The Doubao Visual Language Model Officially Released, with General Model Capability Fully Comparable to GPT-4o!
The Doubao Visual Language Model Officially Released, with General Model Capability Fully Comparable to GPT-4o!
Date
2024-12-18
Category
Technology Launch
The Doubao Visual Language Model made its debut at the Volcano Engine Force Conference · Winter on December 18. The model has very strong content recognition ability, as well as excellent comprehension, reasoning, and detailed visual description.
Also unveiled were the upgraded main Doubao general model, Doubao music generation model, Doubao text-to-image model, and others. This article will present the highlights of the release from a technical perspective.
The Doubao large model can now "see" the world.
Today, at the Volcano Engine Force Conference · Winter, the Doubao Large Model Family announced a new member, the Doubao Visual Language Model. It not only has powerful visual perception capabilities, but also combines visual and language inputs for comprehensive deep thinking and creation.
Based on image information, the Doubao Visual Language Model can complete many complex logic computing tasks, including challenging tasks such as solving calculus problems, analyzing paper charts, and troubleshooting real code issues.
Click on the video below to see the power of the Doubao Visual Language Model:
In addition to the Doubao Visual Language Model, the upgraded main Doubao general model, Doubao music generation model, Doubao text-to-image model were also announced, along with the 3D generation model.
1. The Visual Language Model Can Not Only "See" but Also "Think"
Vision is the most important means for humans to understand the world. The same is true for large models. Comprehensive visual understanding ability is essential for them to process real- world information and assist humans in performing a series of complex tasks.
The Doubao Visual Language Model allows users to enter text and image-related questions at the same time, and the model can give accurate answers after comprehensive understanding.
This will greatly simplify the development process and allow the large model to shine in more scenarios.
To support these needs, the Doubao Visual Language model offers three capabilities:
Enhanced content recognition
The Doubao Visual Language Model has exceptional content recognition abilities. It can not only recognize the basic elements such as object categories, shapes, and textures in images, but also understand the relationship between objects, spatial layout, the overall meaning of the scene, and even the cultural knowledge behind it.
Specifically, the visual language model can not only identify real-world objects, but also instantly identify the shadow of a small animal based on the light, silhouette, location, and other characteristics, and "recognize" it as a cat.
When you go for a morning run and see light filtering through trees, you can take a photo and ask the Doubao large model what scientific phenomenon this is. It will identify it as the Tyndall effect and explain the principle behind it.
Enhanced understanding and reasoning
The Doubao Visual Language Model also has excellent comprehension and reasoning abilities. It can not only recognize graphic information but also perform complex logical computing. After you take a picture of a math problem that requires calculus operation, the Doubao Visual Language Model can effectively understand the image-based problem and, based on the prompts, perform reasoning calculations and provide problem-solving insights.
It can also read academic papers.
For the following paper titled "How Far is Video Generation from World Model: A Physical Law Perspective," the model can accurately understand and analyze the trends and conclusions presented in the chart.
The same goes for "reading" code, where the model identifies the purpose of real code and describes what each line of code does.
Finer visual description
In addition to the recognition, understanding and reasoning abilities, the Doubao Visual Language model also excels at nuanced visual descriptions and creativity.
When designing a cultural product as a gift for a client, the model can write a heartfelt message inspired by the product's design or symbolism.
A child's doodles are enough for the Doubao Visual Language Model to create a fantasy story.
In terms of applications, the Doubao Visual Language Model can be implemented in photo Q&A, healthcare, education and research, e-commerce shopping, life assistant, and many other scenarios.
2. Common Model Capability Fully Comparable to GPT-4o, with Video Generation Model Coming Soon for Enterprises
Upgraded main general model fully comparable to GPT-4o
In addition to the visual language model, the conference also announced upgrades to the Doubao large language models.
Doubao-pro, the most powerful model of Doubao, has been significantly improved compared to the May version. Based on the MMLU_pro evaluation set, the overall capability of the model improved by 32%, on par with the GPT-4o, at only one-eighth the price of GPT-4o.
