MoE with the same parameters and computational amount, indicating its stronger scalability. This research points to a promising direction for developing more efficient and scalable language models.
4. Final Thoughts
UltraMem can be effectively applied to latency-critical inference scenarios, such as code completion, avoiding the memory access bottlenecks of MoE. Even in general-purpose scenarios, UltraMem shows a significant speed advantage over MoE, except in extreme scenarios where batch size reaches tens of thousands.
Currently, there are still several directions worthy of exploration for the technological evolution of UltraMem, including but not limited to: How to optimize sparse parameters efficiently, how to improve the inference ability of sparse models, and how to activate sparse parameters more optimally, etc. These technical directions could serve as important entry points for subsequent research.
The Doubao (Seed) team remains committed to exploring the endless boundaries of intelligence and unlocking the infinite possibilities of general intelligence.