Up to 20 times higher throughput! Doubao (Seed) team releases a brand new RLHF framework, now open-sourced!
Up to 20 times higher throughput! Doubao (Seed) team releases a brand new RLHF framework, now open-sourced!
Date
2024-11-01
Category
Technology Launch
Reinforcement learning (RL) plays a key role in enhancing the complex reasoning ability of large language models. However, the intricate computing process of RL and the limitations of existing systems also pose challenges to training and deployment. Traditional RL/RLHF systems suffer from limitations in flexibility and efficiency, making it difficult to adapt to the needs of emerging algorithms and fully unleash the potential of large language models.
Recently, the Doubao (Seed) team at ByteDance, in collaboration with the University of Hong Kong, proposed HybridFlow (open source project name: veRL), a flexible and efficient RL/RLHF framework. This framework adopts a hybrid programming model that combines the flexibility of Single-Controller and the efficiency of Multi-Controller to better implement and execute multiple RL algorithms, significantly improve training throughput, and reduce development and maintenance complexity. Experimental results show that HybridFlow achieves a 1.5x to 20x increase in training throughput when running various RL(HF) algorithms, compared to the SOTA baseline.
From ChatGPT [1] to o1 and other large language models, reinforcement learning (RL) algorithms play a critical role in improving model performance and adaptability. Introducing RL methods in the post-training stage of large models has become an important way to improve model quality and alignment [2, 3].
However, as model sizes continue to grow, RL algorithms face dual challenges of flexibility and performance in large model training.
Therefore, it is crucial to develop an efficient and flexible RL training framework for large language models. This requires not only the efficient execution of complex distributed computing processes but also the flexibility to adapt to different RL algorithms to meet evolving research needs.
The ByteDance Doubao (Seed) Team and HKU recently announced the result of their joint research: HybridFlow - a flexible and efficient large language model RL training framework, that is compatible with various training and inference frameworks, and supports flexible model deployment and various RL algorithm implementations.
HybridFlow adopts a hybrid programming model, combining the flexibility of a single controller with the efficiency of multiple controllers, and decouples the control flow from the computation flow. Based on Ray's dynamic computation graph and heterogeneous scheduling capabilities, HybridFlow efficiently implements and executes various RL algorithms by encapsulating the distributed computation of a single model, unifying data partitioning among models, and supporting asynchronous RL control flow. It replicates computation modules and supports different model deployment methods, greatly enhancing system flexibility and development efficiency.
Experimental results show that HybridFlow, under various model sizes and RL algorithms, achieves a 1.5x to 20x increase in training throughput compared to other frameworks.
The paper has now been accepted by EuroSys 2025 and the code repository has been made available to the public.
HybridFlow: A Flexible and Efficient RLHF Framework
Paper link: https://team.doubao.com/zh/publication/hybridflow-a-flexible-and-efficient-rlhf-framework?view_from=research
Code link: https://github.com/volcengine/veRL
1. The complex computational process of RL (Post-Training) introduces new challenges for LLM training.
In deep learning, DataFlow is an important computational model abstraction that represents how data is processed through a series of complex calculations to achieve specific functions. The computation of a neural network is a typical example of DataFlow, which can be described by a Computational Graph, where nodes represent computational operations and edges represent data dependencies.
The computational process of a large language model RL is more complex than traditional neural networks. In RLHF, multiple models need to be trained simultaneously, such as Actor, Critic, Reference Policy, and Reward Model, and a large amount of data needs to be transferred between them. These models involve different computation types (forward and backward passes, optimizer updates, autoregressive generation, etc.) and may adopt different parallel strategies.
Traditional distributed RL usually assumes that models can be trained on a single GPU, or uses data parallelism [4,5], combining the control flow and computation flow in the same process. This approach works well with small-scale models. However, for large models, training requires complex multi-dimensional parallelism and extensive distributed computing, which are difficult to address with traditional methods.
2. HybridFlow decouples control flow and computation flow for flexibility and efficiency
Large language model RL is essentially a two-dimensional DataFlow problem: high-level control flow (describing the process of the RL algorithm) + low-level computation flow (describing distributed neural network computation).
The recently open-sourced RLHF frameworks, such as DeepSpeed-Chat [6], OpenRLHF [7], and NeMo-Aligner [8], have adopted a unified Multi-Controller architecture. Each computing node manages computation and communication independently, reducing the overhead of control scheduling. However, the control flow and computation flow are highly coupled, and when designing new RL algorithms that combine the same computation flow with different control flows, it is necessary to rewrite the computation flow code and modify all related models, increasing the development difficulty.