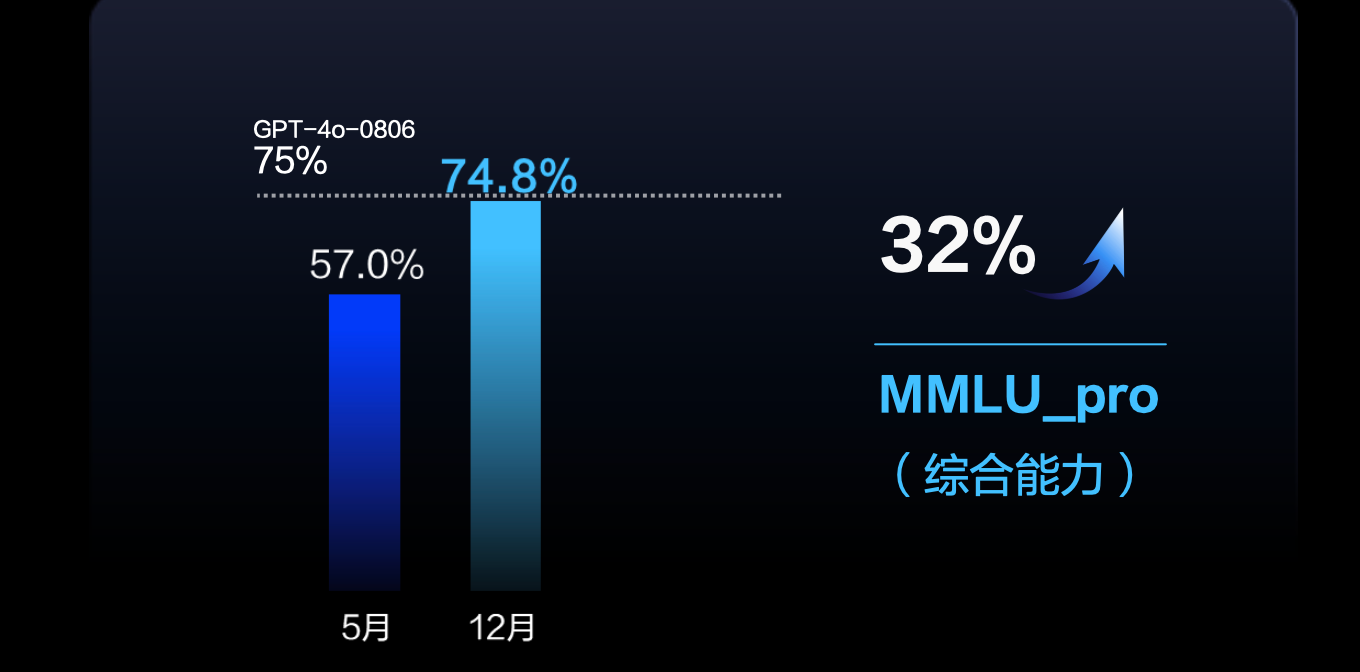
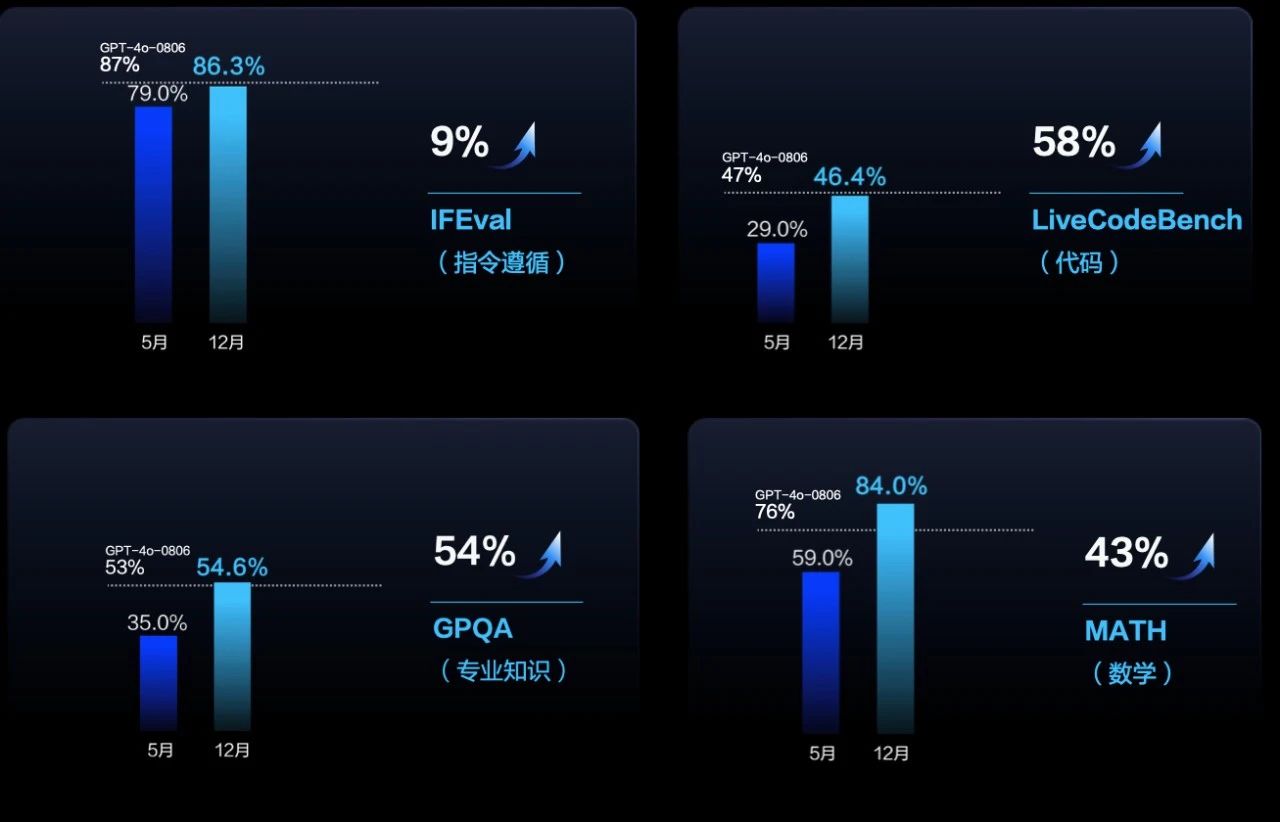
Doubao-pro has increased its instruction following ability increased by 9%, code ability by 58%, GPQA expertise by 54%, math by 43%, reasoning by 13%, to a level fully comparable to GPT- 4o.
The Doubao video generation model is about to open up to enterprises
On September 24, the Doubao video generation model was released, and since then, the model has been available to consumer-end users through the Dreamina APP and the web platform, inspiring creators to craft stunning videos.
For enterprise customers and developers, the Doubao video generation model will be officially open to the public in January , supported by the Volcano Engine.
Upgraded music and text-to-image models
The Doubao music model, first released in September 2024, can now generate 3-minute complete music products after 3 months, enabling the creation of works with complex structures such as the prelude, the main song, the chorus, the interlude, and the transition.
In addition, the new version of the model can orchestrate the melody, rhythm, and harmonization information, so that the whole song remains consistent in terms of musical elements such as style and mood. If you are not satisfied with the lyrics, you can also modify them locally to add new lyrics to the original melody, making music creation more free and flexible.
New "one-click image editing" and "one-click poster generation" features are added to the text- to-image model.
Based on the Doubao (Seed) team's SeedEdit, the Doubao text-to-image model version 2.1 supports "one-click image editing" through natural language commands, including outfit change, beautification, smudging, style transfer, and a range of other editing options.
At the same time, the Doubao text-to-image image model supports "one-click poster generation", enabling precise control over text and pattern generation. By opening up the LLM and DiT frameworks, the Doubao text-to-image model has built high-quality text rendering capabilities that greatly improve the accuracy of text generation. This native text rendering ability allows text to blend more naturally and practically with the overall image.
