Edit Images With a Single Phrase! ByteDance Announces Image Editing Model SeedEdit, Available for Test Use
Edit Images With a Single Phrase! ByteDance Announces Image Editing Model SeedEdit, Available for Test Use
Date
2024-11-11
Category
Technology Launch
In recent years, diffusion models have made remarkable strides in image generation, with their ability to create realistic and diverse images based on textual descriptions. That said, the image editing technology is still relatively limited, unable to fulfill users' needs for controlling their generated content.
It is for that purpose that SeedEdit was conceived. It is a large diffusion model for revising images based on any textual prompt, and also the first commercial, universal image-editing model in the country.
The ByteDance Doubao (Seed) team said: "The key to successful image-editing is achieving optimal balance between retaining the original image and generating a new one. This principle underpins the entire design and optimization process for the model. Specifically designed for image editing, SeedEdit marks a new breakthrough in terms of universality, controllability, and output quality, among others.
In this article, we will demonstrate SeedEdit's modeling effects and technical capabilities. The model is also available for beta testing in the Doubao PC version and Dreamina's website. Make sure you check it out!
Demo of technical capabilities: https://team.doubao.com/seededit
Today, the Doubao (Seed) team officially announces the universal image-editing model SeedEdit, making it possible to edit images easily with a single sentence.
With a simple input of natural language, users can perform various edits on an image, including retouching, garment change, beautification, re-styling, and adding or removing elements in a specific area.
Before this, image-editing models were constrained by two major factors. The first is a low success rate for prompt response, where user intentions were frequently misunderstood. The other issue was reduced image quality after editing, such as structural deformation and blurred images.
To address these pain points, SeedEdit adopted an innovative and multi-dimensional data acquiring and filtering strategy, to achieve precise editing while ensuring high output quality, delivering results that combine aesthetics and accuracy.
1. Edit Images with a Single Phrase, Create Stunning Visuals with Precision and Flexibility
SeedEdit can cater to the diverse editing needs of different users, providing versatile control, superb editing effects, and natural aesthetics. This is primarily reflected in three key aspects:
-
Accurate understanding of prompts in Chinese and English, even with special terms
SeedEdit packs a powerful ability to understand prompts, thanks to Doubao's text-to-image (T2I) generation model. It can respond precisely to both Chinese and English inputs, and interpret complex phrases like idioms and special terminology with ease.
For instance, when handling the prompt "街道上车水马龙" (a street with an endless stream of horses and carriages; 车水马龙 being a Chinese idiom meaning 'bustling traffic'), SeedEdit can quickly capture the key information and change the original image into one showing a street with bustling traffic.

prompt: 街道上车水马龙
Another example is the prompt "驴打滚换成拿破仑" (change "rolling donkey" to Napoleon; the former referring to the Chinese snack lüdagun and the latter to the French dessert). SeedEdit would be able to discern the special meanings of "rolling" and "Napoleon", and then quickly swap one food with another in the image, perfectly capturing the user's intention.

prompt: 驴打滚变成拿破仑
-
Intelligent edit focus that makes changes only where they are needed
Distinct from the conventional method of selecting and erasing a target, SeedEdit alters an image directly based on textual prompts, showcasing a unique strength in the removal of fine elements such as cracks and strands of hair.
It can select a target flexibly, precisely and swiftly, preserving the integrity of the original image to the maximum.
As illustrated, SeedEdit only revises the area specified by the textual prompt (glass cracks). The other parts of the image remain unaffected, both in structure and resolution.

prompt: Remove glass cracks, clean picture
It is worth mentioning that SeedEdit also supports multi-round editing. With the latent-space editing technology, it can maintain the resolution and structural stability of an image, allowing users to perform long-sequence, complex editing tasks.
After multiple rounds of editing, a teacup was transformed into an ornate marble-patterned coffee cup with the word "WOW". Not only could SeedEdit alter the material of the cup and add a lid and text, it also changed the background and increased the lighting, helping users unleash their creativity.

Demo of SeedEdit's multi-round editing
-
Efficient, innovative model produces diverse styles with natural aesthetics
Compared to traditional approaches such as optimizing singular expert tasks and configuring special workflows, SeedEdit stands out with its advantages as a universal image-editing model.
Through simple prompts, users can easily change backgrounds, swap styles, add, remove or replace objects, and perform other diverse editing tasks, significantly boosting image-editing efficiency.
Let the puppy hold a newspaper with its paws. After being reworked with SeedEdit, the image displays a natural style without any trace of editing.

prompt: A dachshund reading a newspaper in a bathtub filled with bubbles.
