Comet has been deployed in large-scale clusters, saving millions of GPU hours! MoE communication optimization technology COMET is now open-source!
Comet has been deployed in large-scale clusters, saving millions of GPU hours! MoE communication optimization technology COMET is now open-source!
Date
2025-03-10
Category
Technology Launch
The Mixture-of-Experts (MoE) architecture is currently a key direction in the industry for scaling large models. However, its significant communication overhead during distributed training severely limits training efficiency and increases costs. To overcome this bottleneck, the Doubao (Seed) team has introduced a groundbreaking communication optimization system—COMET. By leveraging fine-grained computation-communication overlapping, COMET achieves up to 1.96× speedup per layer and 1.71× average end-to-end efficiency improvement in large-scale MoE models. It maintains stable performance across different parallel strategies, input sizes, and hardware environments.
COMET has already been deployed in large-scale clusters with tens of thousands of GPUs, significantly enhancing MoE training efficiency and saving millions of GPU hours. Additionally, COMET can be integrated with UltraMem—a next-generation sparse model architecture previously introduced by the Doubao (Seed) team—to achieve joint optimization.
This work has been accepted at MLSys 2025 with high ratings 5/5/5/4, and the core code is now open source!

Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Link to study: https://arxiv.org/pdf/2502.19811
Open source repository:https://github.com/bytedance/flux
Mixture-of-Experts (MoE) models leverage sparse activation mechanisms to break the computational bottlenecks of traditional dense models. However, distributed MoE training faces a significant challenge: Massive Cross-Device Communication Overhead. For instance, in the Megatron-LM framework, the Mixtral-8x7B model spends up to 40% of its total execution time on communication, significantly limiting training efficiency and increasing costs.
In MoE models, expert networks are distributed across multiple GPUs, requiring frequent Token dispatching and result aggregation during computation. This results in extensive GPU idle time and inefficient resource utilization. The key to optimizing MoE systems is hiding communication overhead within computation, thus improving training efficiency and reducing resource waste.
1. Challenges:"Complex Data Dependency" & "Pipeline Bubbles"
To mitigate excessive communication overhead, existing solutions focus on overlapping "computation-communication" more efficiently.
One approach combines pipeline scheduling with communication operators, allowing for the overlapping of computation and communication across different microbatches through customized pipeline-parallel scheduling—such as DeepSeek's DualPipe. However, this approach incurs significant memory overhead and requires complex, intrusive modifications to existing training frameworks.
Other MoE systems adopt a coarse-grained compute-communication pipeline within each microbatch, where input data is divided into "data chunks" to enable overlapping of communication and computation. However, this coarse-grained overlapping approach struggles to efficiently utilize computational resources and fails to seamlessly hide communication latency. This issue is especially pronounced in dynamic routing scenarios and heterogeneous hardware environments, leading to significant performance degradation.
Therefore, the team believes that existing system-level MoE solutions still face two major challenges:
1) Difficulty in Resolving Complex Data Dependencies
The sparse nature of the MoE architecture results in dynamic and complex dependencies between computation and communication. MoE dynamically assigns Tokens to different experts, while traditional coarse-grained matrix partitioning causes GPUs to frequently wait for remote data, leading to idle computational resources.
As shown in Figure 1, when Expert 0 needs to perform tile-level computation on the purple "data chunk," it must first receive remote data (Token B) through Token-level communication. This mismatch in granularity between computation and communication, caused by complex data dependencies, severely reduces efficiency.
