Selected for ICML Oral!A DOUBAO Team Intern Proposes IR-QLoRA, Introducing Information Theory to LLMs
Selected for ICML Oral!A DOUBAO Team Intern Proposes IR-QLoRA, Introducing Information Theory to LLMs
Date
2024-07-19
Category
Tech
This paper proposes a novel IR-QLoRA for pushing quantized LLMs with LoRA to be highly accurate through information retention. This is the first time the perspective of information theory has been introduced and theories related to information entropy are utilized to examine and measure the quantization of large models. The paper has been selected for an oral presentation at ICML 2024. The first author of the paper is an intern with the speech group of ByteDance's Doubao Team (Seed) and a candidate in the ByteDance Scholars Program. Teachers and students from the State Key Laboratory of Complex & Critical Software Environment at Beihang University also contributed to the research.
One of the three major conferences in the field of machine learning, ICML, was held in Vienna from July 21 to July 27. Among the selected works, the paper titled "Accurate LoRA-Finetuning Quantization of LLMs via Information Retention," a collaboration between the speech group of ByteDance's Doubao Team (Seed) and academic institutions, was accepted for an oral presentation.
This ICML received a total of 9,653 paper submissions, with 2,609 accepted, and only 144 selected for oral presentations, accounting for 1.5% of the total submissions. And this selected paper proposes a novel IR-QLoRA for pushing quantized LLMs with LoRA to be highly accurate through information retention.
Comprehensive experiments show that IR-QLoRA can significantly improve accuracy across LLaMA and LLaMA2 families under 2-4 bit-widths, e.g., 4-bit LLaMA-7B achieves 1.4% improvement on MMLU (Massive Multitask Language Understanding) compared with the SOTA (state-of-the-art) methods.The significant performance gain requires only a tiny 0.31% additional time consumption, which means inference performance is improved significantly with almost no increase in computational load.
In the meantime, IR-QLoRA enjoys excellent versatility, compatible with various frameworks (e.g., NormalFloat and Integer quantization) and brings general accuracy gains.
Regarding the reasons for this selection, the main participant, Hunter, believes that this is the first time the perspective of information theory has been introduced and theories related to information entropy are utilized to examine and measure the quantization of large models. In addition, in terms of research depth, many previous compression schemes were relatively more engineering-oriented. The theoretical foundation and analysis of IR-QLoRA are more robust, and the team conducted analyses on models with different structures based on their findings, making the research work more comprehensive.
This achievement was a collaborative effort between ByteDance and Beihang University through a university-enterprise partnership. The first author of the paper, Hunter, is an intern in the speech group of the Doubao Team. Some contributors are from the National Key Laboratory of Complex Systems and Critical Software at Beihang University, and they have previously participated extensively in ByteDance's machine learning research projects.
- Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
- Link to the paper: https://arxiv.org/abs/2402.05445
1. How to reduce deployment costs in the era of large models?
The IR-QLoRA project was initiated in 2023. At that time, with the rise of LLMs, ByteDance team members were paying close attention, particularly to implementation issues. They hoped for a better model compression solution that could enable model sparsification, save memory and memory access consumption, and lower deployment barriers.
With these targets in mind, the Bytedance team collaborated with Beihang University, known for their expertise in quantization-related topics, to jointly initiate this research work.
LoRA (Low-Rank Adaptation of Large Language Models) is a mainstream method that has been continuously researched and applied in various fields since its introduction. However, previous methods often led to significant degradation of quantized LLMs, even making it difficult to benefit from LoRA fine-tuning.
The team believes that the current low-rank fine-tuning quantization of LLMs has not yet reached its full potential in terms of accuracy, with significant information loss during the quantization process. To address this, the team undertook the following efforts.
- First, propose an Information Calibration Quantization (ICQ) technique. By calibration by entropy maximization, ICQ enables quantizers for the LLM to retain the original information from the original parameters to quantized ones.