Unlike the previous framework, HybridFlow adopts a mixed programming model, with control flow managed by a Single-Controller with a global view, making it simple and efficient to implement new control flows. The computation flow is handled by the Multi-Controller to ensure efficient execution of computations, and can be reused in different control flows.
Although this may bring some control scheduling overhead compared to a purely multi-controller architecture, HybridFlow reduces the amount of data transmission between control flow and computation flow by optimizing data transfer, balancing flexibility and efficiency.
3. System design 1: Hybrid Programming Model (innovation in programming model)
- Encapsulate single model distributed computing
In HybridFlow, the distributed computation of each model (such as Actor, Critic, reference policy, reward model, etc.) is encapsulated as independent modules, called model classes.
These model classes inherit from the basic ParallelWorker class (such as 3DParallelWorker, FSDPWorker, etc.), encapsulating the forward and backward pass, optimizer updates, and autoregressive generation of the model through abstract API interfaces. This encapsulation method improves code reusability and facilitates model maintenance and expansion.
For different RL control flows, users can directly reuse encapsulated model classes and customize the numerical calculations required for different algorithms. Currently, HybridFlow can use Megatron-LM [13] and PyTorch FSDP [14] as training backends, and vLLM [15] as the autoregressive generation backend, supporting users to use scripts for training and inference in other frameworks for custom extensions.
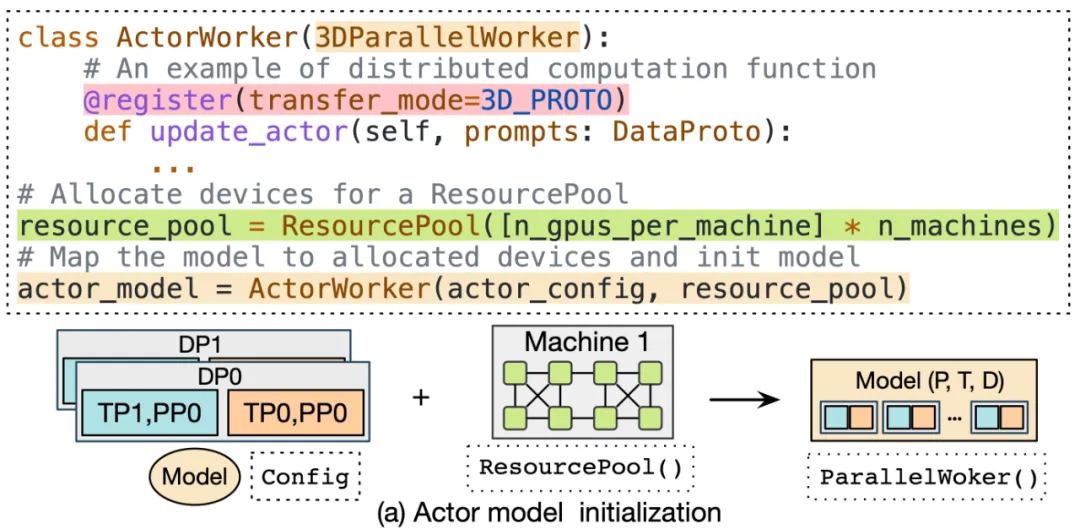
- Achieve flexible model deployment
HybridFlow provides the concept of a ResourcePool, which can virtualize a group of GPU resources and allocate computing resources for each model. Different instances of resource pools can correspond to different sets of devices, supporting the deployment of different models on the same or different groups of GPUs. This flexible model deployment method meets the resource and performance requirements of different algorithms, models, and hardware environments.