2. SeedEdit: Align Image Re-Generation to Image Editing
Today's diffusion models are able to generate realistic and diverse images based solely on textual descriptions. However, such generated images are often non-controllable. To a certain extent, the generation process is difficult to control simply through texts.
Currently in the industry, there are two image editing methods using diffusion models: the training-free and data-driven methods. Each comes with its own disadvantages. The reconstruction and re-generation processes of the training-free method are unstable, prone to errors and can cause edited images to deviate from the input or target description; as for the data-driven method, datasets are difficult to collect, so they have to be created using tools, which limits the performance of the method.
To address this issue, the Doubao (Seed) team designed a SeedEdit architecture that converts an image-generating diffusion model into an image-editing model without including new parameters.
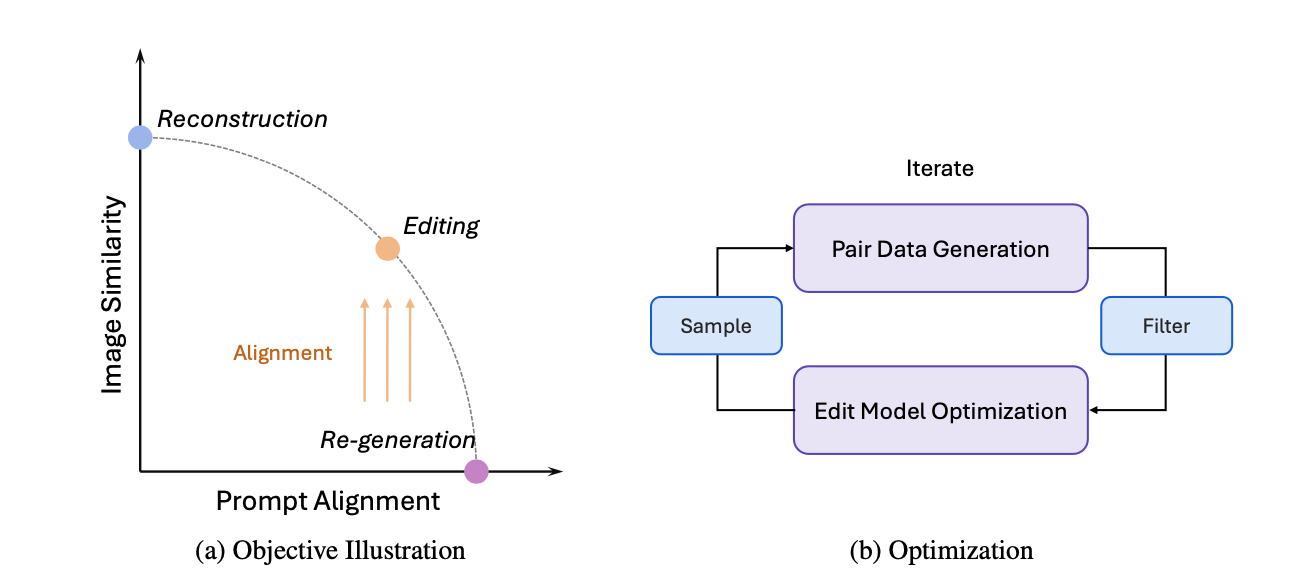
In their research paper, the team mentions that: Image editing is fundamentally about the balance between image reconstruction and re-generation, which led them to develop a pipeline that firstly generates diverse pairwise data spread in these two directions; then the image-conditioned diffusion model is progressively aligned, to achieve optimal balance between the two tasks.

SeedEdit: Align Image Re-Generation to Image Editing
SeedEdit's official website: https://team.doubao.com/seededit
The core difficulty of image editing was the scarcity of pairwise image data, which could be solved through alignment.
Specifically, we treated the text-to-image (T2I) generation model as a weak editing model, which we modified so that it can generate a new image carrying a new prompt, to achieve "editing". We then distill and align the model repeatedly, enabling it to inherit its re-generative ability to the maximum while improving image consistency, as shown below.
Ultimately, SeedEdit is able to deliver edited images with high quality, fidelity, and precision.
-
The T2I model for editing data generation
First of all, the weak T2I editing model generates a new image carrying a new prompt, achieving preliminary "editing".
Through textual descriptions like InstructP2P, the pre-trained T2I model generates a pair of images as the initial editing data.
However, current methods such as prompt-to-prompt and attention control adjustment are unable to cover all image edit types, and can only generate pairwise data of limited types.
To resolve this problem, SeedEdit incorporates multiple re-generative technologies and adjustment parameters to generate a large body of pairwise datasets. Additionally, it also features randomness that ensures data diversity and filters for quality examples for use in model training and alignment.