- Also, propose the Information Elastic Connection (IEC) to enhance the information recovery capability of LoRA. IEC works together with LoRA, which performs parameter-free elastic transformations to utilize the information of original features and diversify the transformation form of LoRA.
See below overview of IR-QLoRA. On the left, the blue section represents the Information Calibration Quantization (ICQ) module, while on the right, the brown section represents the Information Elastic Connection (IEC) part.
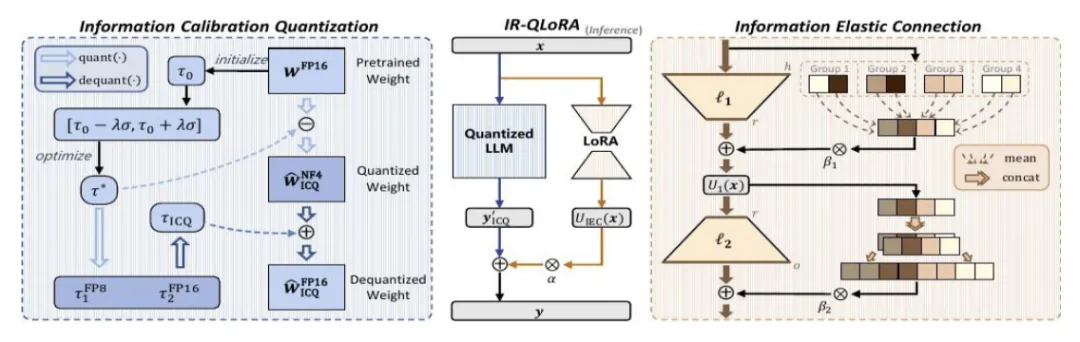
2. Specific improvements and experiment results
Traditionally, the LLMs are quantized directly from pre-trained models, where the low-bit discretization of the parameters causes accuracy degradation. Existing quantization methods attribute the degradation to the numerical quantization error. However, the information loss caused by quantization is always neglected.
At the core, the quantized weights of LLMs are expected to reflect the information carried by original counterparts, but reduced bit-width severely constrains the representation capabilities. The Information Calibration Quantization (ICQ) technique is to mitigate the degeneration caused by information loss.
