Seed-Music: Music Large Model Officially Released! Exceling in both music generation and editing, covering ten types of creative tasks to meet diverse needs.
Seed-Music: Music Large Model Officially Released! Exceling in both music generation and editing, covering ten types of creative tasks to meet diverse needs.
Date
2024-09-18
Category
Technology Launch
When AI encounters the captivating art form of music, magic begins. The ByteDance Doubao (Seed) team has launched Seed-Music, empowering people to explore more possibilities in music creation.
Seed-Music is a family of music generative models with flexible control capabilities. It cleverly combines the strengths of language models and diffusion models and integrates them into the music composition workflow, making it suitable for different music creation scenarios for both beginners and professionals.
This article delves into the technical capabilities of Seed-Music, revealing its remarkable surface in music generation and editing. In addition, the Seed-Music official website showcases demos of ten music creation tasks.
Official website: https://team.doubao.com/seed-music
Seed-Music, a music large model independently researched and developed by the Doubao (Seed) team, is officially released today! It has a unified framework that supports various music generation and editing tasks.
First, let's take a look at the capabilities of Seed-Music through a video:
1. Four core features, ten creation tasks, meeting the needs of different scenarios
To meet the AI-assisted music creation needs of diverse groups, Seed-Music provides four core features: controllable music generation, score-to-music, lyrics and music editing, and zero-shot voice cloning, covering ten creation tasks, meeting the needs of different scenarios for both music novices and professional musicians.
In order to give you a deeper understanding of the capabilities of the Seed-Music model, let's do a specific breakdown demonstration.
1.1 Lyrics2Song: Controllable Music Generation
The Lyrics2Song feature includes four music generation tasks: "1-minute clip generation," "3-minute full song generation," "song imitation," and "instrumental-only generation."
For example, by simply entering some simple text instructions, such as music style, lyrics, mood, rhythm, etc., Seed-Music can quickly generate a piece of AI music that matches.
When the singer is changed to a female voice and the genre is changed from "Country Music" to "Electronic Dance Music", the sound quality is still lifelike.
In addition to text prompts, Seed-Music can also write songs based on reference audio. In the demo below, we use English song audio as a reference to generate Chinese music with a highly similar listening experience, demonstrating Seed-Music's ability in cross-language lyrics creation.
1.2 Lyrics2Leadsheet2Song: Score to Song Conversion
A lead sheet usually includes the melody, lyrics and chord symbols of a song, it is like a musical map or guide that guides the performer or singer to perform.
Seed-Music integrates the lead sheet into the AI-assisted creation workflow, enhancing the interpretability and controllability of music creation, aiming to help professional musicians improve efficiency and focus on the creative expression of music.
Whether it is generating a lead sheet based on lyrics, generating a complete performance from a lead sheet, or performing vocals from a lead sheet, musicians can directly edit and adjust on the lead sheet, easily adjust the pitch, notes duration, position of notes and the speed of rhythm, so as to visually control the music creation process.
1.3 Music Editing: Lyric and Melody Editing
Music Editing based on the diffusion model can accurately make partial modifications to lyrics or melodies, and ensure smooth transitions in the edited areas.
For example, in a song, if a creator wants to change a lyric from "a handful of Yellow River water" to "a handful of Yangtze River water" while keeping the continuity of the melody and accompaniment, Music Editing can easily achieve this with natural results.
1.4 Singing Voice Conversion: Zero-Shot Voice Cloning
Zero-shot voice cloning is also a major innovation of Seed-Music, as the model does not require large-scale training for specific voices. Creators only need to use 10 seconds of their own voice (supporting singing or speaking) as input, and the system can imitate the specified voice to generate a complete song.
This allows creators to quickly preview the sound effects without spending a lot of time recording, thus broadening the boundaries of music creation.
2. Seed-Music Technical Method Explained
As can be seen from the above examples, Seed-Music is an end-to-end and comprehensive music generation framework. It can not only draw inspiration from natural language and audio, but also flexibly control various musical attributes, and seamlessly integrate with the musician's workflow to generate musically rich and high-quality musical works, giving different people the freedom to create.

- Paper title: Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
- Technical report link: https://arxiv.org/pdf/2409.09214
- Official website of Seed-Music: https://team.doubao.com/seed-music
AI music generation faces many challenges, such as the complexity of the field, limitations in evaluation, and diverse user demands. Among them, the complexity of music signals is a key issue. Music signals typically contain multiple overlapping tracks, diverse tones, timbres, and high sampling rate signals. In addition, music signals also exhibit both short-term melodic coherence and long-term structural consistency.
Vocal music generation is even more complex, requiring simultaneous processing of lyrics, melody, harmony, rhythm, and other factors, and maintaining consistency throughout the entire track. Although large language model technology has made some progress, it is still difficult to guarantee the generation of high-quality audio.
Moreover, music is highly artistic, open, and subjective, which is different from image or speech generation. Music generation lacks a set of universal evaluation standards and recognized benchmarks. In addition, the needs of music novices and professional musicians are completely different. Even among professionals, different types of musicians, such as guitarists and vocalists, have different needs.