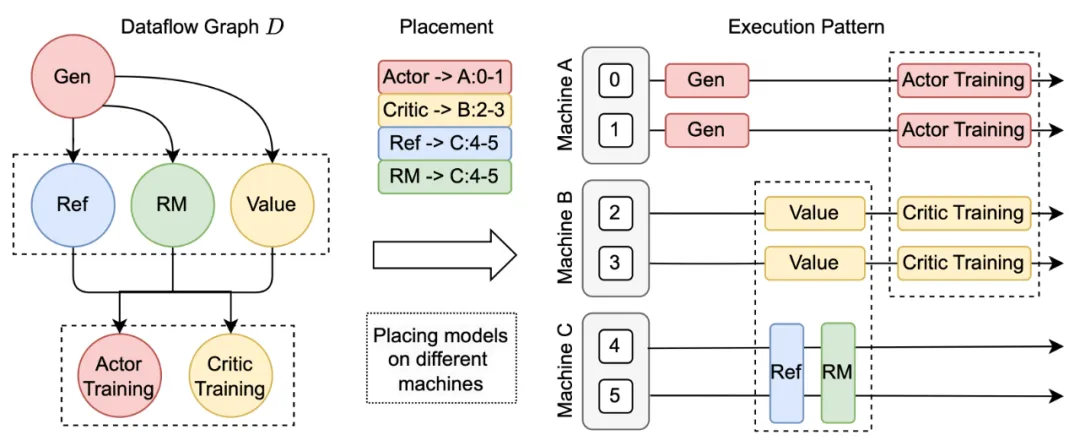
- Segment data across unified models
In the computation process of large-scale RL models, the data transmission between different models involves complex many-to-many broadcasting and data resharding.
To address this issue, HybridFlow has designed a universal data transfer protocol, including two parts: collection and distribution.
By registering the corresponding transfer protocol on the operations of the model class, such as: @register(transfer_mode=3D_PROTO), HybridFlow can centrally manage the collection and distribution of data at the controller layer (Single-Controller), achieve automatic resharding of data between models, and support model communication under different parallelism levels.
The HybridFlow framework now supports multiple data transmission protocols, covering most data re-segmentation scenarios. At the same time, users can flexibly customize the collection and distribution functions to extend them to more complex data transmission scenarios.
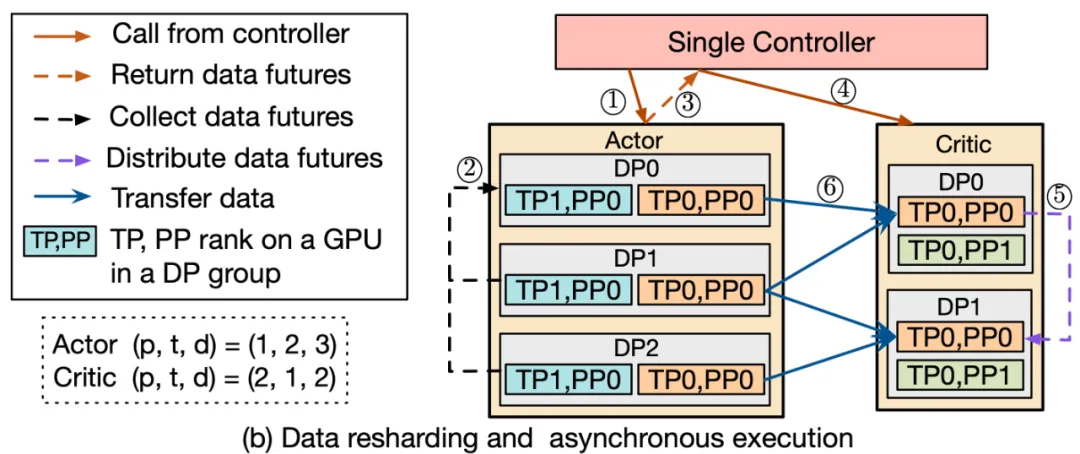
- Support asynchronous RL control flow
In HybridFlow, the control flow part adopts a single controller architecture, which can flexibly implement asynchronous RL control flow.
When the model is deployed on different sets of devices, different model computations can be executed in parallel, which increases the system's parallelism and efficiency. For models deployed on the same group of devices, HybridFlow achieves sequential execution through a scheduling mechanism to avoid resource contention and conflicts.