Specifically, a calibration constant 𝜏 is introduced to the quantizer, liberating its flexibility to retain information fully. The quantization process it engages in can be expressed as follows:
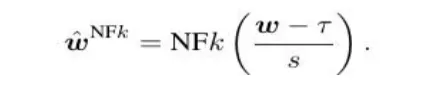
Directly solving the objective in this equation is, of course, significantly complex and time-consuming. Therefore, the team then presents a two-step strategy for calibrating the quantizers of LLMs blockwisely by the information entropy maximization.
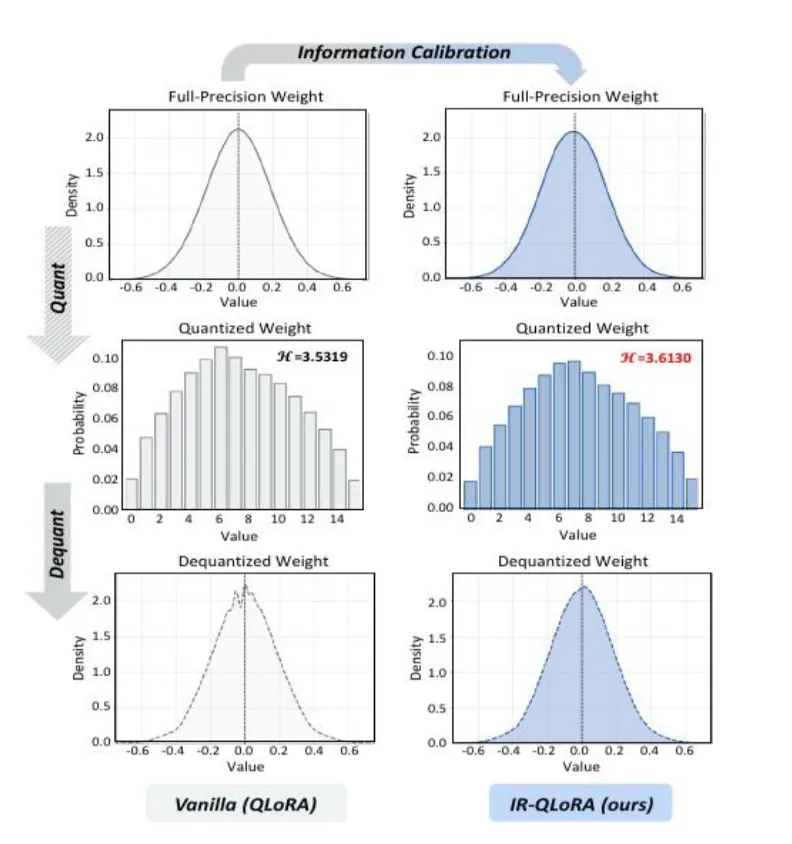
As the figure below shows, the quantized weights calibrated by ICQ derive increased information following the dequantization.The H (information entropy) value is larger, meaning that the compressed 4-bit weights are as close as possible to the original weights in terms of information content, allowing for a more accurate recovery of the original distribution.
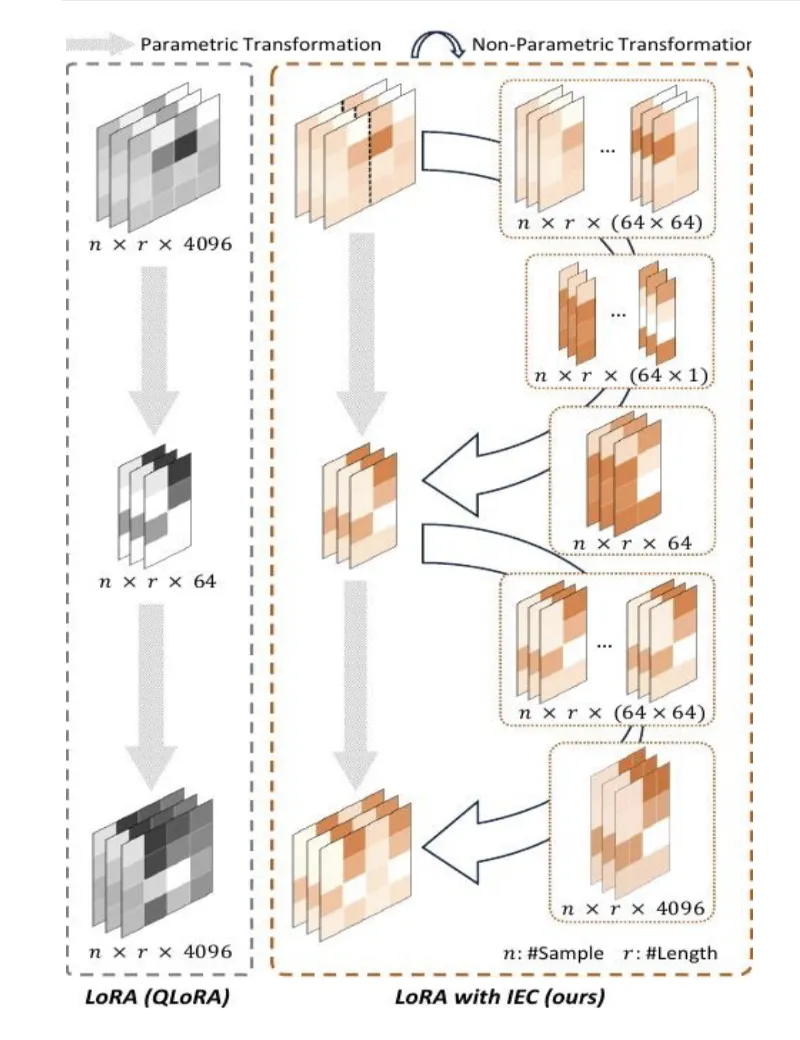
In addition to information loss in quantized LLM, the limited representation capability of the finetuneable LoRA also hinders information recovery. To be specific, low-rank parameters reduce the computational and storage costs associated with direct fine-tuning, but the transformed matrix also loses access to the original representation information.