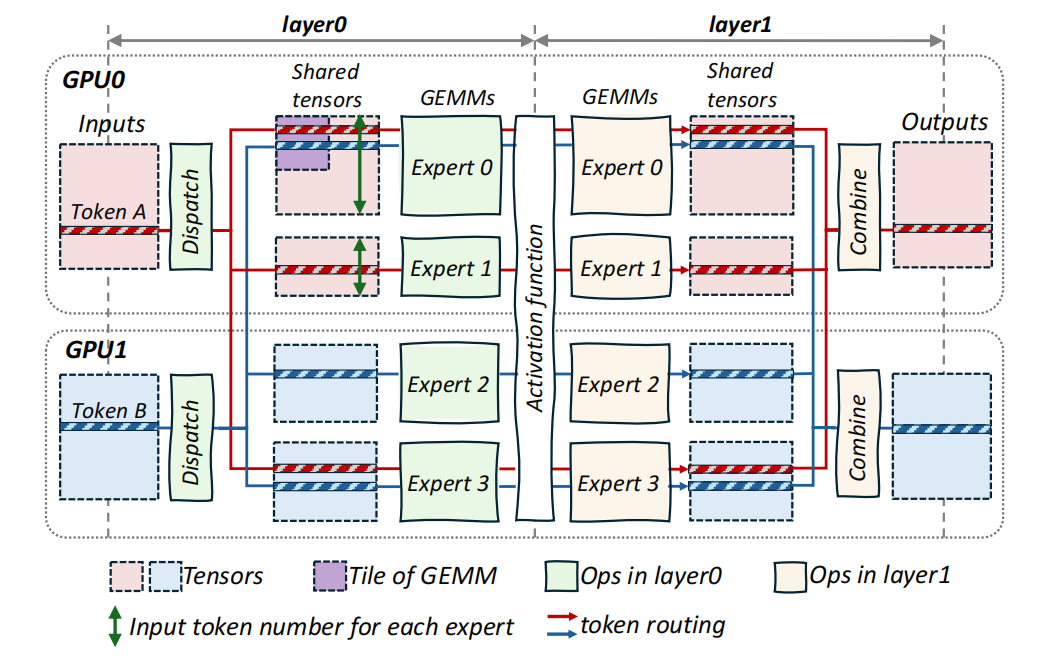
Figure 1: Illustration of a Single-layer MoE Model
(Experts are distributed across GPU0 and GPU1)
2) Difficulty in Eliminating Computation-Communication Pipeline Bubbles
Another issue is that existing methods cannot precisely control the allocation of hardware resources between computation and communication tasks. Consequently, they cannot dynamically adjust resource allocation according to different model structures and input variations. This prevents seamless overlapping of computation and communication, leading to pipeline bubbles that increase system latency.
Therefore, the team believes that: resolving the granularity mismatch between computation and communication in MoE models is key to achieving efficient overlapping. Additionally, dynamically adjusting resource allocation based on workload conditions is necessary to further ensure seamless overlap.
2. COMET Core Solution
COMET is a communication optimization system for MoE models that enhances large-scale model training through fine-grained computation-communication overlapping techniques.
Through analysis, the team has identified that the MoE architecture has two distinct producer-consumer pipelines:"Computation-Communication Pipeline" and "Communication-Computation Pipeline". As shown in Figure 2, data flows through these pipelines, where operations within each pipeline are linked by a shared buffer, referred to as the shared tensor.
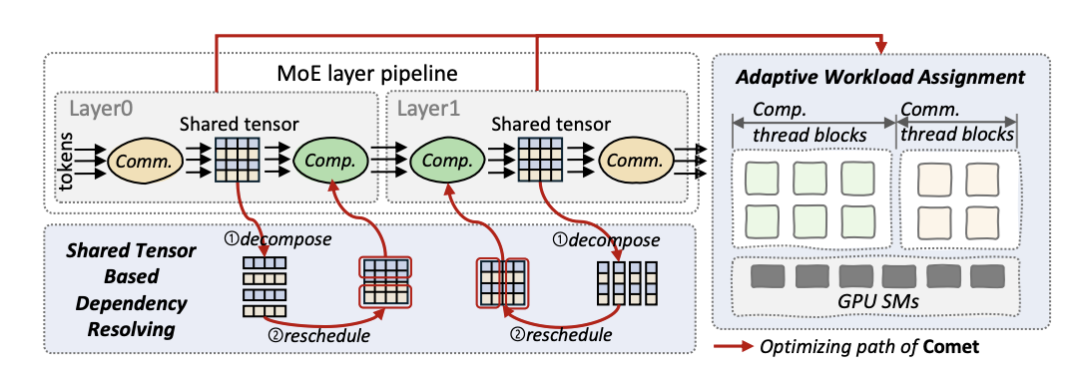
Figure 2: COMET Design Architecture
Based on this foundation, COMET introduces two key mechanisms to minimize overall latency and improve pipeline performance.
1) Shared Tensor Dependency Resolution
By decomposing and rescheduling shared tensors, COMET addresses the granularity mismatch between computation and communication, enabling fine-grained overlapping down to the Token level.
Tensor Decomposition: The shared tensor transferred between MoE layers is split along either the Token dimension (M) or the hidden layer dimension (N) to align the smallest units of communication and computation. For example, in MoE Layer 0 (Figure 3, left), the tensor is decomposed along the M-dimension, aligning communication and computation in the M-dimension. In MoE Layer 1 (Figure 3, right), the tensor is decomposed along the N-dimension, enabling fine-grained Token level transmission and ensuring efficient overlapping between computation and communication.
