豆包视觉理解模型正式发布,通用模型能力全面对齐GPT-4o!
豆包视觉理解模型正式发布,通用模型能力全面对齐GPT-4o!
日期
2024-12-18
分类
技术发布
豆包·视觉理解模型于 12 月 18 日在火山引擎 Force 原动力大会首次亮相。该模型具备非常强的内容识别能力,同时,拥有出色的理解推理和细腻的视觉描述表现。
一同亮相的,还有升级版豆包主力通用模型、豆包·音乐生成模型、豆包·文生图模型等。本文将从技术视角介绍此次发布的重点。
现在,豆包大模型可以“看懂”世界了。
今天,在火山引擎 Force 原动力大会现场,豆包大模型家族公布新成员“豆包·视觉理解模型”。它不仅具备强大的视觉感知能力,还能融合视觉与语言输入,进行综合的深度思考和创作。
根据图像信息,豆包·视觉理解模型可以完成诸多复杂的逻辑计算任务,包括解微积分题、分析论文图表、诊断真实代码问题等挑战性任务。
点击下方视频,直观了解豆包·视觉理解模型的强大能力:
除豆包·视觉理解模型外,本次还官宣了豆包主力通用模型、豆包·音乐生成模型、豆包·文生图模型升级,3D 模型也一并发布。
1. 视觉理解模型不仅能“看”,还能“思考”
视觉,是人类理解这个世界最重要的手段。对大模型而言也是如此,掌握完备的视觉理解能力,才能处理好真实世界的信息,辅助人类完成一系列复杂工作。
通过豆包·视觉理解模型,用户可以同时输入文本和图像相关的问题,模型经综合理解,可给出准确的回答。这将极大地简化开发流程,解锁更多的大模型价值场景。
为了支持上述需求,豆包·视觉理解模型提供三大能力:
更强的内容识别能力
豆包·视觉理解模型有非常强的内容识别能力,不仅可以识别出图像中的物体类别、形状、纹理等基本要素,还能理解物体之间的关系、空间布局以及场景的整体含义,甚至背后的文化知识。