- Implement various RL control flow algorithms flexibly with a small amount of code
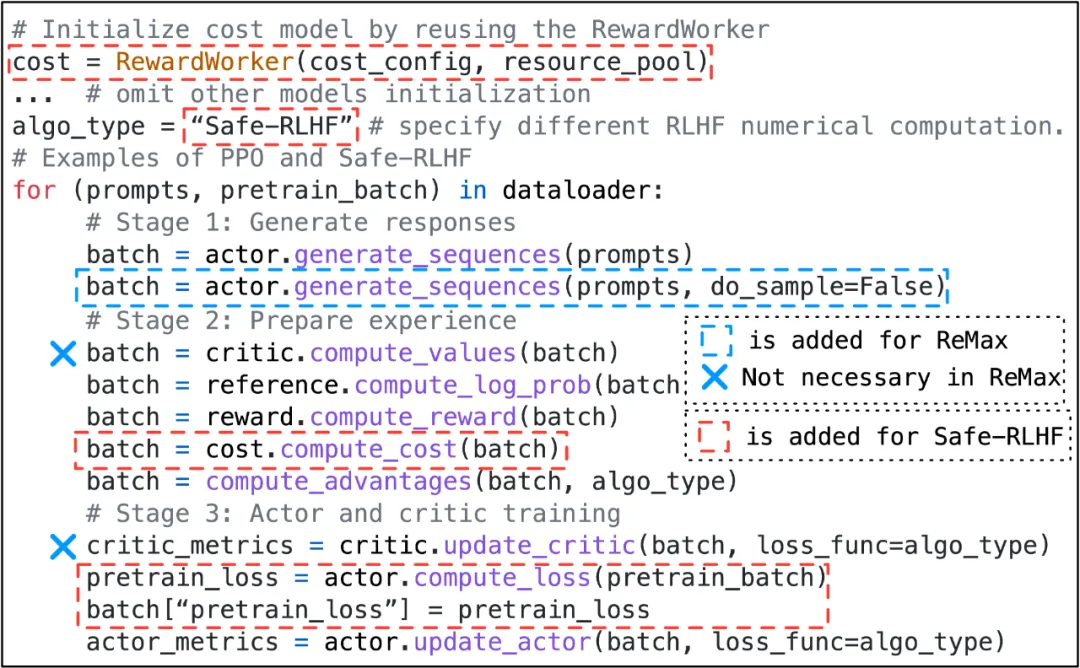
Thanks to the design of the hybrid programming model, HybridFlow can easily implement various RLHF algorithms, such as PPO [9], ReMax [10], Safe-RLHF [11], GRPO [12], etc. Users only need to call the API interface of the model class, write control flow code according to the algorithm logic, without having to worry about the underlying distributed computing and data transmission details.
For example, implementing the PPO algorithm only requires a small amount of code, which can be accomplished by calling functions such as actor.generate_sequences and critic.compute_values. At the same time, users only need to modify a small amount of code to migrate to the Safe-RLHF, ReMax, and GRPO algorithms.
4. System design 2: 3D-HybridEngine (a hybrid training and inference technology) reduces communication memory overhead
In Online RL algorithms, the Actor model needs to switch frequently between the training and generation (Rollout) phases, and the two phases may use different parallel strategies.
Specifically, during the training phase, it is necessary to store gradients and optimizer states, which may lead to an increase in model parallel size (MP). In contrast, during the generation phase, the model does not need to store gradients and optimizer states, so both MP and data parallel size (DP) can be smaller. Therefore, between these two phases, model parameters need to be resharded and redistributed. Relying on traditional communication group construction methods can result in additional communication and memory overhead.
Additionally, in order to use model parameters under the new parallel configuration, an all-gather operation is typically required across all GPUs, which incurs significant communication overhead and increases transition time.
To address this issue, HybridFlow has designed the 3D-HybridEngine to enhance the efficiency of both the training and generation processes.
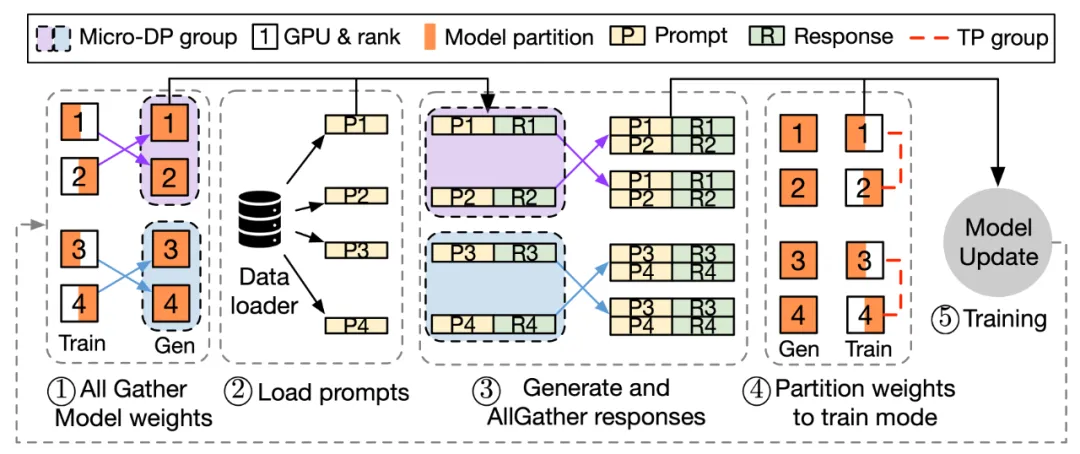
Note: The process of one iteration in the 3D-HybridEngine.
