Seedream 3.0 Text-to-Image Model Technical Report Released
Seedream 3.0 Text-to-Image Model Technical Report Released
Date
2025-04-16
Category
Technology Launch
ByteDance Seed team has officially released the technical report for Seedream 3.0. Seedream 3.0 is a high-resolution, bilingual (Chinese-English) foundational text-to-image model. Compared to Seedream 2.0, this version offers significant overall performance improvements, particularly in resolution, image structure accuracy, quantity consistency, multi-object attribute relationships, small text generation and layout, visual aesthetics, and realism.
Key Highlights:
Native 2K Output for Diverse Aspect Ratios: Delivers 2K resolution images directly without post-processing, catering to a wide range of visual needs from mobile screens to large-format posters.
3-Second Image Generation for Greater Efficiency: Designed for poster design and creative visuals, it can generate high-quality images in around 3 seconds, enabling real-time creative interaction and "what you see is what you imagine."
Improved Small Text Accuracy and Typography: Advances in high-fidelity small font rendering and multi-line text layout address long-standing challenges in the industry, equipping AI with commercial-grade graphic design capabilities.
Enhanced Aesthetics & Structure for Emotional Impact: Better instruction-following, improved human/object structure accuracy, and reduced artificial "AI feel" result in a shift from "clear visuals" to "emotionally engaging aesthetics."