具体来说,视觉理解模型不仅可以识别现实中的物品,还能根据光影、轮廓、位置等特征,一眼识别出小动物的影子,并“认出”这是一只猫。
当你在清晨跑步,看到光线从树林间洒出来,可以随手拍张照,问问豆包大模型这是什么科学现象,它能识别这是丁达尔效应并科普原理。
更强的理解推理能力
豆包·视觉理解模型也具备出色的理解和推理能力。模型不仅能识别图文信息,还能进行复杂的逻辑计算。拍下一道需要进行微积分运算的数学题,豆包·视觉理解模型能很好地理解图片问题,并根据提示词进行对应的推理计算,给出答题思路。
学术论文同样也能读懂。
对于下面这篇论文《How Far is Video Generation from World Model: A Physical Law Perspective》中的图表,模型可以做到准确理解并解析图表呈现出的趋势与结论。
“看”代码同样不在话下,模型能识别真实代码的用途,并介绍每行代码分别在实现什么操作。
更细腻的视觉描述能力
除却识别与理解推理能力,豆包·视觉理解模型还有着非常细腻的视觉描述和创作能力。
当你想设计一款文创产品赠送客户,模型可基于产品的造型或寓意写一段真挚走心的祝福语。
一张小孩的涂鸦画,足够让豆包·视觉理解模型创作一个奇幻的故事。
至于应用方面,豆包·视觉理解模型可落地图片问答、医疗健康、教育科研、电商购物、生活助手等诸多场景。
2. 通用模型能力全面对齐 GPT-4o,视频生成模型即将开放企业服务
主力通用模型升级,全面对齐 GPT-4o
视觉理解模型之外,大会现场还官宣了豆包语言大模型的升级。