To bolster the representation capacity of LoRA, aiding in recovering information of quantized LLMs while maintaining its lightweight nature, the team introduces an effective Information Elastic Connection (IEC), which constructs a parameter-free connection for LoRA, facilitating information utilization derived from quantized LLM and diversifying the information transformation.
As illustrated, in this structure, the matrix in LoRA can be accessed directly and utilize the original information extracted by quantized LLM. Compared to the previous methods, the parameter-free IEC is more diversified, further enhancing the information representation of the quantized LLM.
The team extensively evaluates the accuracy and efficiency of IR-QLoRA through experiments. The following figure shows the accuracy comparison of LLaMA on the MMLU benchmark finetuned with the Alpaca dataset.
Take the compression approach of the 16-bit LLaMA-7B model as an example. The average score of IR-QLoRA exceeds QA-LoRA by 1.4%. Its performance is not inferior to QA-LoRA across other quantizers.
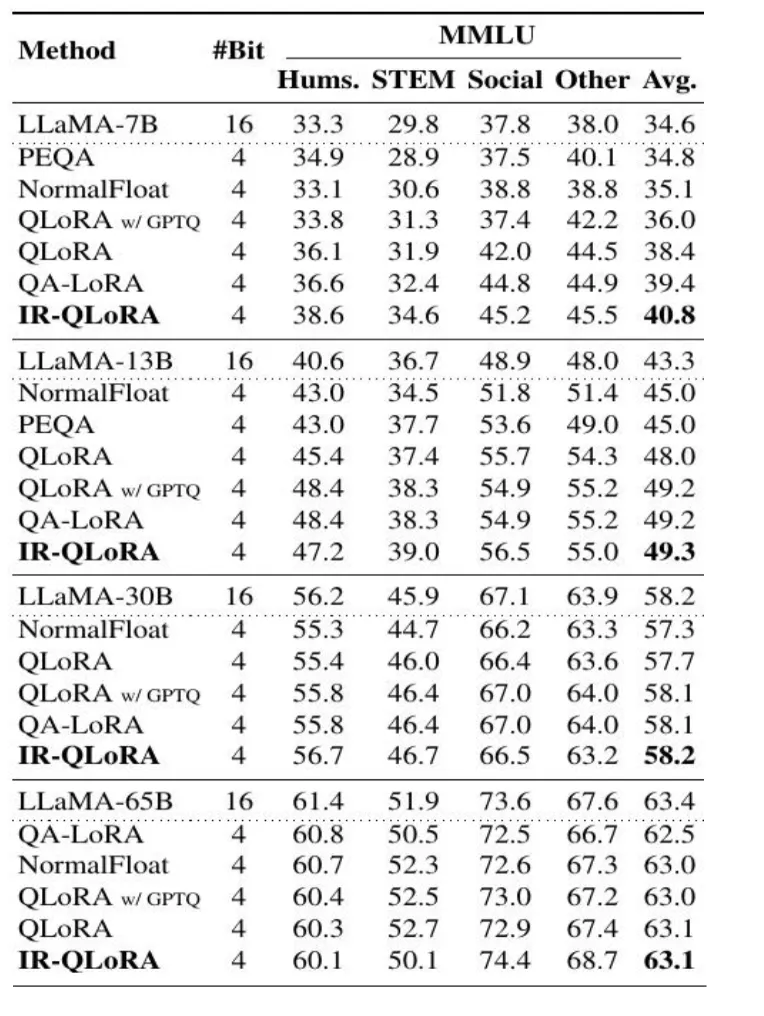
When using Flan v2 as the fine-tuning dataset, QA-LoRA also achieves better results.
