直播预告|字节跳动5篇论文中选 ACL 2024 Oral,与多位研究员在线畅聊!
直播预告|字节跳动5篇论文中选 ACL 2024 Oral,与多位研究员在线畅聊!
日期
2024-08-13
分类
学术活动
作为享誉盛名的计算语言学和自然语言处理领域的顶会,ACL 2024 正在泰国曼谷举行。
字节跳动多篇论文被 ACL 2024 录用,其中 5 篇研究成果中选 Oral。 本周,我们将在大会展台(Booth No.09)、晚宴招待会及 Oral 报告环节陆续展示,欢迎大家现场交流!此外,我们还为无法亲临现场的小伙伴安排了 7 篇精选论文解读和在线交流活动。
8 月 20 日(周二)19:00-21:00,「字节跳动 ACL 2024 前沿论文分享会」线上开播!
本次论文分享会将在“豆包大模型团队”视频号、“豆包研究员”小红书号首发直播,并在字节跳动技术团队、稀土掘金社区、机器之心、极市平台、OpenMMLab AI Spot 等合作伙伴平台同步播出,期待你的参与!
豆包大语言模型研究团队负责人王明轩,将携手字节跳动四位研究员黄志超、郑在翔、李朝伟、张欣勃,分享 ACL 部分精彩中选成果,研究方向涉及自然语言处理、语音处理、多模态学习、大模型推理等领域。
活动议程


精选论文解读

RepCodec:一种用于语音离散化的语音表示编解码器
随着大型语言模型(LLMs)近期的快速发展,离散语音标记化在将语音注入 LLMs 中发挥重要作用。然而,这种离散化导致信息的丢失,从而损害整体性能。为提高这些离散语音标记的性能,我们提出了 RepCodec,这是一种用于语义语音离散化的新型语音表示编解码器。
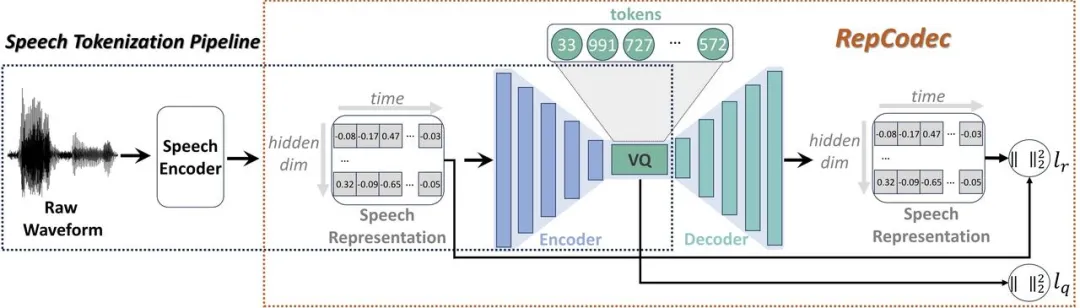
注:Framework of RepCodec
与重建原始音频的音频编解码器不同,RepCodec 通过从诸如 HuBERT 或 data2vec 等语音编码器重建语音表示来学习 VQ 码本。语音编码器、编解码器编码器和VQ码本共同形成了一个将语音波形转换为语义标记的流程。大量实验表明,RepCodec 凭借其增强的信息保留能力,在语音理解和生成方面显著优于广泛使用的 k-means 聚类方法。此外,这种优势在各种语音编码器和语言中都存在,肯定了 RepCodec 的鲁棒性。该方法可以促进语音处理方面的大型语言模型研究。