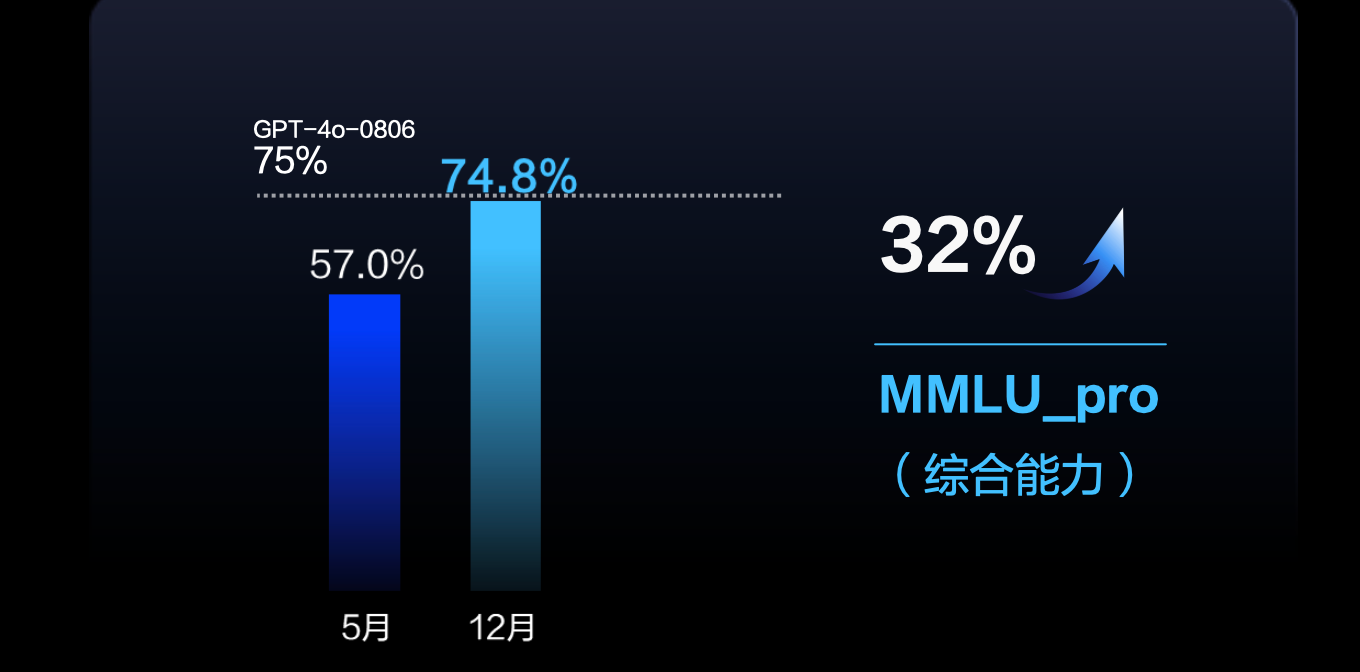
相比 5 月版本,豆包最强模型 Doubao-pro 能力大幅提升。面向 MMLU_pro 评测集,模型综合能力提升 32%,和 GPT-4o 持平,使用价格仅为 GPT-4o 的八分之一。
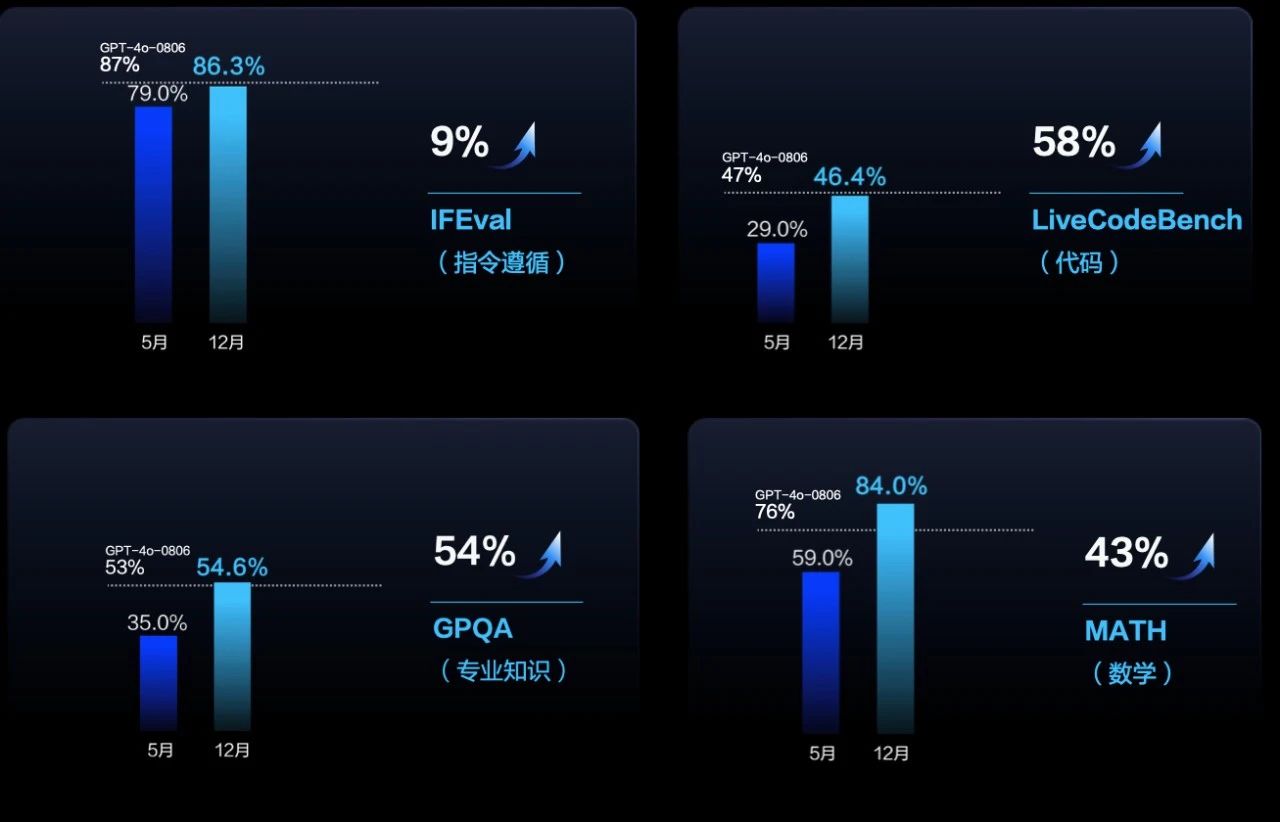
Doubao-pro 指令遵循能力提升 9%,代码能力提升 58%,GPQA 专业知识方面能力提升 54%,数学能力提升 43%,推理能力提升 13%,全面对齐 GPT-4o 水平。
豆包·视频生成模型即将面向企业开放服务
9 月 24 日,豆包·视频生成模型发布,此后,该模型通过即梦 APP 和网页端已对 C 端用户开放使用,经由创作者之手,诞生出很多精美视频。
面向企业客户和开发者,豆包·视频生成模型将于 1 月依托火山引擎正式对外开放服务。
音乐模型、文生图模型升级
豆包·音乐模型,首次发布于 2024 年 9 月,时隔 3 个月后,已能支持 3 分钟的完整音乐作品生成,实现包括前奏、主歌、副歌、间奏、过渡段等复杂结构的作品创作。
此外,全新版本模型可合理运用旋律、节奏、和声等信息,使全曲保持在风格、情感等音乐元素上的连贯性。如对生成歌词不满意,还可进行局部修改,给原调赋新词,让音乐创作更自由灵活。
文生图模型新增“一键 P 图,一键海报”技能。
基于豆包大模型团队成果 SeedEdit,豆包文生图模型 2.1 版支持通过自然语言对图像进行“一键 P 图”,包括换装、美化、涂抹、风格转化等任意编辑指令。
