首次覆盖超 11 类真实编程场景!豆包大模型团队开源代码大模型全新基准
首次覆盖超 11 类真实编程场景!豆包大模型团队开源代码大模型全新基准
日期
2024-12-05
分类
技术发布
今天,字节跳动豆包大模型团队开源 FullStack Bench,一个专注于全栈编程和多语言编程的代码评估数据集。
该数据集在业界首次囊括编程全栈技术中超 11 类真实场景,覆盖了 16 种编程语言,包含 3374 个问题,相比此前基准,可以更有效地评估大模型在现实世界中的代码开发能力。同时,高效的代码沙盒执行工具 SandboxFusion 也一起开源,用于评估来自不同语言的不同编程任务。
综合实验结果表明,FullStack Bench 能够真实反映大模型在多种实际代码开发场景中的表现,有助于推动代码智能领域的进一步发展。
代码大型语言模型(code LLMs)在代码智能方面取得了显著的进步,为了揭示现有代码 LLMs 的局限性并推动代码智能的进一步发展,多个代码评估基准数据集相继被提出,如 HumanEval、MBPP、DS-1000、McEval、MDEval 和 xCodeEval 等。
然而,当前的评测基准覆盖的编程语言和应用类型较为有限,难以全面反映真实世界中代码开发场景所涉及的各种编程能力。如 HumanEval 和 MBPP 中大部分数据(近 80%)只聚焦于基础编程问题和高级编程问题。
为了解决上述限制,字节跳动豆包大模型团队与 M-A-P 开源社区联合提出 FullStack Bench,一个涵盖多个真实应用领域和编程语言的评估集,旨在评估大型模型在各种真实世界代码开发场景中的能力。
