September 18, 2024
Hi, Seed-Music
Our unified framework enables the generation of music with expressive vocals in multiple languages, allows precise note-level adjustments to model outputs, and offers the ability to integrate users' own voices into music creation, and much more.
Read Tech Report
Overview
We present Seed-Music: a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our methodology, experiments, and solutions are designed to address diverse use cases. Rather than relying on a single modeling approach, such as auto-regression (AR) or diffusion, we propose a unified framework that adapts to the evolving workflows of musicians. Our key contributions are threefold:
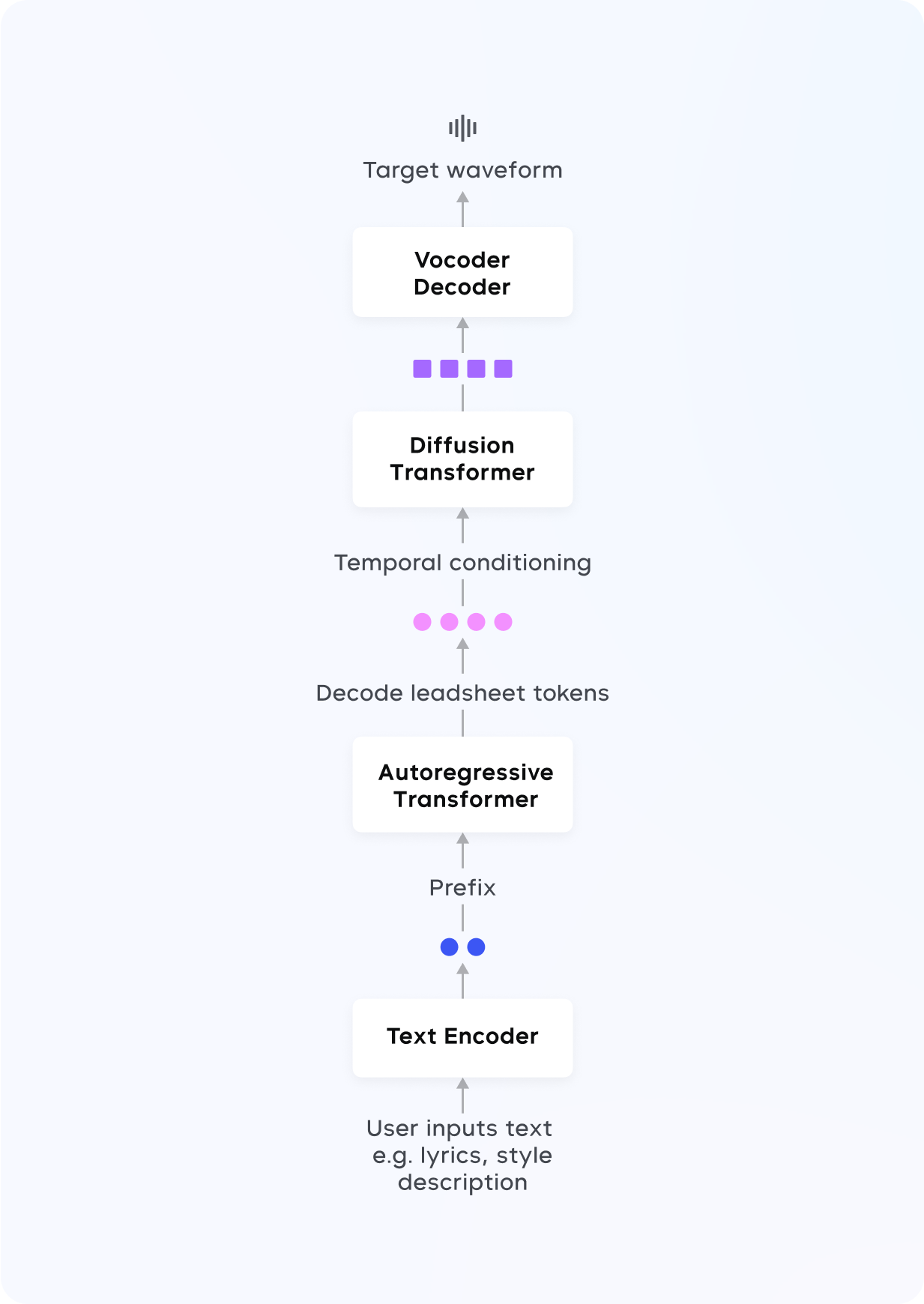
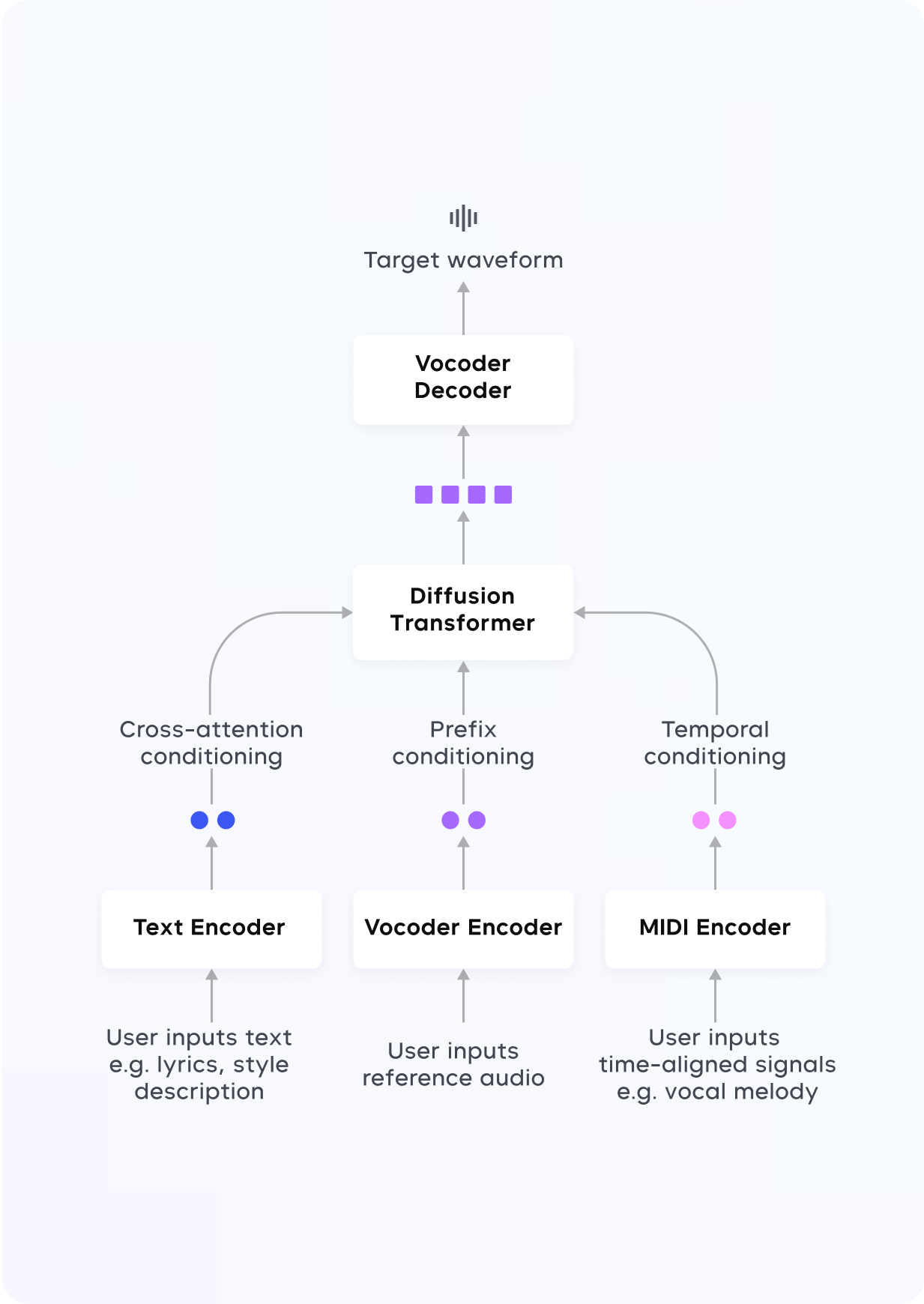
 We introduce an auto-regressive language model (LM) based approach for high-quality vocal music generation conditioned on diverse and multi-modal user inputs.We present a diffusion based approach for fine-grained note-level music audio editing.We propose a novel method for zero-shot singing voice conversion, which requires only 10-second singing or speech recording from a user.