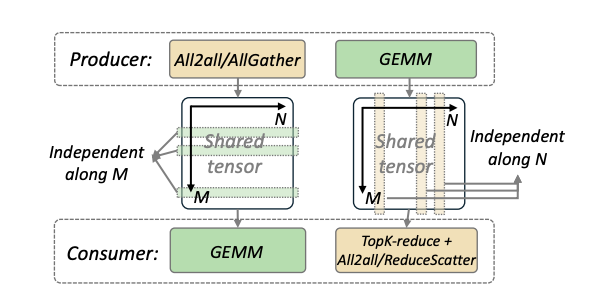
Figure 3: COMET's Shared Tensor Dependency Resolution and Decomposition
Computation Rescheduling: To further hide latency between computation and communication, COMET dynamically adjusts the computation sequence of data blocks. For example, local data blocks are prioritized for computation, while remote Tokens are asynchronously fetched in parallel. If an expert needs to process Token A (local) and Token B (remote), COMET first initiates the computation thread for Token A, while executing the communication thread for Token B in parallel, effectively eliminating wait time.
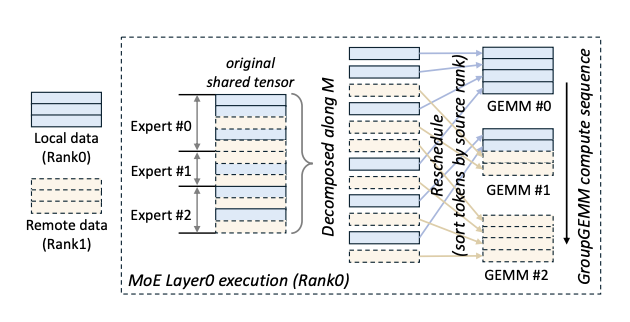
Figure 4: COMET in MoE layer0
Decomposing and Rescheduling the Shared Tensor
2) Adaptive Load Balancing
COMET dynamically allocates GPU thread block resources, precisely balancing computation and communication workloads to eliminate pipeline bubbles.
Thread Block Isolation: Computation and communication tasks are encapsulated in separate thread blocks to prevent remote I/O operations from blocking computational cores. In Nvidia Hopper architecture, computation thread blocks are dedicated to executing asynchronous TMA-based GEMM operations, while communication thread blocks handle Token-level data transmission via NVSHMEM.This design enables fine-grained operator-level resource management within the system.
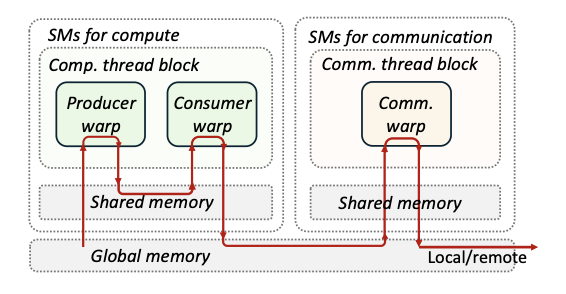
Figure 5: COMET's Computation/Communication Thread Block Isolation Design
Dynamic Load Balancing: The allocation of thread blocks is dynamically adjusted in real-time based on input size (e.g., Token length M) and parallelization strategy (EP/TP ratio). As shown in Figure 6, when TP=8, EP=1, communication thread blocks account for 19.7% of all thread blocks. When TP=4, EP=2, this proportion increases to 34.8%. The system achieves zero-overhead operator switching at runtime by pre-compiling multiple versions of fused computation-communication operators, ensuring consistently low-latency execution.
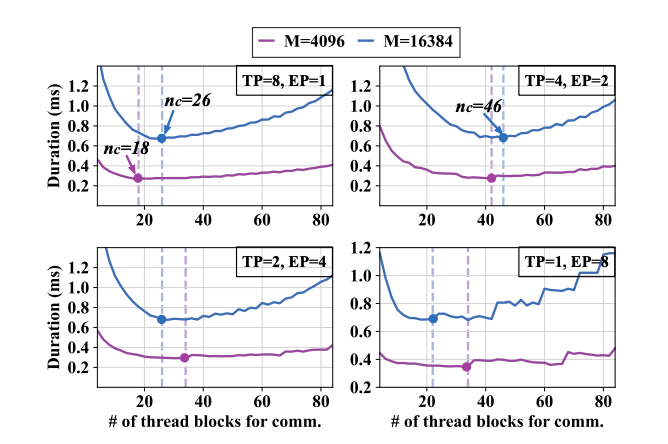
Figure 6: Latency Results for a Single MoE Layer
Using Different Numbers of Communication Thread Blocks
3. Large-Scale Deployment Validation
The team evaluated COMET's end-to-end performance across multiple large-scale MoE models. Results show that in an 8-GPU H800 experimental cluster, COMET reduces the forward latency of end-to-end MoE models (e.g., Mixtral-8x7B, Qwen2-MoE) by 31.8%–44.4% compared to baseline systems. Moreover, it maintains stable performance across different parallel strategies, input sizes, and hardware environments.