为了支持 FullStack Bench 对多领域多语言编程的评测需求,团队开发了一个新的沙盒执行环境——SandboxFusion,该环境支持 23 种常用编程语言,能够满足不同应用场景(如前端开发、后端开发和机器学习训练等)的需求。
综合实验结果表明,FullStack Bench 能够真实反映大型语言模型(LLMs)在多种实际代码开发场景中的表现,为代码智能领域的进一步发展提供推动力量。

目前论文成果、数据集、沙盒体验入口均已对外公开。
FullStack Bench: Evaluating LLMs as Full Stack Coders
论文链接: https://arxiv.org/abs/2412.00535
数据集开源地址: https://huggingface.co/datasets/ByteDance/FullStackBench
沙盒开源地址: https://github.com/bytedance/SandboxFusion
沙盒体验入口: https://bytedance.github.io/SandboxFusion/playground/datasets
1. 多领域多语言代码评估基准存在空白
在代码大语言模型发展的过程中,代码评估基准扮演了至关重要的角色。它们不仅是衡量模型能力的标准工具,也是推动模型优化和完善的关键驱动力。
尽管代码评估基准在研究和应用大语言模型中起着核心作用,但此前业界基准仍然存在明显的局限,尤其是在反映真实世界代码开发场景的多样性和复杂性方面。
例如,HumanEval 和 MBPP 中大部分数据(近 80%)只聚焦于基础编程问题和高级编程问题;DS-1000 大部分数据(超过 95%)集中于数据分析和机器学习任务,且仅对 Python 语言进行评测;xCodeEval 虽覆盖多项任务,但基本局限于高级编程和数学领域;McEval 和 MDEval 分别扩展了支持的编程语言,涵盖了 40 种和近 20 种语言,但其应用领域仍然局限于基础编程问题和高级编程问题,未能涉及更广泛的应用场景。
此外,自动化评估一个多任务多语言的代码基准仍然面临诸多挑战。尽管出现了一些沙盒执行环境,如 DifySandbox、MultiPL-E 和 MPLSandbox,但它们仍存在显著局限性,如不支持前端浏览器和深度学习包,且支持的编程语言数量有限。
2. 构建全栈多语言代码评测基准 FullStack Bench
为模拟全栈开发的实际应用场景,研究团队分析了全球最大的程序员技术问答社区 Stack Overflow 上的问题分布,从中提炼出常见的真实编程应用领域。如图所示,团队从 Stack Overflow 上随机抽取了 50 万个问题,并使用大模型为每个问题标注其所属的应用领域类型。
研究团队筛选出占总问题数前 88.1% 的主要应用领域,其余领域统一归类为“其他”。基于此,团队完成了问题领域类型的标注,再通过对分布做适当调整来保证每个领域的鲁棒性,最终形成了 FullStack Bench 关注的超过 11 种应用场景及分布比例。具体领域类型的详细介绍可参见原文。