We introduce an auto-regressive language model (LM) based approach for high-quality vocal music generation conditioned on diverse and multi-modal user inputs.We present a diffusion based approach for fine-grained note-level music audio editing.We propose a novel method for zero-shot singing voice conversion, which requires only 10-second singing or speech recording from a user.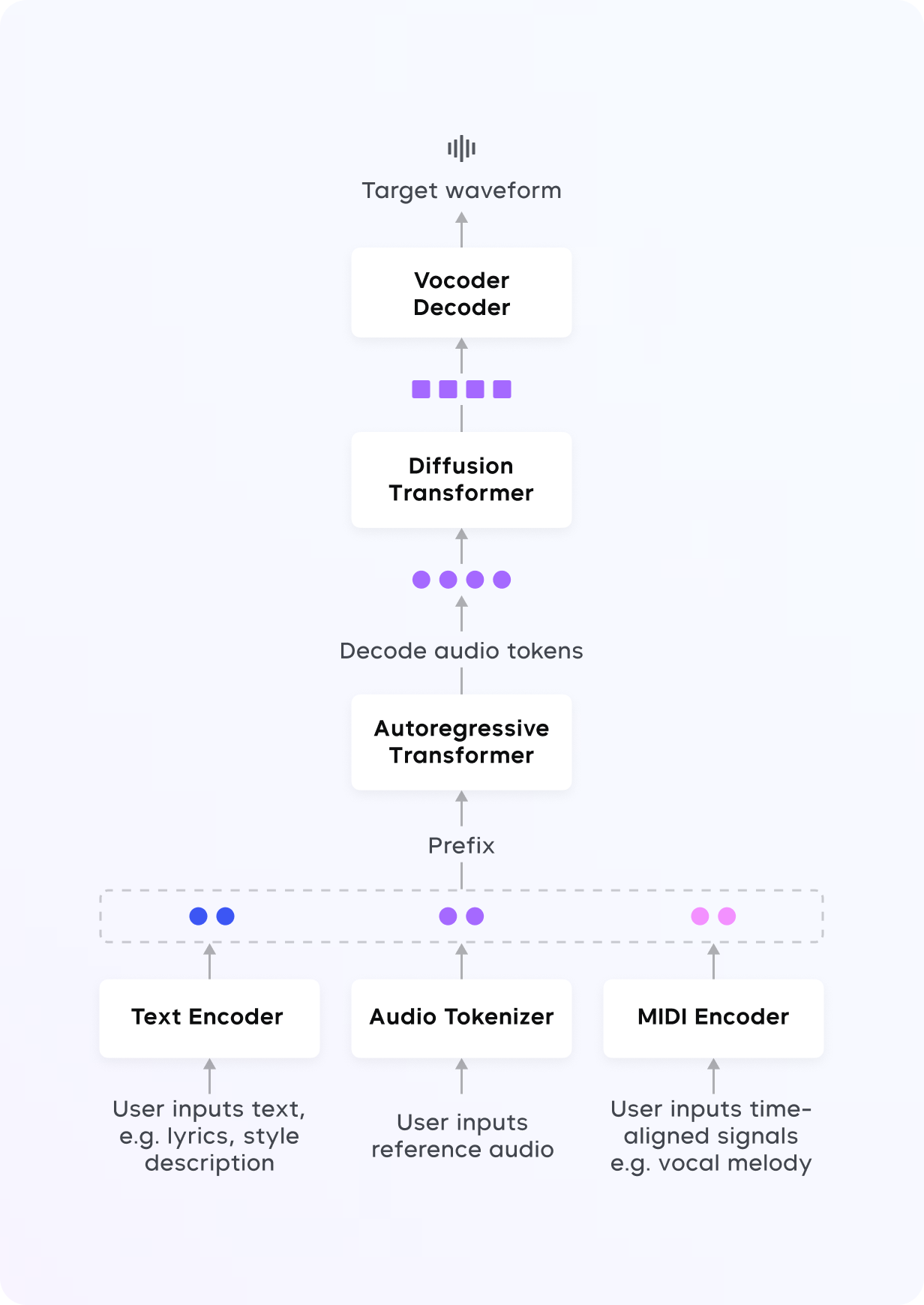
Listening Examples
These sections contain audio samples all generated with Seed-Music. They are presented in the same order as in our technical paper.