In response to these challenges, Seed-Music has adopted a unique technical solution and proposed a unified framework for music generation.
In order to support flexible control of input and generate high-quality music based on different types of user input, the framework consists of three core components: a Representation Learning module, which compresses the raw audio waveform into the intermediate representation that serves as the foundation for training the subsequent components; a Generator, which processes various user control inputs and generates the corresponding intermediate representation; and a Renderer, which synthesizes high-quality audio waveform based on the intermediate representation from Generator.
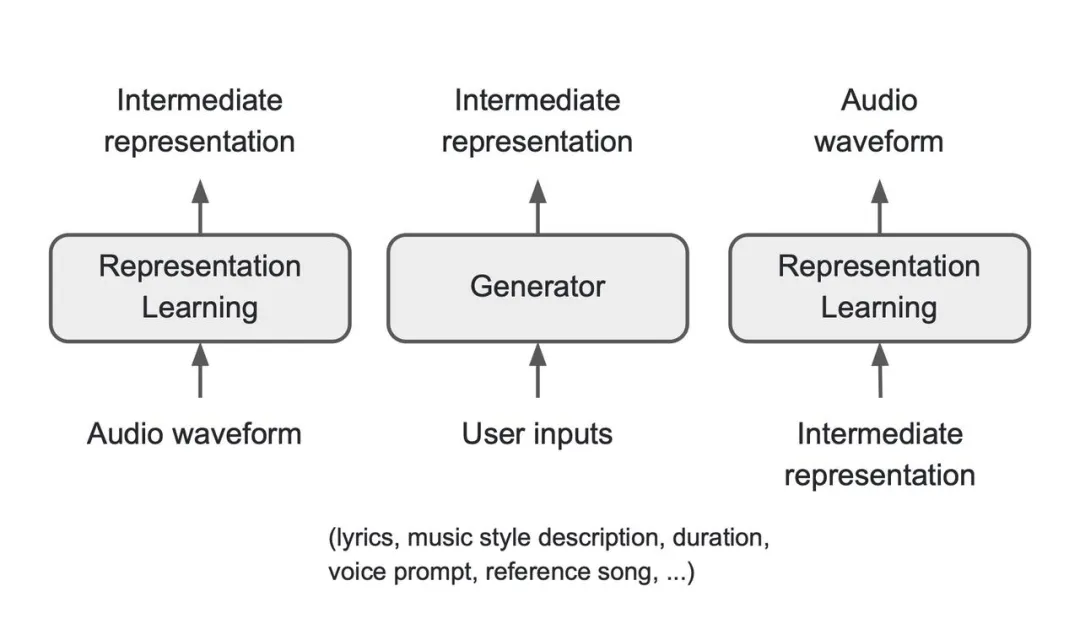
Figure: An overview of Seed-Music framework
In this framework, Seed-Music explores three types of intermediate representations: audio tokens, symbolic music tokens, and vocoder latents, each corresponding to a generation pipeline. Each pipeline has its own advantages and disadvantages, and the most suitable pipeline can be matched according to the downstream music composition task.
2.1 Audio Token-based Pipeline
The goal of audio tokens is to generate discrete tokens that are much lower than the audio sampling rate, aiming to effectively encode semantic and acoustic information. When using an autoregressive language model as the generator backbone, audio tokens can easily bridge different modalities.

Figure: Overview of the Seed-Music pipeline with audio token as intermediate representation
The audio token-based pipeline includes four building blocks:
- an audio tokenizer, which converts raw music waveforms into low rate discrete tokens;
- an auto-regressive LM, which takes in user control inputs, converts them into prefix tokens, and predicts a sequence of target audio tokens;
- a token diffusion model, which predicts the vocoder latents based on the audio tokens;
- an acoustic vocoder, which renders the final 44.1kHz stereo audio waveform.
The effectiveness of the audio tokenizer is critical to the success of this pipeline as it needs to retain key information in high compression scenarios to improve the training efficiency of the autoregressive language model. At the same time, it also needs to balance allocating more codebook capacity to semantic information consistent with the training objectives of the generator, and enhancing the balance between "encoding more semantic information" and "improving the reconstruction performance of tokens to waveforms".
2.2 Symbolic Token-based Pipeline

Note:Overview of the pipeline using symbolic tokens as the intermediate representation
The lead sheet tokenizer encodes the information of a 5-track lead sheet (vocals, piano, guitar, bass, drums) into a sequence of tokens from a predefined codebook. During training, the language model learns to predict the lead sheet token sequence based on lyrics information, rather than audio tokens. We use music transcription and ASR models to annotate the music audio for training, serving as the prediction target for the language model.
Different from audio tokens, lead sheet tokens are interpretable and can be converted back and forth with sheet music, allowing for the injection of human knowledge during both training and inference processes. For example, when predicting the next token in a sampled sequence, lead sheet tokens can be used to exclude those that violate conventional music theory. Additionally, as an intermediate result, lead sheets enable musicians to intervene in the model at this stage, allowing for interactive composition such as music editing.