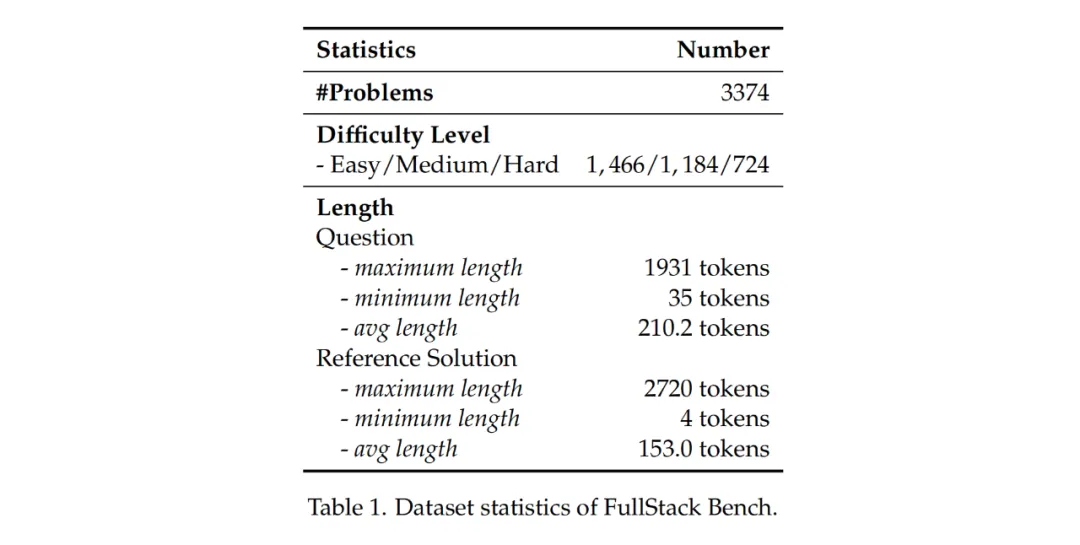
FullStack Bench 包含 3374 个问题(中文及英文问题各占一半),每个问题均包括题目描述、参考解决方案、单元测试用例及标签。为保证评估准确性,每个问题内容均由相关领域的编程专家设计,并经 AI 和人工验证进行质量复核。例如,数据分析相关问题,由数据工程专家提出并把关配套内容。
FullStack Bench 的构建采用了一套全面且系统的人工标注流程,用于生成不同应用领域的代码样本。研究团队从 GitHub 和代码相关文档中收集多种编程语言的代码片段,结合大语言模型(LLM)和人工验证生成指令、单元测试用例及参考解决方案。
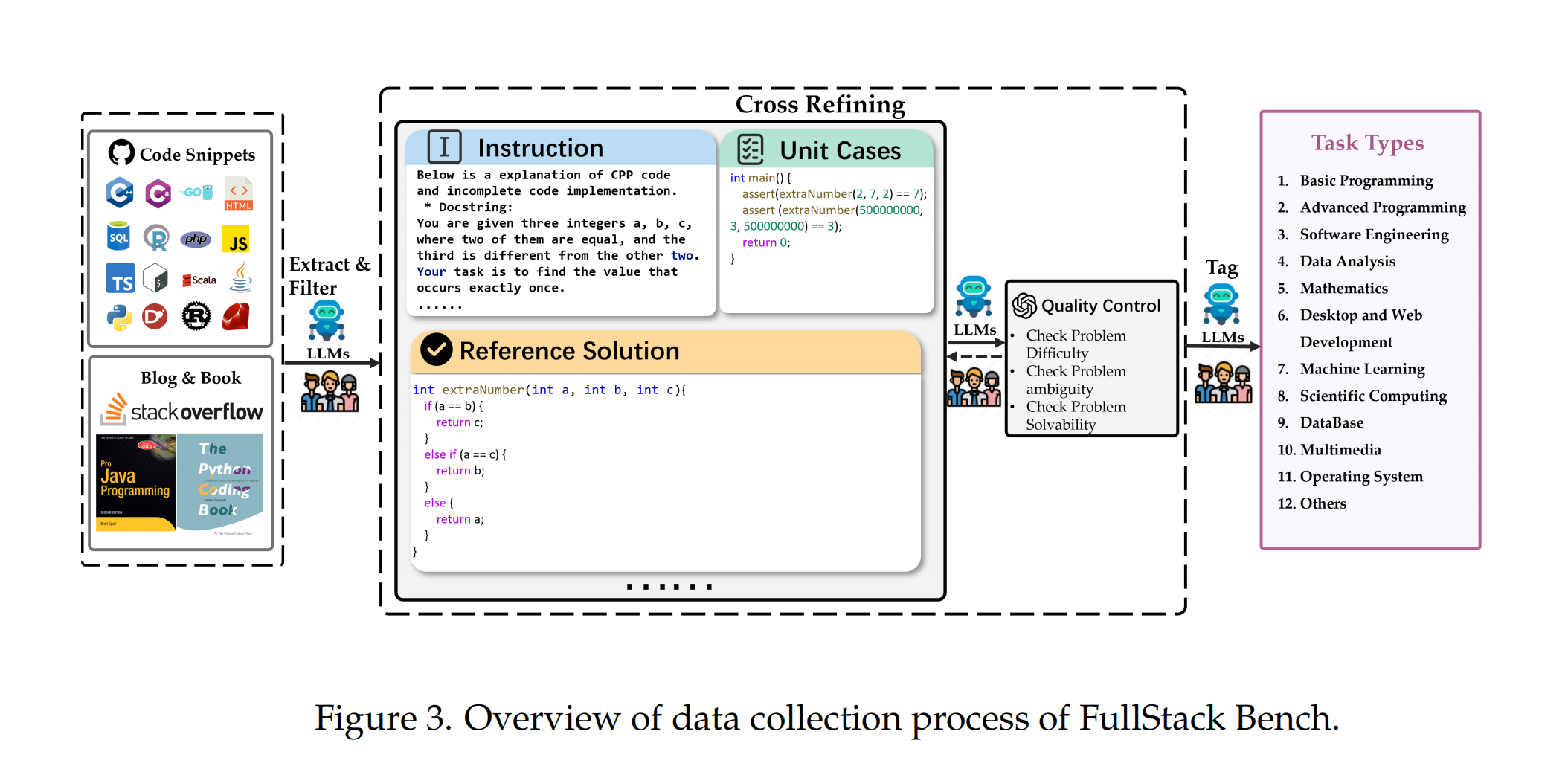
在初始数据集构建后,标注者依据问题难度、模糊性和可解性评估数据质量,并通过交叉复核减少主观偏差。分歧通过共识或高级标注者介入解决,以确保数据准确性。
在完成 FullStack Bench 的构建后,研究人员对其进行了统计分析,结果如图所示。研究人员使用 LLaMA3 分词器计算了题目和正确代码的标记长度,其中题目平均长度为 210.2 个 tokens。为确保评估的准确性,数据集包含总计 15168 个单元测试,平均每个问题配备 4.5 个单元测试用例。