The development of Seedream 3.0 began in late 2024. Based on thorough research into the needs of designers and other user groups, the Seedream team prioritized industry-aligned goals such as text-image alignment, structural coherence, and aesthetic appeal. Core challenges tackled included small-text generation, complex text layout, native 2K high-definition output, and rapid image generation. In April 2025, Seedream 3.0 officially launched and is now fully available on platforms like Doubao and Jimeng.
Comprehensive subjective and objective evaluations—across dimensions such as structure, aesthetics, portrait quality, text usability, and user preference (Elo score)—show that Seedream 3.0 represents a significant upgrade from version 2.0, with particularly outstanding performance in long-text rendering and realistic portrait generation.
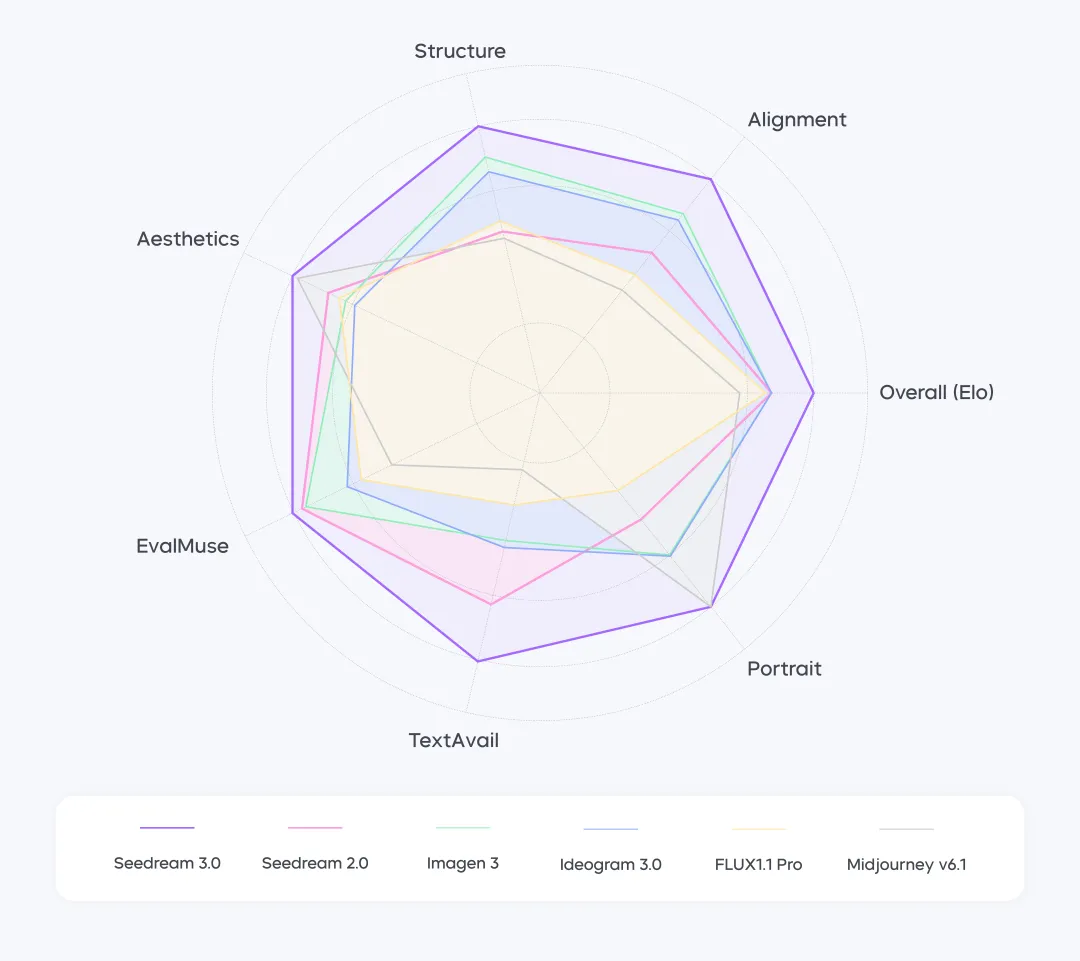
Seedream 3.0's Performance Across Multiple Dimensions. The data in this chart has been normalized using the best indicators as a reference.
On the renowned benchmarking platform Artificial Analysis, Seedream 3.0 has competed alongside other leading text-to-image models such as GPT-4o, Imagen 3, Midjourney v6.1, FLUX 1.1 Pro, and Ideogram 3.0. In recent rankings, Seedream 3.0 even held the top position at one point.
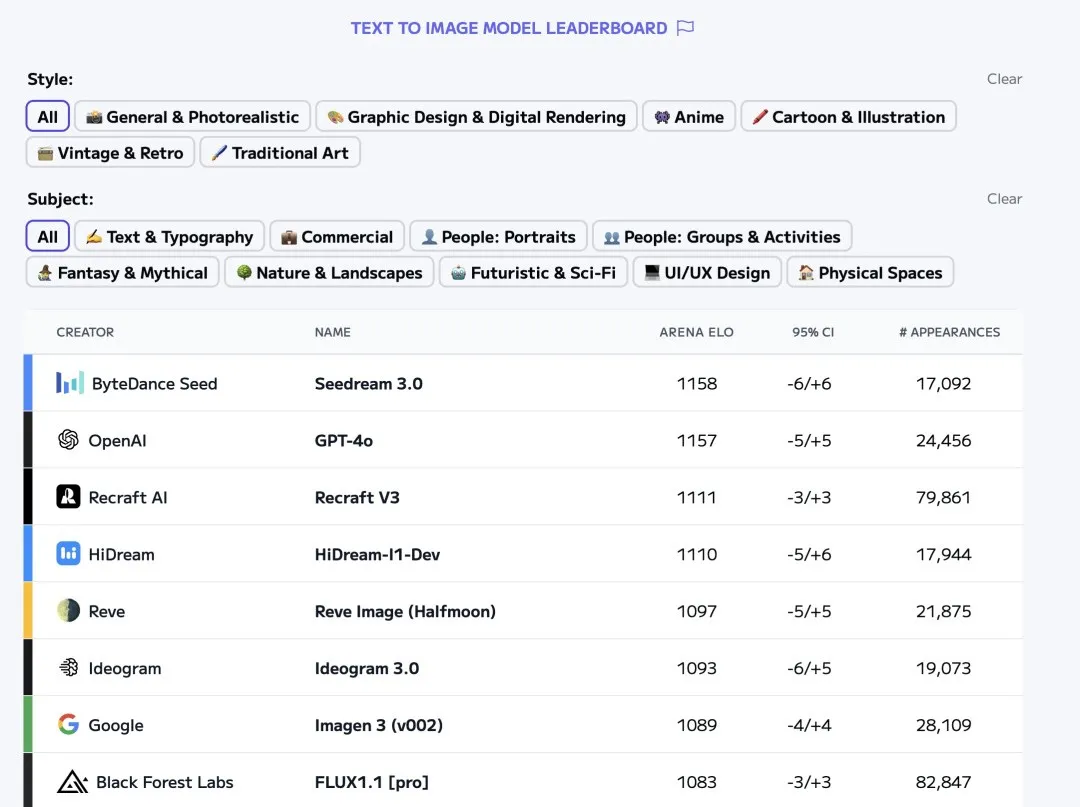
Artificial Analysis Ranking (as of the afternoon of April 15)
Notably, Seedream 3.0 excels in poster design and creative generation tasks, aligning closely with the day-to-day needs of professional designers.