DINOISER:通过噪声操纵增强的扩散条件序列生成模型
虽然扩散模型在生成诸如图像和音频等连续信号方面取得了巨大成功,但在学习像自然语言这样的离散序列数据仍然存在困难。尽管最近一系列文本扩散模型通过将离散状态嵌入为连续状态隐空间来规避离散性这一挑战,但它们的生成质量仍然不尽人意。
为了理解这一点,我们首先深入分析基于扩散模型的序列生成模型的训练过程,并确定了它们的三个严重问题:(1)学习失败;(2)缺乏可扩展性;(3)忽略条件信号。我们认为这些问题可以归结为嵌入空间中离散性未完全消除的缺陷,其中噪声的规模起决定性作用。
在该工作中,我们提出了 DINOISER,通过操纵噪声来增强用以序列生成的扩散模型。我们在训练阶段以一种受最优传输启发的方式,自适应地确定采样噪声规模的范围,并在推理阶段鼓励该模型通过放大噪声规模来更好地利用条件信号。实验表明,基于所提出的有效的训练和推理策略,DINOISER 在多个条件序列建模基准上优于先前扩散序列生成模型的基线,进一步的分析也验证了 DINOISER 可以更好地利用条件信号来控制其生成过程。

通过减少冗余加快视觉条件语言生成的训练
我们推出了 EVLGen,这是一个为具有高计算需求的视觉条件语言生成模型的预训练而设计的简化框架,利用了冻结的预训练大型语言模型(LLMs)。
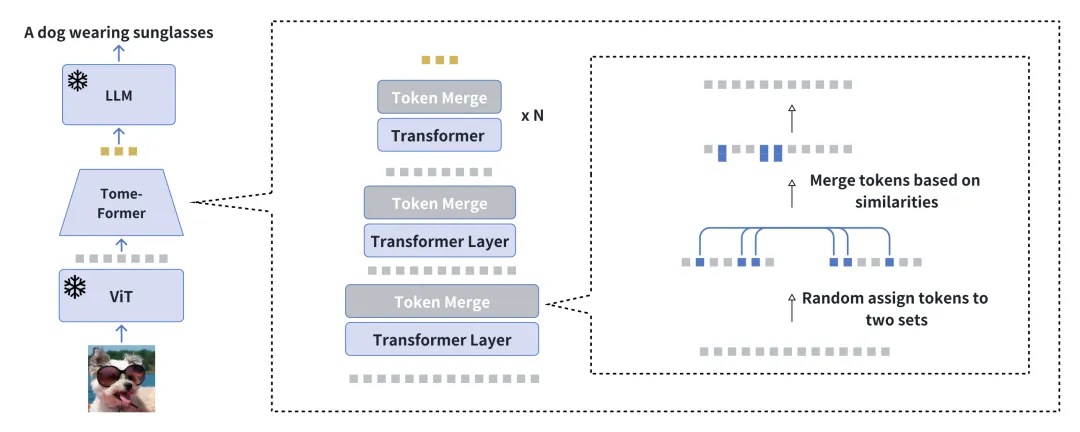
注: Overview of the EVLGen
在视觉语言预训练(VLP)中的常规方法通常涉及一个两阶段的优化过程:一个初始的资源密集型阶段致力于通用的视觉语言表示学习,重点在于提取和整合相关的视觉特征。随后是一个后续阶段,强调视觉和语言模态之间的端到端对齐。我们新颖的单阶段、单损失框架通过在训练期间逐渐合并相似的视觉标记,绕过了计算要求很高的第一个训练阶段,同时避免了 BLIP-2 类型模型的单阶段训练所导致的模型崩溃。逐渐合并的过程有效地压缩了视觉信息,同时保留了语义丰富性,在不影响性能的情况下实现了快速收敛。
实验结果表明,我们的方法将视觉语言模型的训练速度提高了 5 倍,而对整体性能没有明显影响。此外,我们的模型仅使用 1/10 的数据就显著缩小与当前视觉语言模型的性能差距。最后,展示了我们的图像 - 文本模型如何通过新颖的软注意力时间,标记上下文模块无缝适应视频条件语言生成任务。