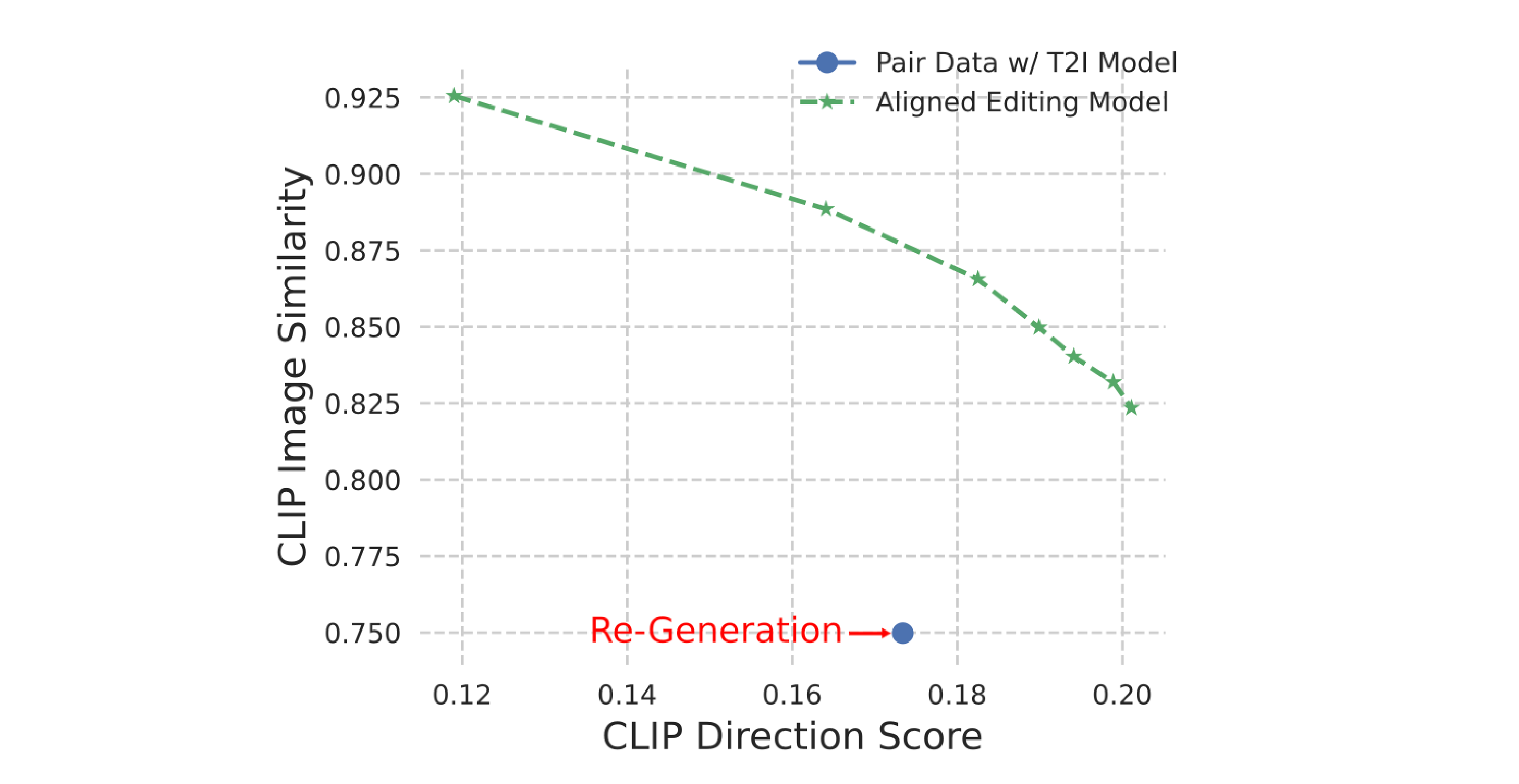
On the basis of CLIP indicators, SeedEdit's aligned model performs significantly better than simple re-generation.
-
Causal Diffusion Model with Image Input
By inheriting re-generative capabilities to the maximum and enhancing image consistency, the weak T2I model is distilled and aligned into an input-conditioned editing model (strong editing model).
Different from the previous method of adding input channels for image conditions, the SeedEdit image-conditioned diffusion model relies heavily on its self-attention mechanism, with two branches (shared parameters) applied to input and output images respectively.