This report will outline the technical implementation of Seedream 3.0, covering aspects such as data collection and processing, pre-training, post-training, and inference acceleration.
1. Data Optimization: Defect-Aware Dataset Expansion and Improved Data Distribution
For generative AI, large-scale, high-quality training data is essential. Seedream 3.0 enhances its data collection and preprocessing processes through the following three key strategies:
- Defect-Aware Training Strategy for Significantly Increased Usable Data Volume
In Seedream 2.0, a conservative data filtering approach was used to ensure training quality, removing a large number of images with minor defects (e.g., watermarks, subtitles, mosaics). Seedream 3.0 adopts a new defect-aware training strategy: by using an in-house developed detector to precisely locate defects and measure their size, images with minor imperfections are retained. During training, latent space masking is applied to minimize the impact of defects on the loss function. This approach expanded the effective dataset by more than 20% while maintaining stable model training.
- Visuo-Semantic Joint Sampling Strategy for Balanced Data Distribution
Traditional text-to-image datasets often suffer from imbalanced data distribution. To address this issue, the team developed a two-dimensional visuo-semantic joint sampling strategy. Visually, hierarchical clustering ensures diversity in visual styles; semantically, TF-IDF (Term Frequency–Inverse Document Frequency) is employed to mitigate the long-tail distribution in text descriptions. This joint optimization significantly improves the balance between visual patterns and semantic concepts.
- Development of an Image-Text Retrieval System to Further Refine Data Distribution
The Seedream 3.0 team developed a proprietary image-text retrieval system, which achieved leading performance on public evaluation sets. Leveraging this system, the team refined and calibrated the distribution of the existing dataset, thereby enhancing overall data quality and laying a solid foundation for training a high-performing text-to-image model.
2. Pre-Training: Focus on Multi-Resolution Generation and Semantic Alignment
During the pre-training phase, the Seedream team made multiple improvements to the model architecture and training strategy to better support multilingual semantic understanding, precise text rendering, and native high-resolution image generation across multiple resolutions:
- Cross-Modality Rotary Position Embedding (RoPE) to Enhance Text Rendering
To further strengthen image-text alignment, the team extended the Scaling RoPE introduced in the previous version into a cross-modality RoPE mechanism. Traditional approaches often use 2D RoPE for image features and 1D RoPE for text features, which hinders alignment across modalities. In Cross-Modality RoPE, text features are treated as 2D features with a shape of [1, L], allowing the use of 2D RoPE. The starting column ID for the text's 2D RoPE continues from the end of the image's 2D RoPE column ID. This design improves the modeling of inter-modal relationships and intra-modal relative positions—making it one of the key innovations that enable Seedream 3.0 to render text more effectively.
- Multi-Resolution Hybrid Training Enables Native 2K Image Generation
In Seedream 2.0, a separate Refiner module was used to upscale image resolution, which increased inference overhead. In Seedream 3.0, the team leveraged the Transformer architecture's flexibility in handling variable-length input sequences and adopted a multi-resolution hybrid training strategy. In Phase 1 of pre-training, the model was trained on low-resolution images averaging 256×256. In Phase 2, images with resolutions ranging from 512×512 to 2048×2048 and various aspect ratios were used for mixed training. To improve training efficiency, a load-balancing strategy was implemented to ensure approximately equal sequence lengths across different GPUs. As a result, the final model can natively generate images at multiple resolutions, including direct 2K output without requiring an additional Refiner.