The 3D-HybridEngine achieves zero-redundancy model parameter reorganization by optimizing parallel grouping methods, which includes the following steps:
- Defining Different Parallel Groups
During the training and generation phases, the 3D-HybridEngine uses different three-dimensional parallel configurations, including pipeline parallelism (PP), tensor parallelism (TP), and data parallelism (DP) sizes. The parallel configuration for the training phase is 𝑝-𝑡-𝑑. In the generation phase, we introduce a new micro data parallel group (Micro DP Group, dg) to handle the reorganization of Actor model parameters and data. The parallel configuration for the generation phase is 𝑝𝑔-𝑡𝑔-𝑑𝑔-𝑑.
- Reorganizing Model Parameters
By cleverly redefining parallel grouping for the generation phase, each GPU can reuse the existing model parameter shards from the training phase during the generation phase. This avoids storing additional model parameters in GPU memory, eliminating memory redundancy.
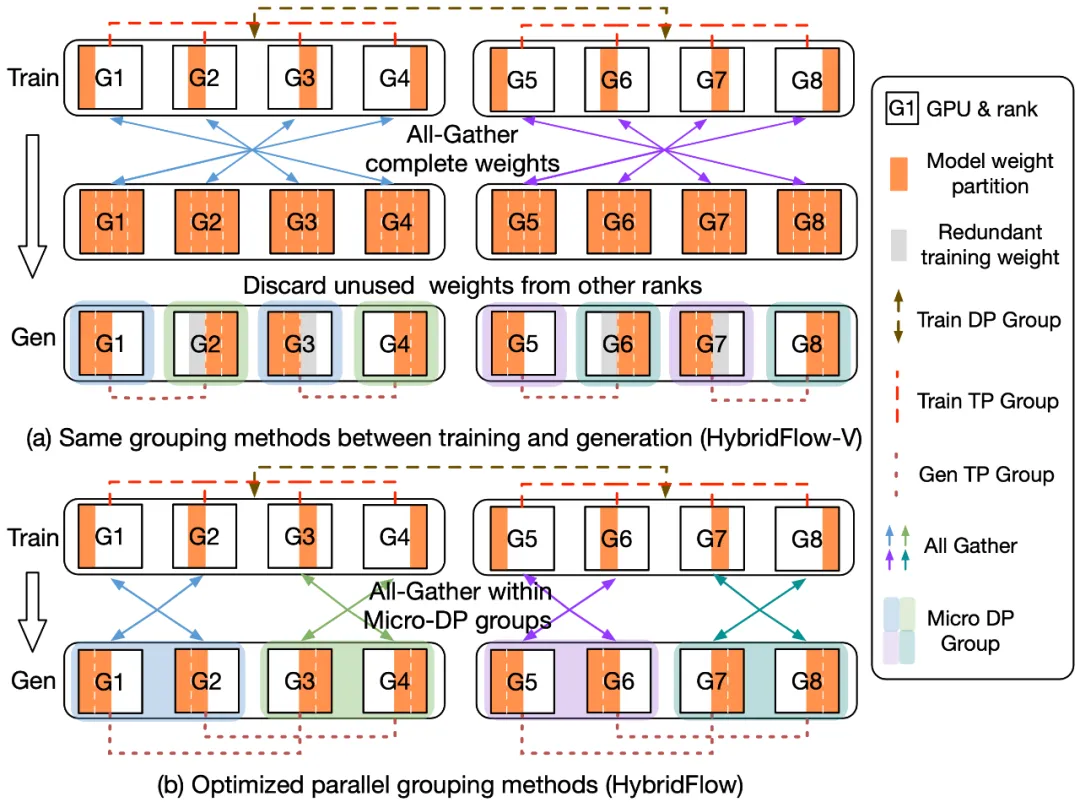
- Reducing Communication Overhead
During the parameter reorganization process, the 3D-HybridEngine performs All-Gather operations only within each Micro Data Parallel Group (Micro DP Group), rather than across all GPUs. This significantly reduces the amount of communication, decreases transition time, and improves overall training efficiency.