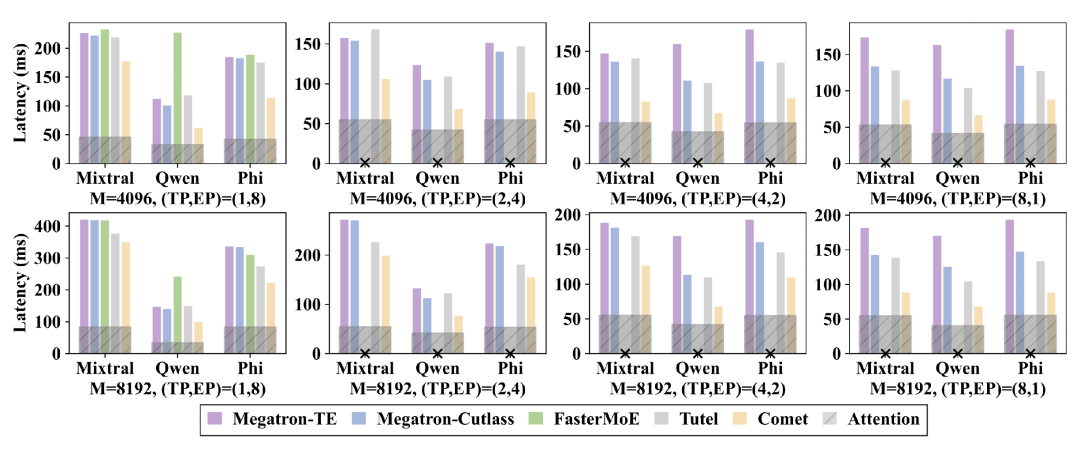
Figure 7: Evaluation Results of COMET on Multiple MoE Models
For a single MoE layer, COMET consistently outperforms baseline solutions across different input Token sizes, achieving an average speedup of 1.28× to 2.37×.
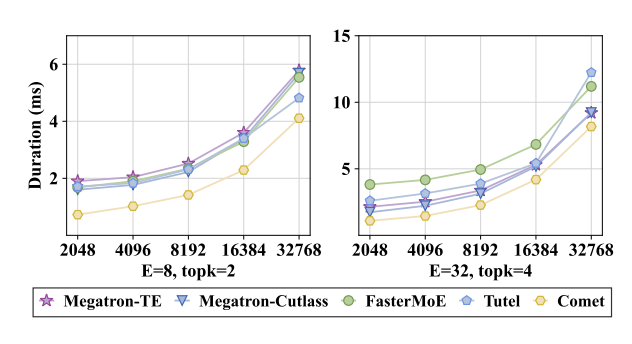
Figure 8: Latency Comparison of COMET on a Single MoE with Different Input Token Sizes Layer
Currently, COMET has been deployed in large-scale production clusters with tens of thousands of GPUs, significantly improving MoE model training efficiency and saving millions of GPU hours. This work received high scores of 5/5/5/4 in the MLSys 2025 conference review, with reviewers recognizing its strong potential for real-world large-scale production environments.
Key advantages include ——
High Robustness: COMET's fine-grained computation-communication overlapping strategy maintains lower latency than baseline systems even in scenarios with uneven expert load distribution, demonstrating strong robustness.
Strong Generalization Ability: COMET delivers consistent acceleration across different network environments, including NVLink and PCIe. It generates low-latency operators across various parallel strategies, making it suitable for large-scale training frameworks.
4. Open Sourcing of Core Code
COMET consists of approximately 12,000 lines of C++ and CUDA code, along with 2,000 lines of Python code, and provides a developer-friendly Python API.

Figure 9: COMET Open Source Repository
Additionally, COMET introduces a fine-grained pipeline programming paradigm for MoE, deeply integrating the NVSHMEM communication library and CUTLASS high-performance computation operators to fuse communication and GEMM computation within operators.
For example, in MoE Layer 1, GEMM computation and Token aggregation communication can be executed within a single GPU operator. This does not conflict with the DeepSeek DualPipe approach mentioned earlier; rather, their combination could lead to further optimization opportunities.
Moreover, COMET seamlessly integrates with existing MoE training frameworks, supporting multiple parallel modes (TP, EP, and hybrid EP+TP) and providing a flexible plug-and-play deployment solution.
The core code is now open source, with plans for compatibility with the Triton compiler ecosystem. The team welcomes collaboration and discussion from the community!