StreamVoice:用于实时零样本语音转换的可流式上下文感知语言建模
流式零样本语音转换(streaming zero-shot voice conversion)是指能够实时将输入语音转换成任意说话人的语音,且仅需要该说话人一句语音作为参考,且无需额外的模型更新。现有的零样本语音转换方法通常是为离线系统设计,难以满足实时语音转换应用对于流式能力的需求。近期基于语言模型(language model, LM)的方法在零样本语音生成(包括转换)上展现出卓越的性能,但是需要整句处理而局限于离线场景。
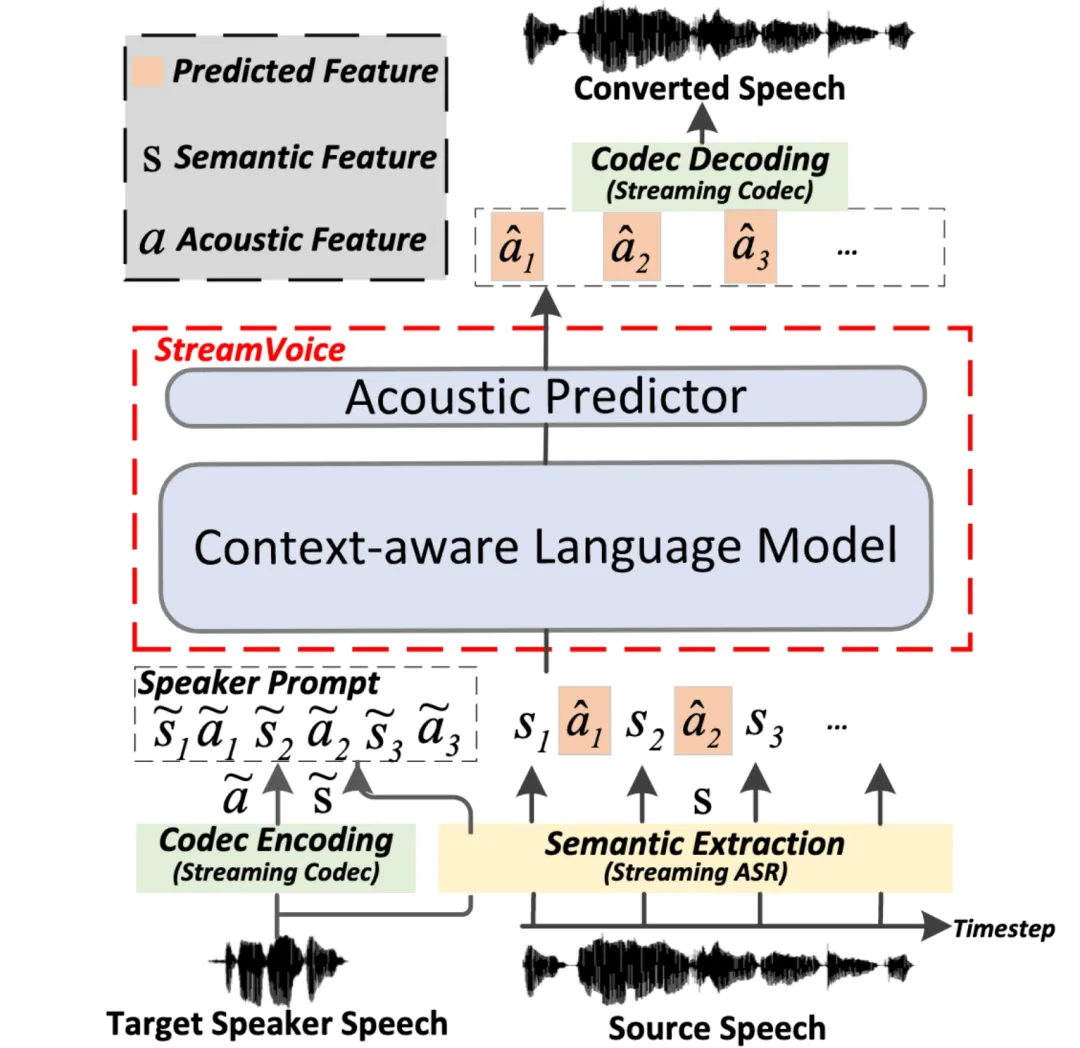
注:The overall architecture for StreamVoice
在该工作中,我们提出 StreamVoice,一个新的基于流式 LM 的零样本语音转换模型,实现针对任意说话人和输入语音的实时转换。具体来说,为了实现流式能力,StreamVoice 使用上下文感知的完全因果 LM 以及时序无关的声学预测器,同时自回归过程中交替处理语义和声学特征消除了对完整源语音的依赖。
为了解决流式场景下不完整上下文所导致的性能下降,通过两种策略来增强 LM 对于未来和历史的上下文感知能力:1)教师引导的上下文预知(teacher-guided context foresight),通过教师模型来总结当下和未来准确的语义来指导模型对缺失上下文的预测;2)语义掩蔽策略,鼓励模型从先前损坏的语义输入实现声学预测,增强对于历史上下文的学习能力。实验表明,StreamVoice 具有流式转换能力,同时实现了接近非流式 VC 系统的零样本性能。