同时,豆包文生图模型还支持“一键海报”,可实现精准控制的文字图案生成。通过打通 LLM 和 DiT 构架,豆包文生图模型构建了高质量文字渲染能力,可大幅提升文字生成准确率。这种原生的文字渲染能力,让文字与整体画面的融合更为自然和实用。
豆包 3D 模型发布
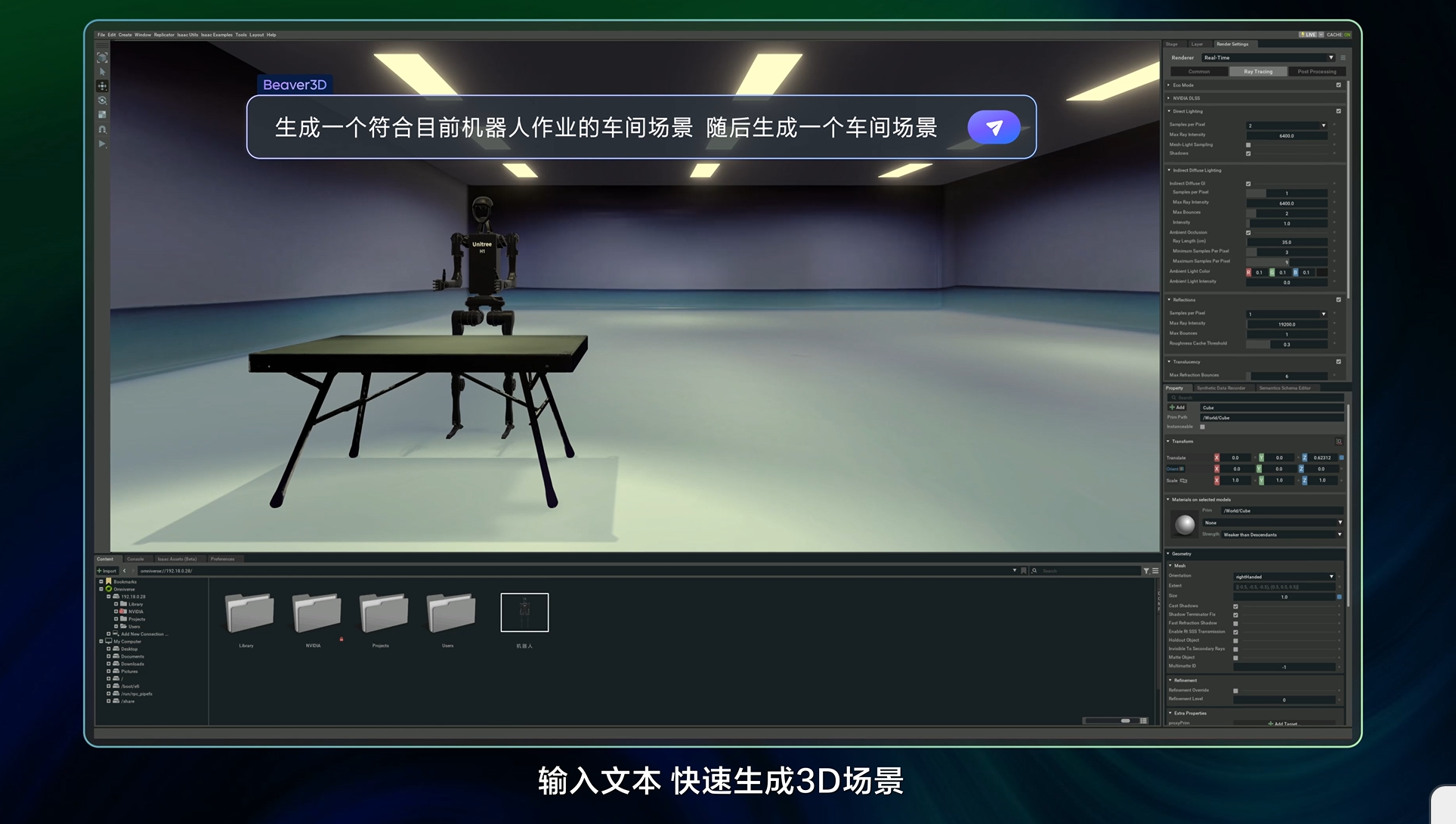
面向 3D 仿真领域,豆包大模型家族新增 3D 生成模型,该模型采用 3D-DiT 架构,可生成高质量 3D 模块。该模型与火山引擎数字孪生平台 veOmniverse 结合使用,可以高效完成智能训练、数据合成和数字资产制作,成为一套支持 AIGC 创作的物理世界仿真模拟器。
举例来说,用户只需输入文本,即可实时生成并搭建起一个工厂车间场景。通过快速批量生成并上传至云空间,布局师可实时调用并完成场景设计,提升创作效率和协作体验。
3. 写在最后
自 2024 年 5月豆包大模型家族正式发布,到 12 月冬季原动力大会,短短 7 个月时间,豆包大模型团队发布了 Doubao-pro、Seed-TTS、Seed-ASR、Seed-Music、SeedEdit、视频生成模型、视觉理解模型等多项重磅成果,在语言能力、多模态理解与生成、模型推理、代码生成等方面不断提升。
不少前沿技术已应用于豆包 APP、即梦等 C 端产品,并通过火山引擎服务众多行业的企业客户。目前,豆包大模型日均 tokens 调用量突破 4 万亿,7 个月增长幅度达 33 倍。尤其在汽车、手机、智能终端等新兴行业,豆包大模型调用量增长了 50 倍以上。
未来,豆包大模型团队将持续加大投入,着眼研发真正关键、有价值的大模型技术,并不断降低大模型训练推理成本,促进 AI 应用繁荣。
如果你也对豆包大模型团队的工作感兴趣,欢迎欢迎前往招聘页面,了解岗位详情。