3. SandboxFusion:高效的代码沙盒执行工具
为方便开发者对大模型代码能力进行系统性测试,豆包大模型团队还开源了一款高效的代码沙盒执行工具——SandboxFusion,用于评估来自不同语言的不同编程任务。除了 FullStack Bench,SandboxFusion 还兼容超过 10 种广泛使用的代码评估数据集,支持 23 种编程语言。开发者在单服务器上即可轻松部署 SandboxFusion,也可直接在 GitHub 上进行体验。
SandboxFusion 主要包含两个模块:数据集模块和沙箱执行模块。数据集模块负责实现各种数据集,并提取出可重用的公共组件。沙箱执行模块则专注于在不同语言中执行代码,控制资源使用,并确保执行的安全性。
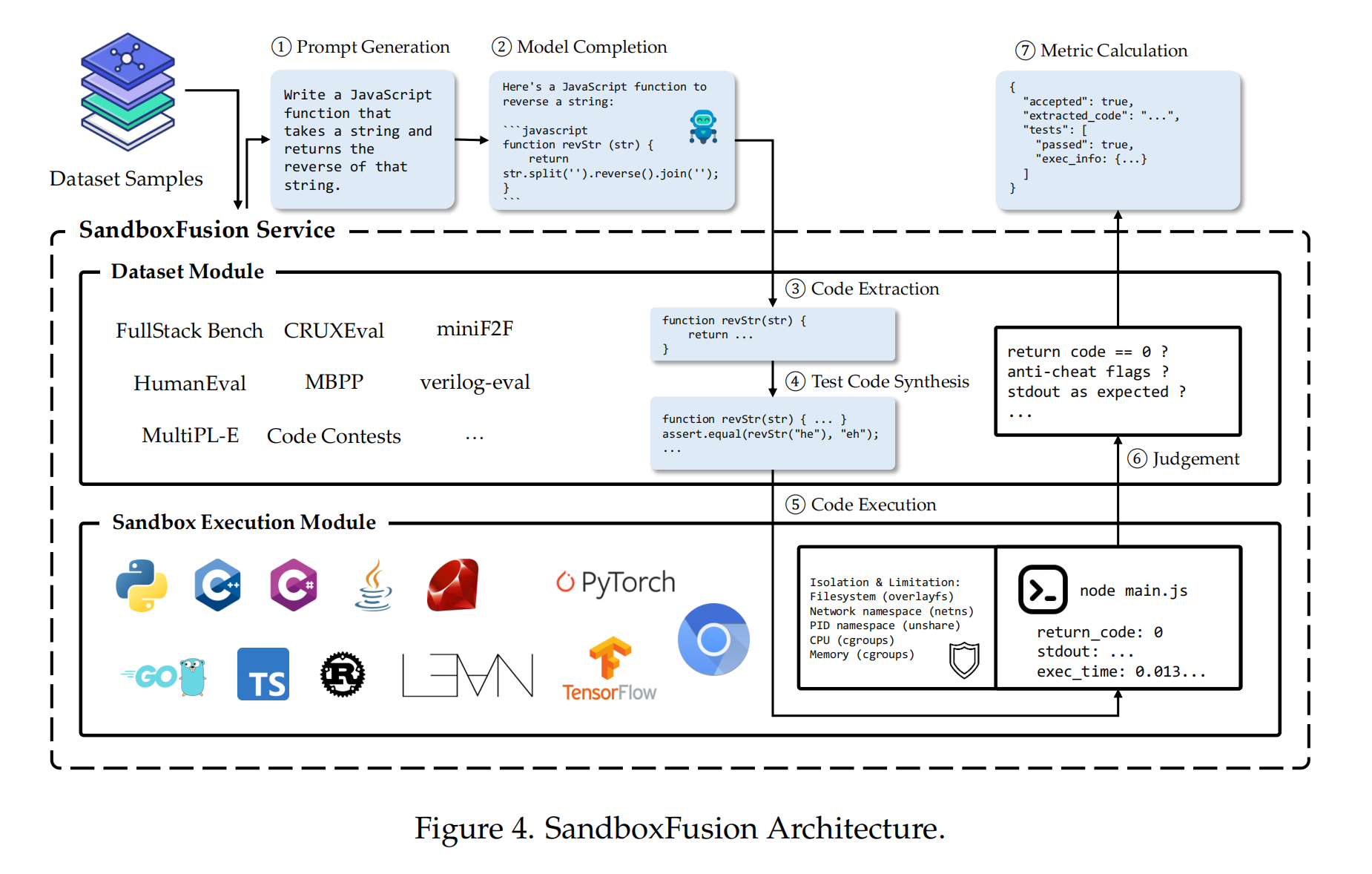
如图所示,SandboxFusion 的评估流程包括以下步骤:
提示生成: 根据原始数据和测试模式(如少样本、零样本)生成不同提示。
模型推理: 用户需要独立使用生成的提示进行模型补全,沙盒未内置推理模块。
代码提取: 系统从模型输出中提取可执行代码段,主要关注 markdown 中包含的代码。
测试代码合成: 系统将提取的代码与预定义的测试用例结合,创建可执行的测试程序。此过程处理语言相关的特性,如在 Java 中将类拆分到文件或为单元测试调整入口函数。
代码执行: 系统执行合成的代码及所有依赖文件,并捕获程序输出。
结果判断: 系统基于执行结果评估模型输出的正确性,通常通过标准单元测试框架,其中零返回值表示执行成功。