G-DIG:致力于基于梯度的机器翻译多样化和高质量指令数据选择
大型语言模型(LLMs)在一般场景中展现出了非凡的能力。指令微调使它们能够在各种任务中与人类保持一致。然而,指令数据的多样性和质量仍然是指令微调的两个主要挑战。对此,我们提出了一种新颖的基于梯度的方法,为机器翻译自动选择高质量和多样化的指令微调数据。我们的关键创新在于分析单个训练示例在训练过程中如何影响模型。
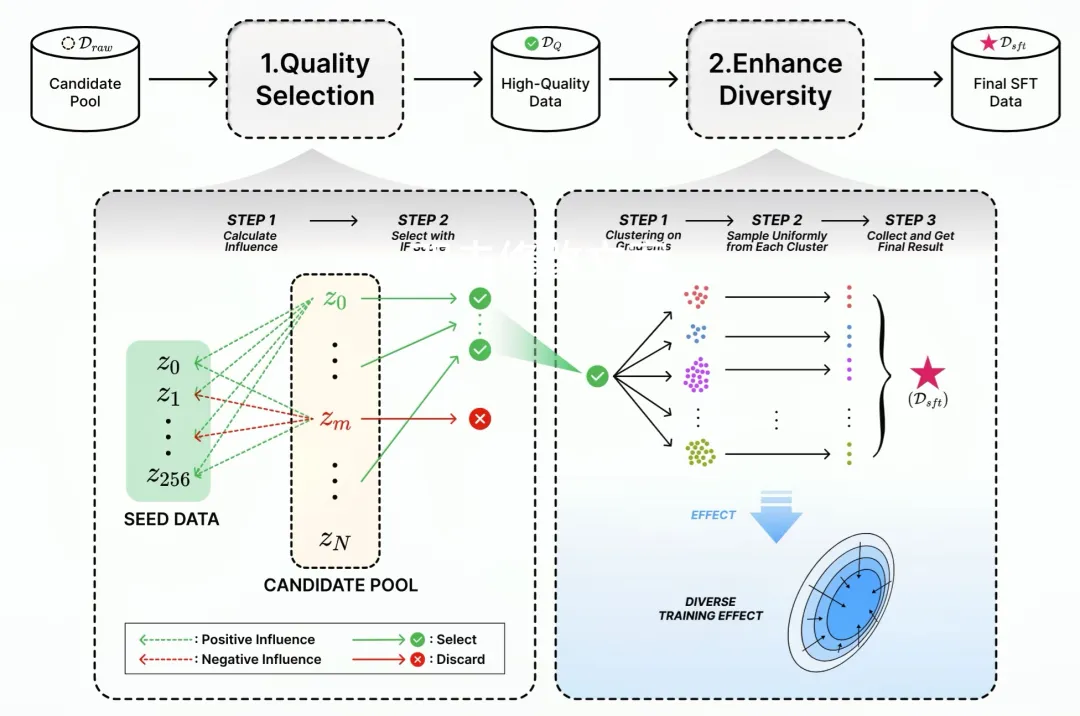
注:Overview of G-DIG
具体来说,我们借助影响函数和一个小型高质量种子数据集,选择对模型产生有益影响的训练示例作为高质量示例。此外,为了增强训练数据的多样性,我们通过对它们的梯度进行聚类和重新采样,最大程度地增加它们对模型影响的多样性。在 WMT22 和 FLORES 翻译任务上的大量实验证明了我们方法的优越性,深入的分析进一步验证了其有效性和通用性。