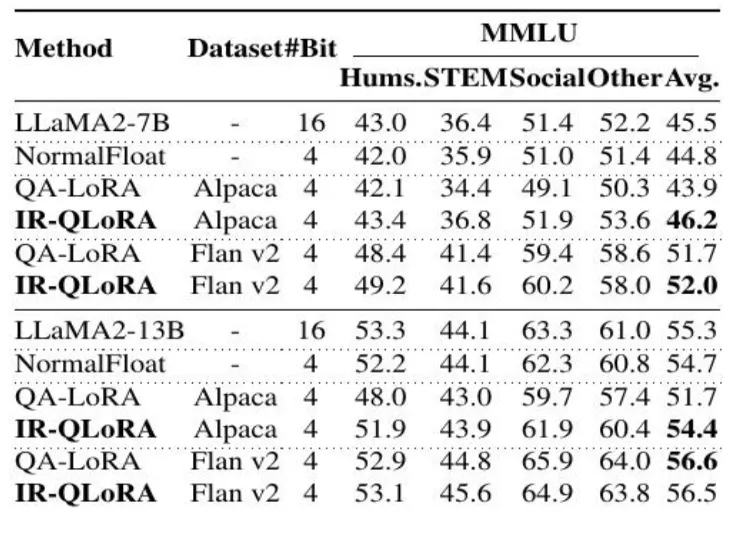
The following figure shows the performance comparison of QA-LoRA and other methods on MMLU of LLaMA2. The result demonstrates advantages in every individual metric and exhibits strong generalization.
It's worth mentioning that the new generation of LLaMA3 has also been used by the team for evaluation upon its release, and it has achieved stable results.
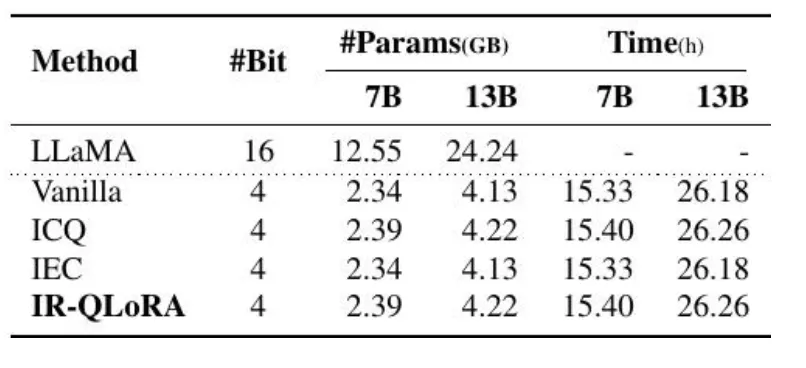
Regarding the cost issue of QA-LoRA, the team has also conducted research.
It turns out that the additional storage introduced by ICQ is minor, increasing only by 2.04% on the 4-bit LLaMA-7B. The optimization process for τ adds only 0.31% for LLaMA-13B and 0.46% for LLamA-7B. IEC just introduces 2 additional parameters per layer, which can be negligible in the whole model.
Results on the ablation efficiency of different sizes:
In addition to the above research, the team has also conducted tests on more benchmarks, such as CommonsenseQA, and explored issues, such as the differences between IR-QLoRA and Q-LoRA under Ultra-low Bit-width.
Generally speaking, extensive experiments validate that IR-QLoRA delivers convincing accuracy improvements across the LLaMA and LLaMA2 families, even with 2-4 bit-widths, accompanied by a minimal 0.45% increase in time consumption.
Meanwhile, IR-QLoRA seamlessly integrates with various quantization frameworks. It significantly advances the accuracy of LLM LoRA, facilitating practical deployment in resource-constrained scenarios. The application directions include real-time text Q&A, voice Q&A, and other scenarios with high latency requirements.