指标计算: 在沙盒外部聚合计算评估指标,以通过率为主。
4. 评测结果:解决难题,闭源模型仍优于开源模型
发布评测基准及沙盒的同时,研究团队也基于 FullStack Bench 对全球二十余款代码大模型及语言大模型的编程表现进行了评测。这些模型包括 Qwen2.5-Coder、DeepSeek-Coder-v2、CodeLlama 等开源模型,以及 GPT-4o、OpenAI-o1、Doubao-Coder-Preview 等闭源模型。对于开源模型,根据模型大小,分为五个组别:1B+、6B+、13B+、20B+ 和 70B+。更多实验配置和测试细节,请参阅完整论文。
- 跨领域表现:数学编程领域差异最大
得益于强大的推理能力,OpenAI o1-preview 不出所料地领先。不过,一些开源模型也有不错的表现。如 DeepSeekCoderv2-Instruct,在 AP(高级编程)、OS(操作系统)和其他类别中得到高分,拉开了与其他开源模型的差距。OpenCoder-1.5B-Instruct、Qwen2.5-Coder-7B-Instruct、Qwen2.5-Coder-14B-Instruct 在其各自的开源组别中拔得头筹,并超越了一些更高参数级别的模型。
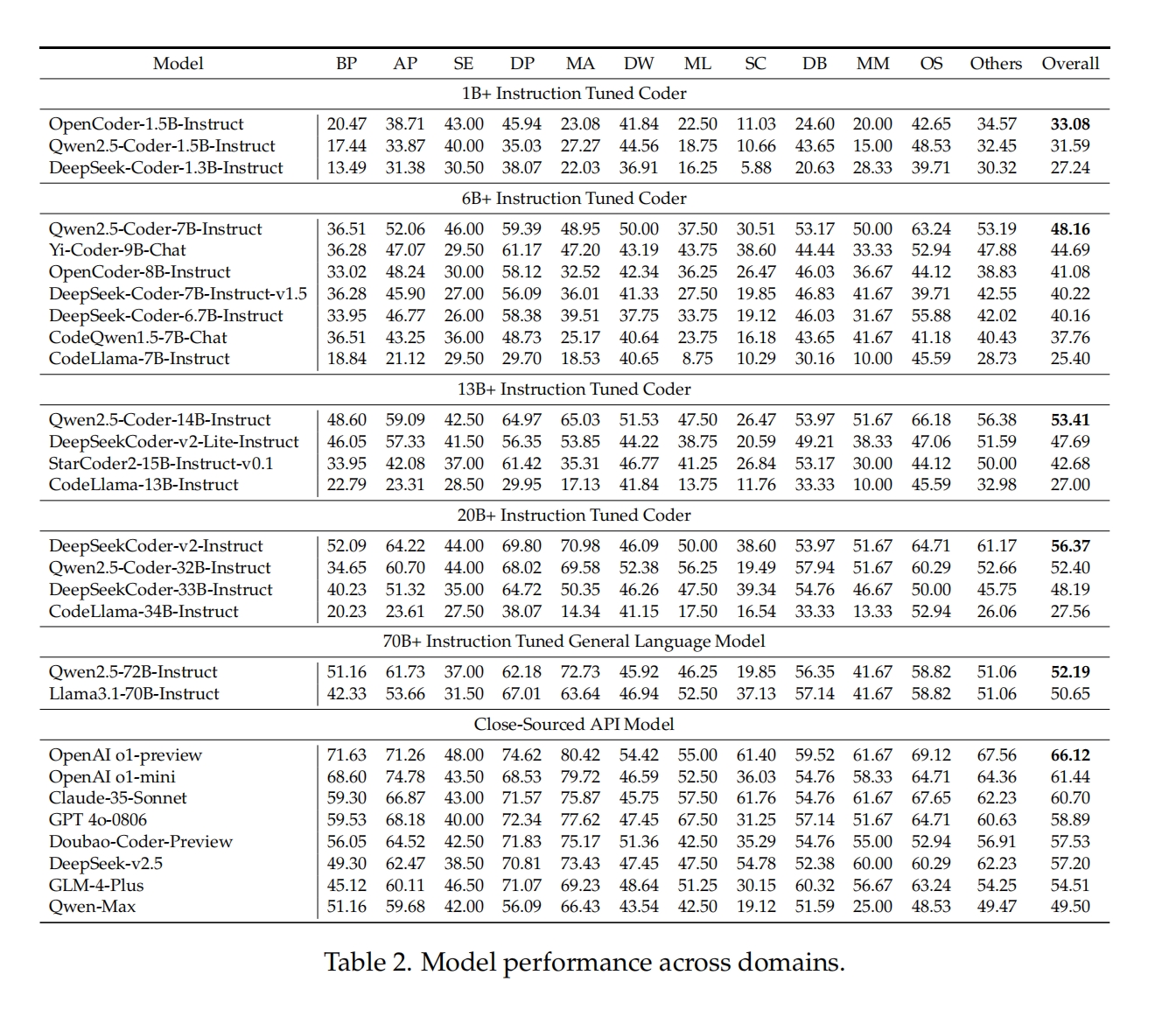
