Doubao Realtime Voice Model Is Available Upon Release! High EQ and IQ
Doubao Realtime Voice Model Is Available Upon Release! High EQ and IQ
日期
2025-01-20
分类
技术发布
The Doubao Realtime Voice Model was officially launched today, and fully available on the Doubao APP. You can try to use it by upgrading the Doubao APP to version 7.2.0.
The Doubao Realtime Voice Model is an integrated voice understanding and generation model that realizes end-to-end speech dialogues. Compared with the traditional cascading method, this approach offers an unprecedented level of speech expression and control, along with excellent emotional acceptance capabilities. Additionally, it features ultra-low delay and smooth interruption ability during dialogues.
According to real feedback from external users, they are more satisfied with the Doubao model than with GPT-4o because it has a significantly more natural voice and tone, as well as a wider range of emotional expressions. The Doubao team believes that the launch of the model marks a milestone. It not only meets the actual needs of Chinese users but also serves hundreds of millions directly upon its release, moving beyond a mere demonstration.
This article focuses on the model’s technical implementation methods, its features and advantages, and evaluation results.
Technical demo page: https://team.doubao.com/realtime_voice
Today, the Doubao APP has released a new end-to-end speech capability available to all users!
Its technical capabilities? Click on the video below for a quick check.
With end-to-end speech capabilities, Doubao is not only your great teammate for family visits and gatherings during the Spring Festival, but also a high-EQ singer who can sing the song named "Gong Xi Fa Cai" (meaning "May you have a prosperous New Year"):
It is also a skit master who engages in conversation with you, speaks in an accent that will make you laugh, and imitates the classic Chinese comedic characters, "Bai Yun and Hei Tu":
Behind these capabilities is the Doubao Realtime Voice Model.
The model is a truly end-to-end speech system, primarily designed for Chinese contexts and scenarios. While it supports English dialogues, it does not yet accommodate multilingual conversations. Relying on a joint speech-semantics model, the Doubao Realtime Voice Model showcases impressive expressive capabilities and significant potential for future development, achieving a level of speech that closely resembles human interaction. Its ability to understand and generate responses based on speech commands represents a major advancement beyond previous limitations. Upon its release, it effectively serves hundreds of millions of users, showcasing its functionality as more than just a demonstration.
In external real-world testing, users are more satisfied with the Doubao model than with GPT-4o because it has a significantly more natural voice and tone, as well as a wider range of emotional expressions.
1. Exceeding the Limits of Human-like Speech Dialogue Capabilities
Human-like speech dialogue, which offers a more intimate interactive experience and emotional connection, is one of the key goals in humanity's pursuit of AGI (Artificial General Intelligence).
In the past, traditional speech dialogue task systems typically employed a cascading approach: user speech was transcribed into text through ASR, which was then sent to LLM to generate conversational text, and finally converted into speech output using TTS.
Such systems have multiple flaws that hinder the realization of human-like speech dialogue interaction. For example, it has limited understanding of user emotions and various paralingual information in speech, upper limits on model-generated speech emotions, inability to follow voice control commands, and inability to achieve ultra-low delay, etc.
In addition to the limitations of inherent methods, the naturalness, usefulness, and security of model dialogues can sometimes undermine and conflict with one another. How can we balance promoting significant advancements in model expressiveness while ensuring that the model maintains high performance in intelligence-related tasks? This has become a major issue.
With the development of large models in recent years, model architecture innovation and Scaling philosophy are intertwined, which makes it possible to break through bottlenecks. In addition, coupled with the team's previous technical knowledge, it is possible to build an integrated speech understanding and generation model, and to truly realize end-to-end speech dialogues.
In response to the wave of technological advancement, the Doubao team aims to build a truly usable end-to-end speech system that serves hundreds of millions of users. At the same time, the team seeks to redefine future human-computer interaction by infusing AI with the "soul", thereby fostering a deeper connection between humans and computers.
To this end, the team has worked diligently in R&D to achieve a balanced model delivery experience. While ensuring security, we expect the model to possess strong understanding and logical reasoning abilities, as well as the capability to access the internet for answering time-sensitive questions. At the same time, it has an unprecedented level of speech expression and control, along with excellent emotional acceptance capabilities. Additionally, it features ultra-low delay and smooth interruption ability in real-time interaction.
In terms of implementation, the team developed an end-to-end framework that deeply integrates speech and text modalities.