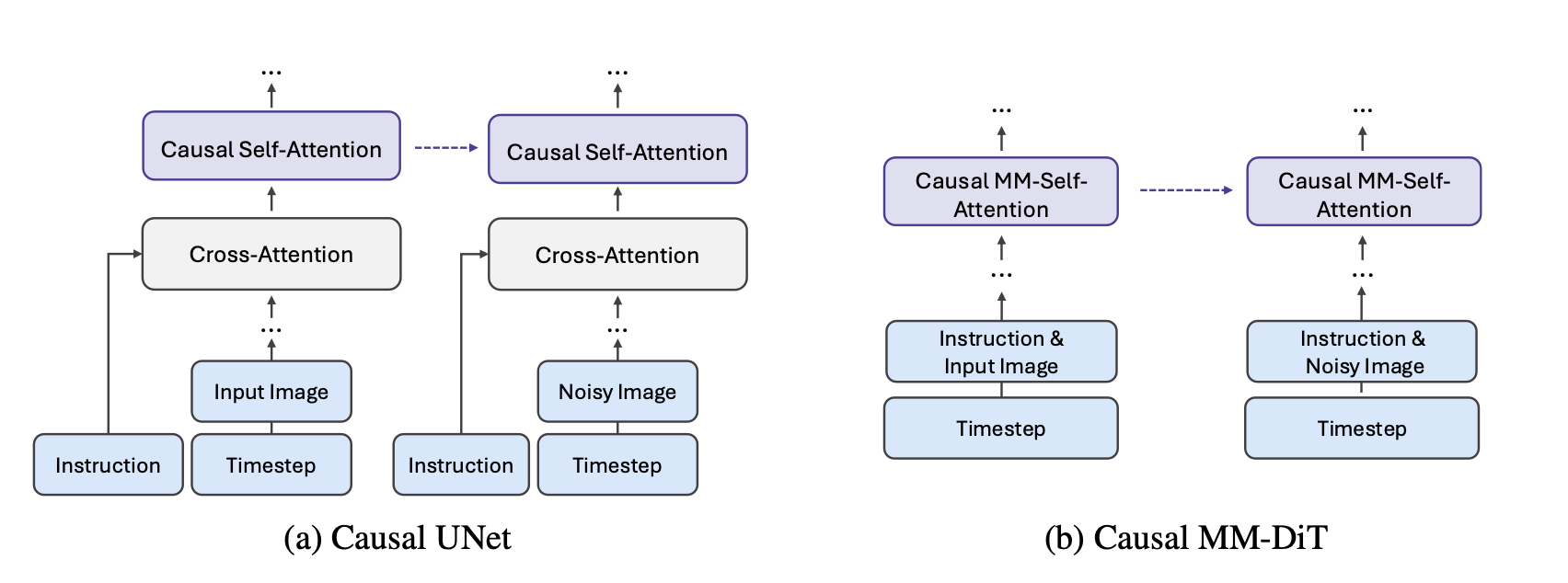
SeedEdit integrates a causal self-attention structure that enables the two networks to communicate based on intermediate features. If the input branches are removed, the image-conditioned diffusion model will revert to the original T2I model, thus performing mixed training on editing and T2I data.
This approach was inspired by the training-free method. In experiments, it performed even better in geometric transformation tasks, with fewer parameters included.
-
Iteration and Alignment
Due to noise issues, editing models initially trained on pair samples yielded low success rates despite their coverage of diverse editing tasks. They were unable to meet the application needs.
To ensure the robustness of the model, SeeEdit features more rounds of fine-tuning that align editing models in a more progressive manner.
The fine-tuning works by preparing a new set of data based on the existing editing model and by following the above data flow, then performing edits and filters on the result again over multiple rounds, until no noticeable improvements are indicated and the model has converged.
-
Experiment Results
In this experiment, we adopted the SDXL and MMDTi foundation models and used the HQ-Edit and Emu Edit datasets, with two indicators to evaluate the editing performance.
CLIP indicators were used to assess editing prompt alignment, with consistency measured based on CLIP image similarity. Meanwhile with the LLM indicators, GPT replaced CLIP direction scores as measurement of editing success.
On the HQ-Edit dataset, SeedEdit's editing score was distinctly higher than the open source baseline. Its effects were superior to those of any existing open source solution, with higher CLIP image similarity and greater fidelity to the original image.
On the Emu Edit baseline, SeedEdit also delivered higher or equal scores to the original method.