为了全面评估现有大语言模型在不同场景下的表现,研究团队可视化了模型在 FullStack Bench 各领域的表现。在 BP(基础编程)、AP(高级编程)、MA(数学编程)、ML(机器学习)和 MM(多媒体)等领域中,模型表现差异显著,其中以 MA 领域的差距最大。最佳表现者为 OpenAI o1-preview(得分 80.42),而最差的是 CodeLlama-34B-Instruct(得分 14.34)。数学编程要求模型同时具备数学和编程能力,那些在高度专业化代码语料库上训练的模型,在 MA 领域往往表现较差。这一结果进一步证明,FullStack Bench 能够更全面地评估模型的综合编程能力。
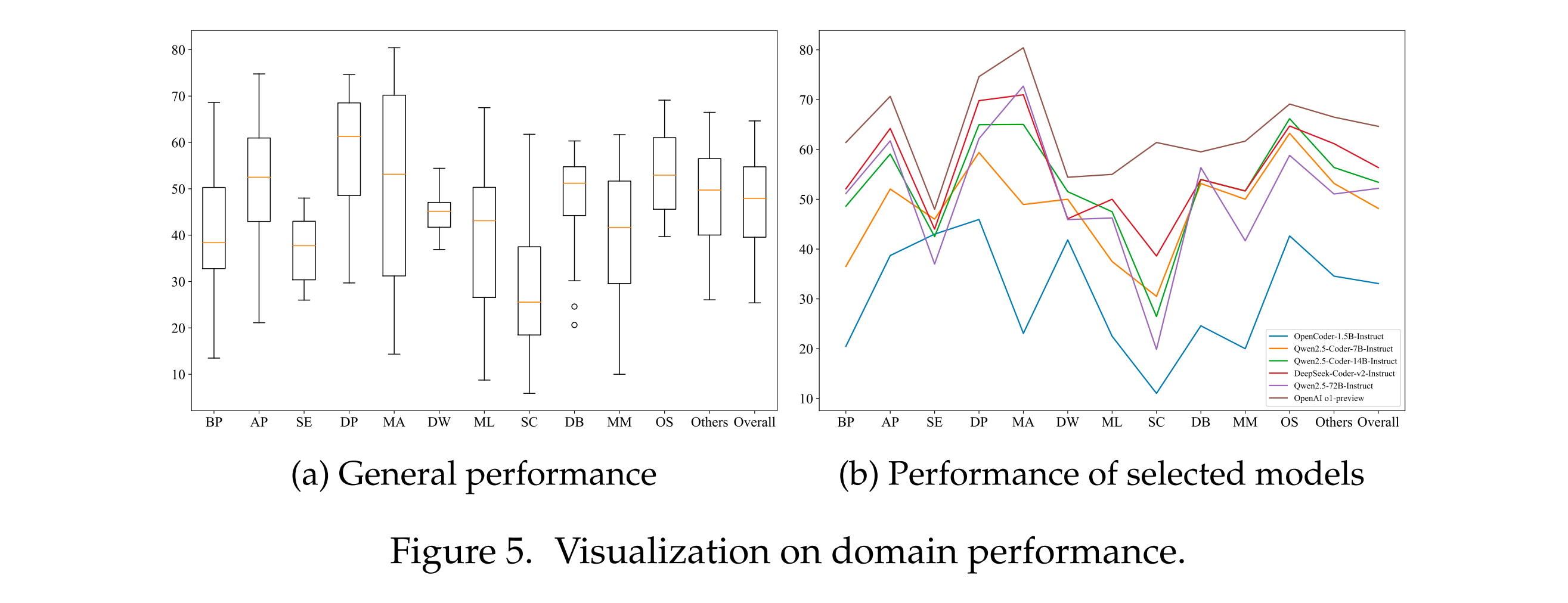
- 跨语言表现:C++、C 和 Ruby 上存较大差异
研究团队对不同模型在多种编程语言上的性能表现进行了分析,结果如图所示。大多数模型在 Bash 编程任务中表现良好。然而,在 C++、C 和 Ruby 的表现上存在较大差异,这表明模型设计者可能在训练语料库中对这些语言进行了选择性采样。部分 1B+ 的小型模型在 D、R 和 Scala 语言上的表现较差,其通过率低于 10%,这表明它们的多语言处理能力都较弱。
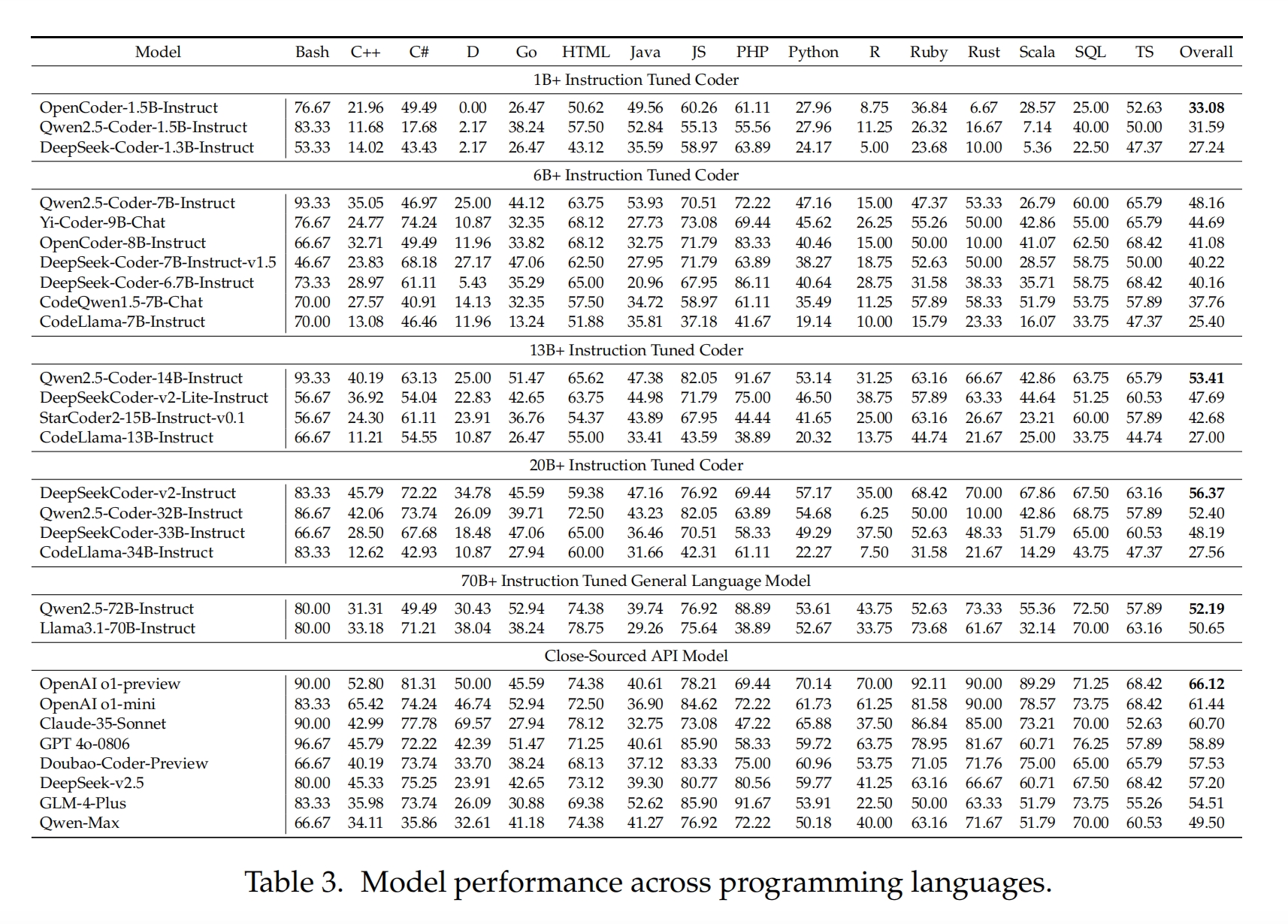
由于 SandboxFusion 提供了来自编译器的反馈,研究人员评估了模型在部分编程语言上的编译通过率。实验结果表明,编译通过率与测试通过率之间存在正相关关系,但编译通过并不意味着测试一定通过。同时,研究人员还探讨了中英文表达对模型性能的影响。