Unlike audio tokens, lead sheet tokens contain notes, lyrics, instrument types, and meta-information, but do not include acoustic information. Therefore, predicting vocoder latents from lead sheet tokens is a more challenging task for diffusion models, requiring a significant increase in the scale of diffusion models to achieve the same end-to-end performance.
2.3 Vocoder Latent-based Pipeline
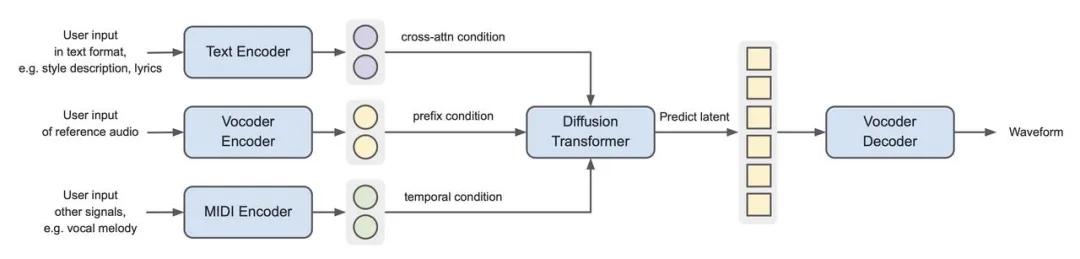
Note: Seed-Music pipeline with vocoder latents as intermediate representation
Seed-Music also explores a pipeline based on vocoder latents. In this pipeline, a variational autoencoder compresses the input audio into vocoder latents, and a diffusion model is trained to map conditional signals to the continuous vocoder latent space.
When using acoustic vocoder latents as intermediate representations, the architecture of the diffusion model and vocoder is similar to the audio token-based pipeline. However, with the autoregressive model removed, the overall pipeline has fewer layers, resulting in higher training and inference efficiency. Of course, each component's model needs to be scaled up to achieve comparable performance.
Another major advantage of the diffusion model is its support for various control signals. It can predict masked regions in the vocoder latent space through contextual information, inject text control signals through cross-attention, and generate corresponding accompaniments by adding time-aligned input signals (such as vocal melodies).
2.4 Model Training and Inference
Seed-Music's training process involves three stages: pre-training, fine-tuning, and post-training. The pre-training stage aims to establish a strong foundational model for music audio modeling. The fine-tuning stage includes data fine-tuning based on high-quality music datasets to enhance musicality, and instruction fine-tuning to adapt to specific creative tasks. Post-training is conducted through reinforcement learning to improve the overall stability of the model.
During inference, the sample decoding scheme is crucial for eliciting the best results from the trained model. By carefully adjusting Classifier Free Guidance, the overall musicality and adherence to prompts are ensured. Additionally, to reduce latency in the cascade generation system, Seed-Music implements a streaming decoding scheme, allowing the inference of language models and diffusion models to proceed in parallel, enabling the generated music to start playing within 3 seconds of user input.
3. "Super Assistant" for Music Creation, Bringing New Possibilities to Media Creation
The above demonstrates the effectiveness of Seed-Music in generating high-quality vocals through natural language and audio input, interpretable lead sheet, lyric and melody editing, and zero-shot voice conversion systems. It details Seed-Music's generation technology based on three types of music audio representations and its methods of model training and inference.
Traditional music creation processes are often complex and cumbersome, limiting the enthusiasm of many creators. Seed-Music provides equally precise and efficient support for both music novices and professional musicians through customized technical solutions, making it a "super assistant" in music creation.
For music novices, for example, Seed-Music combines text-to-music with voice cloning, allowing ordinary people to start music creation with low barriers, incorporating their own voices into musical ideas and creating their own exclusive music.
For professional musicians, Seed-Music adheres to the principle of respecting and integrating into the workflows of musicians, composers, singers, and artists, enabling professional creators to have complete control over lyrics, melodies, and arrangements, saving time and costs in the creative process, and quickly auditioning musical ideas. Seed-Music helps musicians unleash their creativity, producing more unexpected musical inspirations.

Voice is an important identifier of personal identity, and the security issues of AI music creation deserve attention. To prevent Seed-Music from being misused for impersonation, the team has adopted similar security measures to Seed-TTS, which include multi-step verification of voice content and sound, and the implementation of multi-level watermarking schemes and repeated checks throughout the music generation process.
Music is an indispensable part of multimedia experiences such as short videos, long videos, games, and AR/VR. In the future, Seed-Music's music generation may enable a new form of artistic medium—where the generated music responds not only to text but also to environmental signals such as in-game storylines and visual art styles, bringing more possibilities to multimedia creation.
The Doubao (Seed) Team is committed to supporting creators and improving the efficiency of music production, making music a form of expression without barriers, boundaries, or limitations. If you are interested in exploring Seed-Music, please visit our official website or browse the official website via PC at https://team.doubao.com/seed-music to experience more demos and learn more technical details.
At the same time, we hope to attract talented individuals with the same aspirations and goals to join the team, solve technical problems together, realize technical visions, and bring more breakthroughs to Seed-Music.