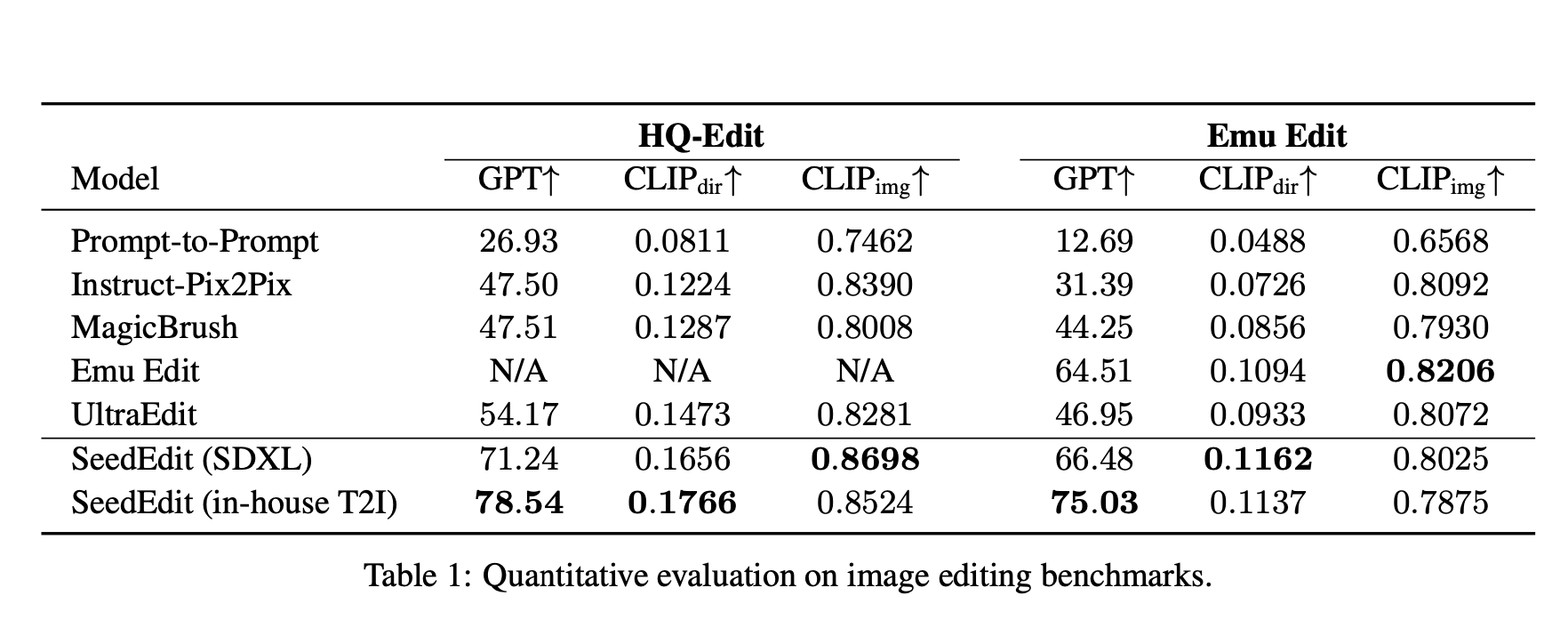
The HQ-Edit benchmark test and the baseline qualitative example show that SeedEdit is able to understand vague prompts more effectively, yielding better success rates when performing granular edits.
3. Pushing the Boundaries of Image Editing, with Multi-Image Editing and More Precise Response in the Pipeline
The SeedEdit model is currently available for beta testing in the Doubao PC version and Dreamina's website.
This release by SeedEdit is the first offering of its kind in the industry presented as a product that follows user needs closely with zero-shot learning for image editing, while featuring enhanced response and better retention of image integrity. This also marks an important milestone of the Doubao (Seed) team in the multimodal raw image field.

With this as the starting point, the team will continue to up their game in technical innovation and features expansion, bringing the overall capabilities of their image-editing models to even greater heights.
On the technical level, the team will focus on optimizing the robustness of SeedEdit in processing real images, while enhancing the response of high-value expert models such as body and portrait retouching, and element (re-) design. By using large models, the team hopes to refine future models' understanding of user editing intentions, and achieve more precise responses within compressed latent spaces.
In terms of versatility, SeedEdit's main focus is currently on single image editing. In the future, simultaneous editing of multiple images will become possible, with the construction of stable, continuous scenarios, human bodies, and objects. By infusing image sequences with the vigor of storytelling, users can unleash endless creative potential in a vast space.
If you are interested in SeedEdit's innovations, please visit SeedEdit's official website to learn more about its technology, or log on to the Doubao PC version or Dreamina's website to experience its powerful editing performance. Meanwhile, the Doubao (Seed) team is always on the lookout for top talents with a passion in the visual fields, to create more possibilities together through technology!