GroundingGPT:语言增强的多模态 Grounding 模型
多模态大语言模型在不同模态的各种任务中都展示出了出色的性能。然而此前的模型主要强调捕获多模态输入的全局信息,因此这些模型缺乏有效理解输入数据中细节的能力,在需要对输入细致理解的任务中表现不佳,同时这些模型大多存在严重的幻觉问题,限制了其广泛使用。
为了解决这一问题,增强多模态大模型在更广泛任务中的通用性,我们提出了 GroundingGPT,一种能够实现对图片、视频、音频不同粒度理解的多模态模型。我们提出的模型除了捕获全局信息外,还擅长处理需要更精细理解的任务,例如模型能够精确定位图像中的特定区域或视频中的特定时刻。为了实现这一目标,我们设计了多样化的数据集构建流程,从而构造了一个多模态、多粒度的训练数据集。在多个公开 benchmark 上的实验证明了我们模型的通用性和有效性。

ReFT:基于强化微调的推理
一种常见的增强大型语言模型(LLMs)推理能力的方法是使用思维链(CoT)标注数据进行有监督微调(SFT)。然而,这种方法并没有表现出足够强的泛化能力,因为训练仅依赖于给定的 CoT 数据。具体地,在数学问题的相关数据集中,训练数据中每个问题通常只有一条标注的推理路径。对于算法来说,如果能针对一个问题学习到多种标注的推理路径,会有更强的泛化能力。
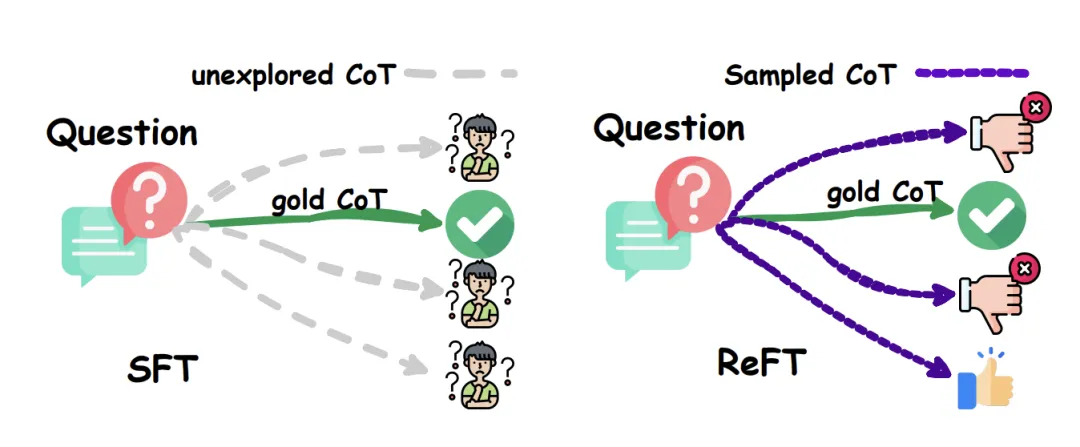
注:Comparison between SFT and ReFT on the presence of CoT alternatives
为解决这个挑战,以数学问题为例,我们提出了一种简单而有效的方法,称为强化微调(Reinforced Fine-Tuning,ReFT),以增强 LLMs 推理时的泛化能力。ReFT 首先使用 SFT 对模型进行预热,然后采用在线强化学习(在该工作中具体是 PPO 算法)进行优化,即对给定的问题自动采样大量的推理路径,根据真实答案获取奖励,以进一步微调模型。
在 GSM8K、MathQA 和 SVAMP 数据集上的大量实验表明,ReFT 显著优于 SFT,并且通过结合多数投票和重新排序等策略,可以进一步提升模型性能。值得注意的是,这里 ReFT 仅依赖与 SFT 相同的训练问题,而不依赖于额外或增强的训练问题。这表明 ReFT 具有优越的泛化能力。
期待你的互动提问
直播时间: 2024 年 8 月 20 日(周二) 19:00-21:00
直播平台: 微信视频号【豆包大模型团队】、小红书号【豆包研究员】
欢迎你填写问卷告诉我们,关于 ACL 2024 论文你感兴趣的问题,在线和多位研究员畅聊!

豆包大模型团队持续热招中,欢迎点击阅读全文,了解团队招聘相关信息。