- 解决难题,闭源模型普遍优于开源模型
不同模型在不同难度问题上的表现存在明显差异。总体而言,1B+ 模型和 CodeLlama 系列在所有难度级别上的表现均不尽如人意。其余模型在解决简单问题时表现相似,但在中等难度问题上存在一定差距。对于难度较大的问题,闭源模型普遍优于开源模型。
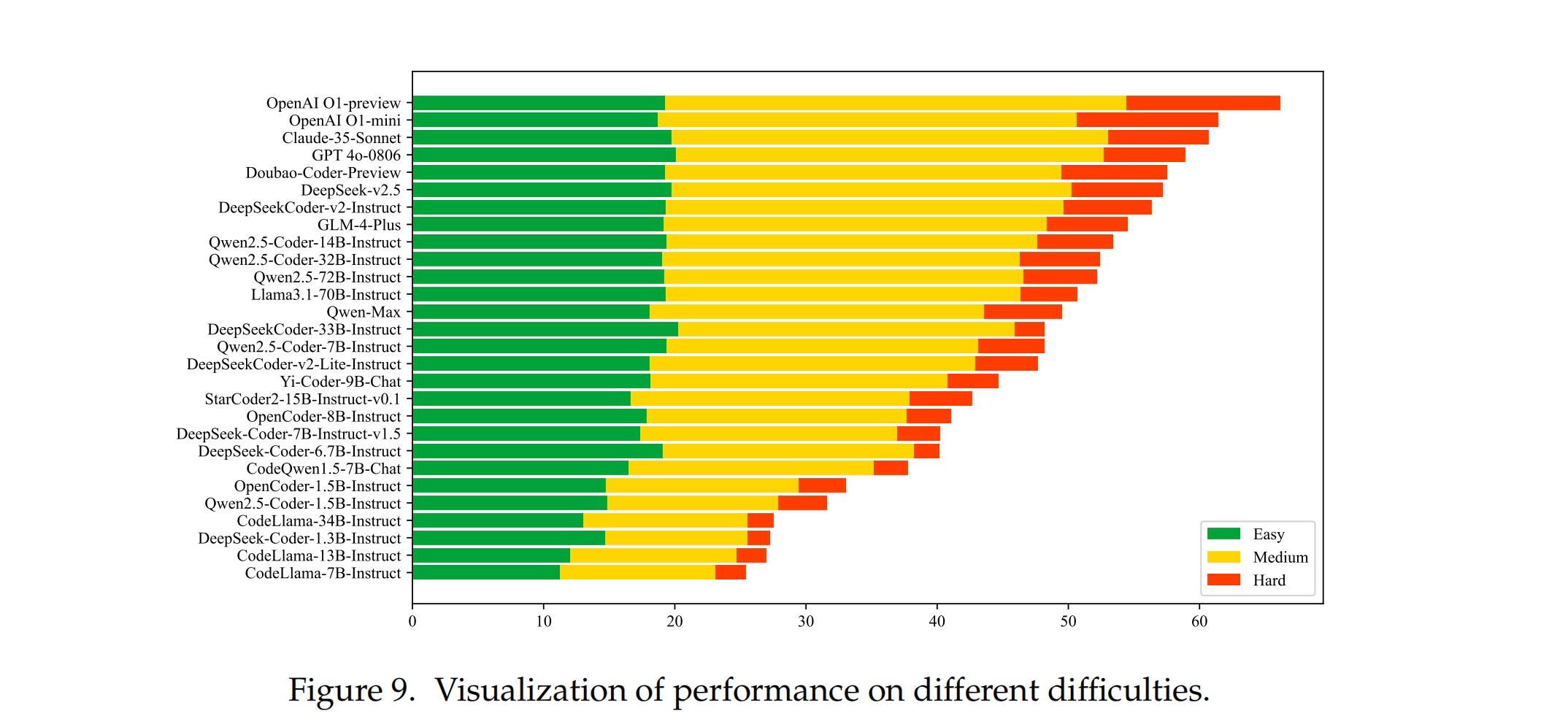
- 使用 SandboxFusion,可提升模型表现
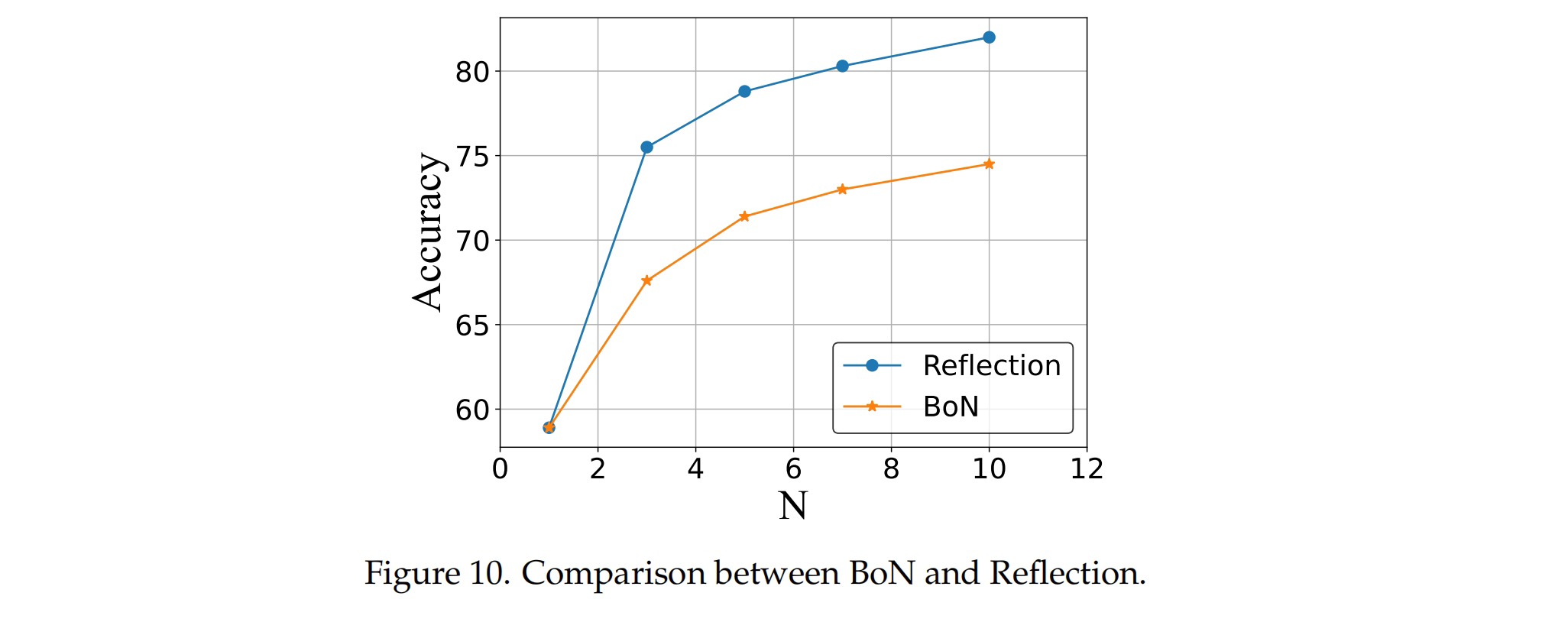
使用 SandboxFusion 进行反馈能够显著改善模型表现。研究人员对比了 “Reflection” 和 “BoN” 两种策略。在 “Reflection” 策略中,通过利用 SandboxFusion 的反馈上下文对答案进行 N 次精炼,复现了自我精炼策略 [Madaan et al., 2024]。而在 “BoN” 策略中,仅进行 N 次推断以获得结果。结果如图所示,“Reflection” 策略明显优于 “BoN”,这表明 SandboxFusion 提供的反馈上下文具有较高的有效性。
5. 写在最后
我们提出的全新代码大模型评估基准 FullStack Bench,以及沙盒执行工具 SandboxFusion,旨在为 AI 在真实编程场景中的表现潜力提供快速评估参考,从而推动代码大模型的发展。
如果你也对解决大模型领域的复杂问题感兴趣,有志于探索前沿课题,欢迎前往招聘页面,了解岗位详情。