- Flow Matching and Feature Alignment Losses for Efficient Data Distribution Modeling
Unlike the score matching loss based on diffusion models used in Seedream 2.0, Seedream 3.0 introduces a flow matching loss to predict conditional velocity fields. To accommodate the changing signal-to-noise ratios during multi-resolution hybrid training, the distribution of timesteps in the flow matching process is dynamically adjusted based on the average resolution at each training stage. Additionally, a feature alignment loss (REPA) is incorporated to help the model converge faster during pre-training—marking a successful application of feature alignment loss functions in a large-scale industrial-grade text-to-image model.
3. Post-Training with RLHF: Enhancing Aesthetics and Unlocking Model Potential
In the post-training phase, the team implemented multiple aesthetic captioning strategies during the CT and SFT stages, and significantly expanded the reward model during the RLHF stage. These improvements collectively enhanced the model's performance across multiple dimensions.
- Multi-Granular Aesthetic Descriptions
For the CT and SFT phases, Seedream 3.0 trained several versions of captioning models tailored to provide precise descriptions in areas such as aesthetics, style, and layout. These multi-granular captions improve the model's ability to respond accurately to various prompts, enhance controllability, and work in tandem with PE modules to boost overall performance.
- Expanded Reward Model
Unlike Seedream 2.0, which used CLIP as the reward model, Seedream 3.0 introduces an upgraded reward modeling approach. The new reward model is built on a visual-language model (VLM), drawing inspiration from generative RM techniques used in LLMs. This allows for improved reward accuracy and robustness by leveraging LLM-style scaling capabilities. Additionally, the reward model's parameter count was expanded from 0.8B to over 20B, and the team discovered a scaling law specific to reward model performance, which further informed their optimization strategy.
4. Efficient Inference: 1K Resolution Image Generation in Just 3 Seconds End-to-End
Seedream 3.0 implements multiple strategies to accelerate inference. In addition to model quantization, one of the most critical dimensions for accelerating diffusion models is the distillation of sampling steps during inference. Seedream 3.0 incorporates an in-house developed inference acceleration algorithm, with the following key innovations:
- Consistent Noise Prediction for Smoother Sampling
Traditional diffusion models often suffer from large variations in noise predictions across time steps during sampling, contributing to the need for many steps to maintain quality. To address this, the team designed the network to predict a global noise expectation, ensuring consistency throughout the sampling process and significantly reducing the number of required steps.
- Important Timestep Sampling to Speed Up Model Distillation
To improve distillation efficiency, the team introduced a technique called "important timestep sampling." A dedicated network is trained to predict the distribution of the most crucial sampling timesteps for each sample. Based on this distribution, optimal timesteps are selected for distillation. With this technique, the team completed the entire model distillation process within 64 GPU-days. These optimizations enable lossless acceleration—maintaining image-text alignment, aesthetic quality, and structural accuracy—while drastically improving generation speed. As a result, Seedream 3.0 can generate 1K-resolution images end-to-end in just 3 seconds.
5. Final Thoughts
Since its release, Seedream 3.0 has received recognition for significant improvements in poster design, generation efficiency, and aesthetic and structural quality.
Looking ahead, the Seedream team aims to further explore the following directions: More Efficient Architecture Design: Building text-to-image models with better performance, lower cost, and faster generation speed. Enhanced Intelligence and World Knowledge Integration: Enabling the model to understand more about the world and develop capabilities such as interleaved generation. Scaling Across Data, Model Size, and Reward Models: Investigating scaling phenomena across these dimensions and applying cognitive insights to the development of the next-generation models.
Moving forward, the team will continue to share technical insights and collaborate with the broader community to advance the field of visual generation.