5. Experimental Results: HybridFlow Accelerates Training While Providing Flexibility
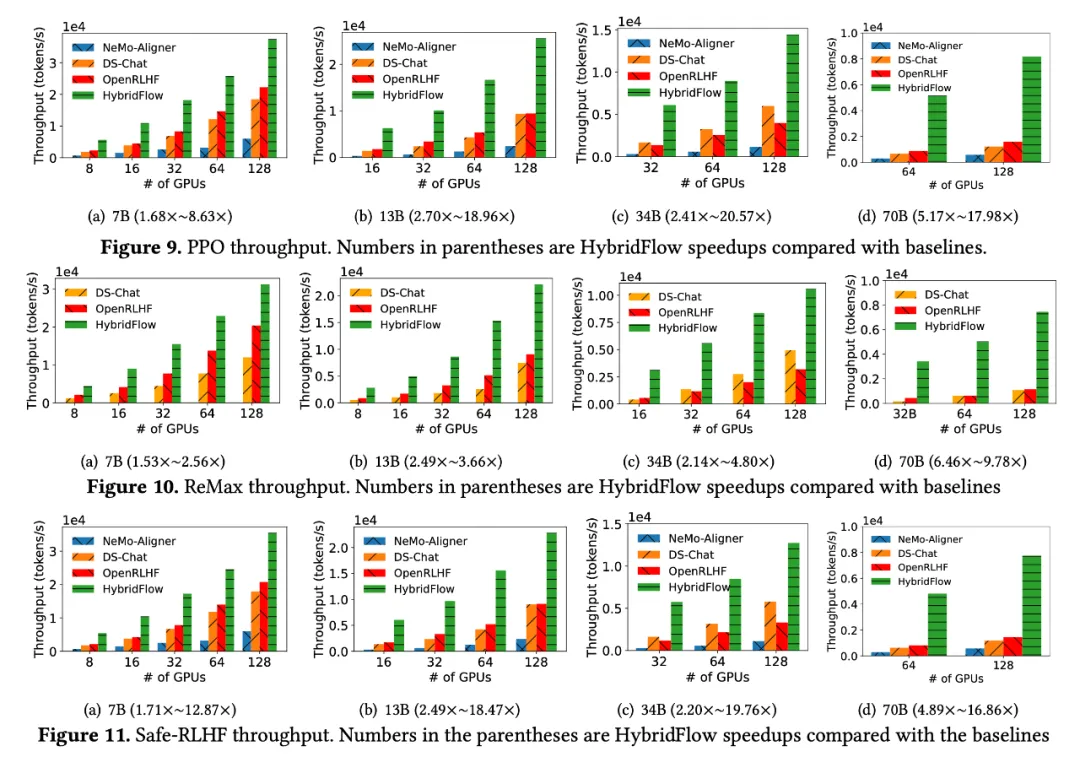
The team conducted comparative experiments on a cluster of 16 A100 GPUs, evaluating HybridFlow against mainstream RLHF frameworks (DeepSpeed-Chat [6] v0.14.0, OpenRLHF [7] v0.2.5, and NeMo-Aligner [8] v0.2.0). The experiments covered LLMs of various model sizes (7B, 13B, 34B, 70B) and different RLHF algorithms (PPO [9], ReMax [10], Safe-RLHF [11]).
In all experiments, the Actor, Critic, Reference Policy, and Reward Model used models of the same size. For more experimental configurations and test details, please refer to the full paper.
- Higher End-to-End Training Throughput
The results show that HybridFlow significantly outperforms other frameworks across various model sizes and RLHF algorithms, achieving higher training throughput.
Whether using the PPO, ReMax, or Safe-RLHF algorithm, HybridFlow consistently leads in average training throughput across all model sizes, with improvements ranging from 1.5 to 20 times compared to other frameworks.
As the GPU cluster size increases, HybridFlow's throughput scales well. This is attributed to its flexible model deployment, which fully utilizes hardware resources to achieve efficient parallel computation. Additionally, HybridFlow supports multiple distributed parallel frameworks (Megatron-LM [13], FSDP [14], vLLM [15]), meeting the computational needs of different model sizes.