Release of Doubao 3D generation model
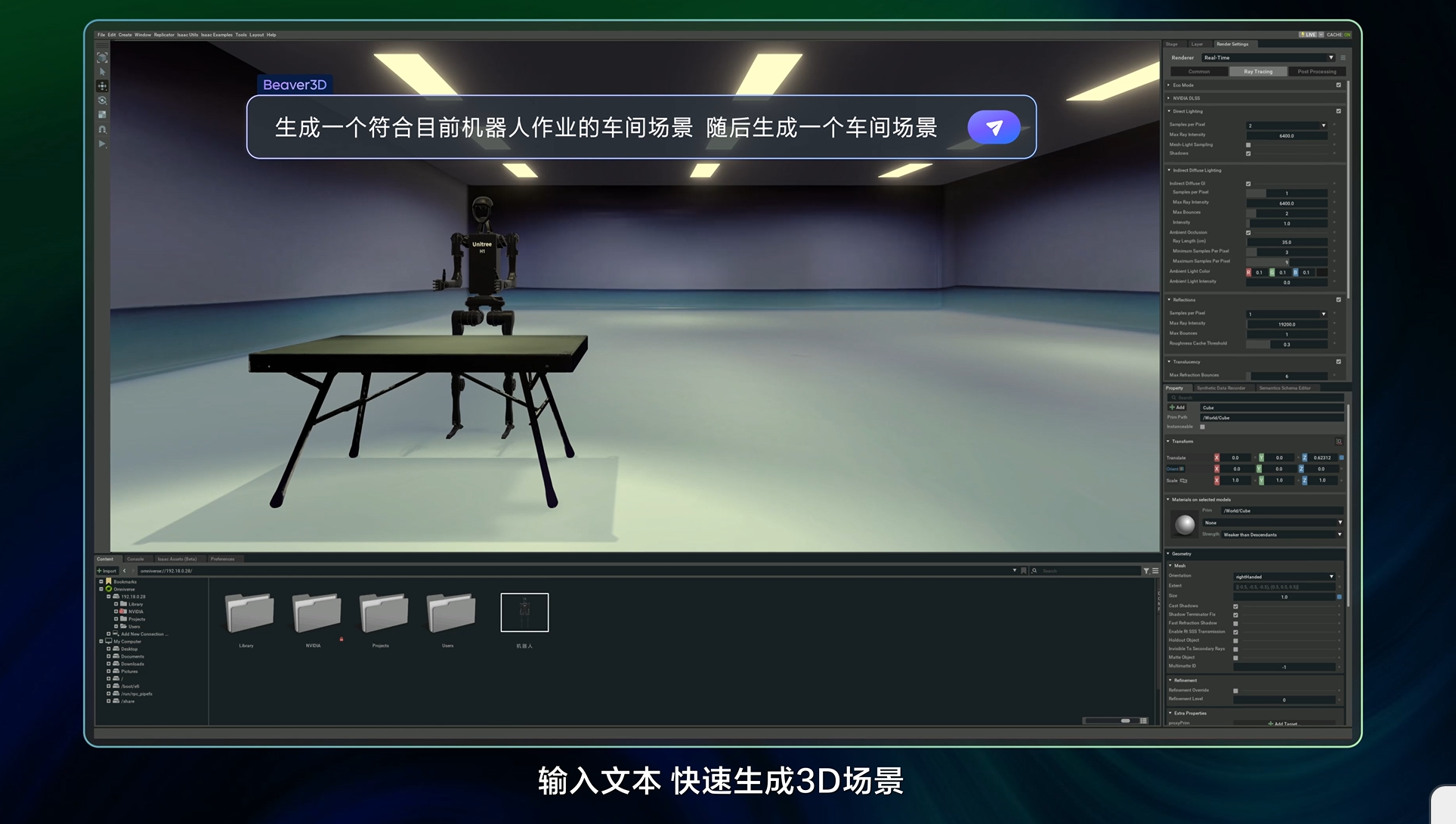
Targeting the field of 3D simulation, a new 3D generation model has been added to the Doubao Large Model Family, which uses the 3D-DiT architecture to generate high-quality 3D modules. Combined with veOmniverse, a digital twin platform of Volcano Engine, this model enables efficient smart training, data synthesis, and digital asset creation to form a set of physical world simulation tools that support AIGC creation.
For example, a user can instantly generate and build a factory floor scenario by simply entering text. Through rapid batch generation and uploading to the cloud, layout designers can access and complete scene designs in real-time, improving creative efficiency and collaboration.
3. Final Thoughts
From the official release of the Doubao Large Model Family in May 2024 to the Volcano Engine Force Conference· Winter in December, the Doubao (Seed) team has released numerous achievements in just seven months, including Doubao-pro, Seed-TTS, Seed-ASR, Seed-Music, SeedEdit, video generation model, visual language model, continuously improving in terms of language competence, multimodal understanding and generation, model reasoning, code generation, and more.
Many cutting-edge technologies have been applied to consumer-end products such as the Doubao APP and Dreamina, and have served enterprise customers in many industries through Volcano Engine. Currently, Doubao large models' daily token usage has exceeded 4 trillion, with a 33-fold increase in 7 months. Especially in emerging industries such as automobiles, cell phones and smart terminals, Doubao large models' usage has increased by more than 50 times.
In the future, the Doubao (Seed) team will continue to increase investment, focus on the development of valuable key large model technologies, and reduce the cost of large model training and inference to drive the growth of AI applications.
If you're interested in joining the Doubao(Seed) team, please visit our Careers Page to learn more about availab