Explore the future development of efficient deep learning. Hunter believes that AI may be dominated by the Foundation model in the long term. As the boundary of the model's capabilities continuously expands, correspondingly, a more efficient framework and deployment method is required to make the best use of the limited storage and computational resources as much as possible to obtain better results. Some research teams or start-ups focus on small, unilateral model research during this process. At the same time, quantization and sparsification render model compression equally important. These types of research have great potential and require the participation of talents with various disciplinary backgrounds.
3. "Without the help of the team, I almost couldn't submit it in time."
Hunter, the lead author of this paper, is an intern in the speech group of the ByteDance Doubao (Seed) Team. Previously, he was also a selected candidate for the ByteDance Scholars Program. Prior to IR-QLoRA, Hunter participated in a school-enterprise project.
Regarding this cooperation, a mentor proposed the research direction - a low-bit compression approach for LLM deployment. Hunter put forward the initial idea and model design and completed the model implementation. Another co-lead author, Macaronlin, who has participated in many competitions, is mainly responsible for large-scale engineering work as well as alignment and optimization of formulas and codes. He delivers more robust and adaptable codes by solving plenty of cumbersome tasks.
According to Hunter, the team has provided huge support, such as computational resources and flexibility that scientific research institutions and other organizations may find difficult to provide. He says, "In aspects such as scenario exploration, dataset usage, pipeline, and the way to properly call pre-trained models, many colleagues have provided a lot of practical suggestions."
"This is also one of the reasons why we were able to submit it two days before the ICML deadline," he adds, "because it takes a long time to run the model, and without the help of the team, we almost couldn't submit it in time."
Regarding team climate, Hunter believes that the first keyword is flexibility.
According to his recollection, the team's research direction emphasizes practical value, but there is no rigid requirement for reaching certain targets in their daily work. Instead, they welcome considerable discussion to establish specific goals that are reasonable, novel and valuable, rather than dumping engineering work onto interns or university partners.
"Good goals are half the battle, and the company gives us full respect in research and exploration," says Hunter.
Besides flexibility, the team also maintains long-term patience for research.
Hunter mentions that they made limited progress at the beginning of the project. Still, mentors and the team provided sufficient space for exploration, and interns were allowed to choose their research direction flexibly. "Such patience has greatly empowered interns," he adds.
Finally, the style of organizational management is also relatively flexible.
Taking this ICML Oral paper as an example, the two main contributors do not have the same mentor, but each has their own advantages in theoretical research, code and engineering implementation. Therefore, the team has lined us up and involved more students and mentors to obtain the result more quickly.
Hunter believes that ByteDance has attracted many top talents with different backgrounds and expertise worldwide, which brings perspective to LLM research in the team. The atmosphere is also more open.
Apart from the selected IR-QLoRA paper this time, other ByteDancers' papers selected at ICML 2024 include:
Outlier-aware Slicing for Post-Training Quantization in Vision Transformer
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Two Stones Hit One Bird: Bilevel Positional Encoding for Better Length Extrapolation
Self-Infilling Code Generation
Diffusion Language Models Are Versatile Protein Learners
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Boximator: Generating Rich and Controllable Motions for Video Synthesis
MagicPose: Realistic Human Pose and Facial Expression Retargeting with Identity-aware Diffusion
GroupCover: A Secure, Efficient and Scalable Inference Framework for On-device Model Protection based on TEES
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Bridging Model Heterogeneity in Federated Learning via Uncertainty-based Asymmetrical Reciprocity Learning
ByteDance will have an on-site booth during ICML 2024, and some colleagues working on machine learning and deep learning will attend the conference in Vienna. The on-site display and demos include ByteGen, DepthAnything2, SeedTTS, DPLM, and others. Our booth is at Booth Number 107, and everyone is welcome to communicate with us in person.
The ByteDance Doubao (Seed) Team is hiring. We seek top minds who aspire to "change the world with technology." Please submit your CV and learn more.
Note: All colleagues mentioned in this article are pseudonymized.