- HybridEngine Effectively Reduces Overhead
By analyzing the transition time of the Actor model during the training and generation phases, the team found that HybridFlow's 3D-HybridEngine's zero-redundancy model parameter reorganization technology effectively reduces the reshuffling and communication overhead of model parameters between the two phases.
Compared to other frameworks, the transition time was reduced by 55.2%, and for the 70B model, the transition time was decreased by 89.1%.

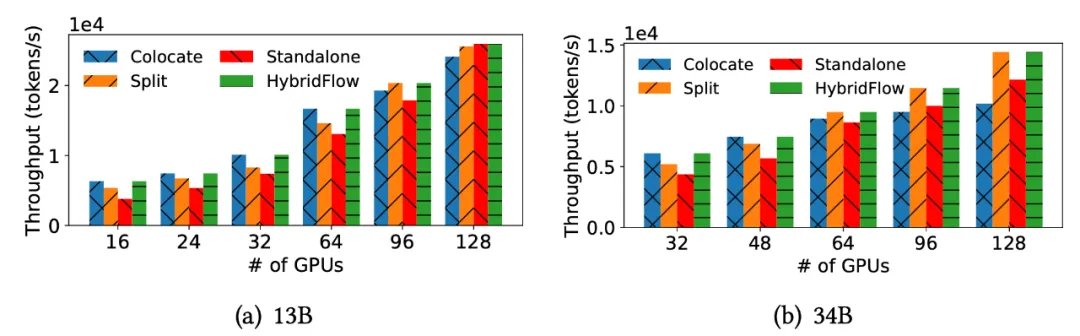
- Three Insights from Comparing Different Model Deployment Strategies
The team compared different model deployment strategies and summarized three key insights regarding model deployment and GPU allocation:
- Allocating more GPUs to the Actor model can shorten the critical path;
- The Colocate mode can maximize GPU utilization in relatively small-scale clusters;
- Deploying the Actor and Critic models on different devices in large-scale clusters can improve scalability.
It is worth mentioning that HybridFlow is also applicable to a broader range of RL training scenarios. With the advent of the o1 model, there is increasing industry focus on reasoning capabilities and RL. The team will continue to explore and experiment in these related scenarios.
6. In Conclusion
This achievement comes from the Doubao Foundation Model team, with the first author of the paper being Ming, an intern in the team, who is currently studying at the University of Hong Kong.
"I had just joined the company when I was given the opportunity to work on such an important system. It was a rare opportunity," he shared.
Ming further added, "There are many experts in the team, and no matter what the problem is, you can definitely find someone to discuss it with. This experience not only taught me a lot of new technologies but also allowed me to go through the full cycle of an industrial-level open-source project, from initiation to release. Everyone is willing to help, and each of them is my mentor."
Currently, the Doubao Foundation Model team continues to attract outstanding talents. The team atmosphere is characterized by being hardcore, open, and full of innovation. The team hopes to work with tech talents who possess innovation and responsibility to make more progress and achievements in improving the efficiency of large model training.
References
[1] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[2] Long Ouyang, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
[3] Yuntao Bai, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022).
[4] Eric Liang, et al. 2018. RLlib: Abstractions for distributed reinforcement learning. In International conference on machine learning. PMLR, 3053–3062.
[5] Eric Liang, et al. 2021. RLlib Flow: Distributed Reinforcement Learning is a Dataflow Problem. Advances in Neural Information Processing Systems 34 (2021), 5506–5517.
[6] Zhewei Yao, et al. 2023. DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales. arXiv preprint arXiv:2308.01320 (2023).
[7] Jian Hu, el al. OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework. arXiv preprint arXiv:2405.11143
[8] NVIDIA Corporation. 2024. NeMo-Aligner: Scalable toolkit for efficient model alignment. https://github.com/NVIDIA/NeMo-Aligner
[9] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017).
[10] Ziniu Li, et al. 2023. ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models. arXiv preprint arXiv: 2310.10505 (2023).
[11] Josef Dai, et al. 2024. Safe RLHF: Safe Reinforcement Learning from Human Feedback. In The Twelfth International Conference on LearningRepresentations. https://openreview.net/forum?id= TyFrPOKYXw
[12] Zhihong Shao, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024).
[13] Mohammad Shoeybi, et al. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053 (2019).
[14] Adam Paszke, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
[15] Woosuk Kwon, et al. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles. 611–626.