The framework performs unified modeling for speech generation and understanding, ultimately achieving multimodal input and output.In the Pretrain stage, the team conducted in-depth training on interleaving data from various modalities to accurately capture and efficiently compress massive amounts of voice information. Through Scaling, the team maximized the deep integration of speech and text capabilities and the emergence of capabilities. In the post-training stage, the team utilized high-quality data and RL algorithms to further enhance the model's emotional intelligence in dialogue and security, and to find a balance between "IQ" and "EQ".
2. High IQ and EQ Enable "Human-like" AI Dialogues
As a result of previous efforts, the pre-training model offers various input and output options, such as S2S (speech to speech), S2T (speech to text), T2S (text to speech), T2T (text to text), among others.
The specific characteristics are as follows:
- Human-like Emotional Acceptance Abilities
Currently, most AIs are still functional, primarily interacting by responding to and following human commands. In fact, we desire partners like Jarvis in the movie "Iron Man", and Samantha in the movie "Her", who can deeply understand human emotions, needs and ideas, empathize with human beings, and provide warm and sincere companionship.
Therefore, we established emotional expressiveness, emotional understanding, emotional acceptance, and human-like speech expression as the key objectives in the whole research process, and carried out the following tasks at different stages:
Data Collection: We carefully screened and sorted a large dataset of speech recordings that captured a wide range of emotions across various scenarios. This process ensured we provided high-quality materials for model training.
Pre-training: We conducted in-depth training with a large amount of interleaving data of various modalities, and designed algorithms and optimization strategies to enable the model to accurately capture and learn the emotional characteristics in speech.
Post-training: We further optimized the model using realistic and high-quality synthesized speech dialogue data to enable it to achieve emotionally intelligent and empathetic dialogues.
So far, we have achieved milestones. For example, when the user is unhappy, the model will say warm words in a comforting tone, when the user is in high spirits, the model will respond positively in a happy tone, and when the user is joking, the model can receive the user's content and emotions and output appropriate expressions.
- Strong Voice Control and Rich Emotional Expression
In addition to human-like emotional expression, the team also hopes that the model possesses a variety of practical skills, including voice control, role-playing, and singing, to enhance the overall user experience.
In terms of voice control, the model can respond to basic commands as well as follow a variety of complex commands.
It has strong emotional control and expressiveness that are comparable to those of professional actors, and it can even make delicate adjustments to the timbre.
The model also possesses strong storytelling abilities by learning the voice and emotional characteristics of different roles. It can vividly switch among various roles/states in dialogue or content expression, coupled with diverse emotional expressions, making the interaction more interesting and immersive.
After joint modeling, the model has emerged with unexpected command understanding, voice acting, and voice control capabilities. For example, some dialects and accents of the current model are mainly derived from data generalization in the Pretrain stage, rather than targeted training.
- Balance Between IQ and Expressiveness
The voice intelligence of the Doubao Realtime Voice Model demonstrates in a profound understanding of various aspects of user input, such as emotional tone and intent, resulting in output that is both practical and genuine. At the same time, the output voice expressiveness of the model approaches that of human beings, including human-like paralinguistic features (such as use of modal particles, pause for thinking, etc.).
To achieve this capability, we ensure that the multimodal voice dialogue data is both correct in semantics and natural in expressiveness at the data level and in the post-training algorithms. At the same time, multiple rounds of data synthesis methods are used to produce high-quality and highly expressive speech data, achieving the balance and unity between the model's IQ and expressiveness, thereby generating natural and consistent voice expressions.
By regularly evaluating the model from various perspectives, the team uses the evaluation results to promptly adjust their training strategies and data usage methods, ensuring that the model maintains a good balance between intelligence and expressiveness.
In addition, we enable the model to connect to the internet in real-time, allowing it to dynamically obtain the latest information relevant to specific questions and provide accurate, timely responses to time-sensitive inquiries.
- Smooth Interactive Experience and Ultra-low Delay
In human-like speech dialogues, smooth interactive experience and ultra-low delay are essential. Currently, the high delay associated with cascading systems reduces the coherence of real-time dialogues, significantly impacting model performance.
Under the framework of joint modeling of speech generation, understanding and text models, we realize the accuracy and naturalness of the generative side models in the case of lower system delay. At the same time, on the understanding side, the framework enables the model to achieve keen speech interruption and user dialogue judgment.
- Safety-related Challenges and Solutions
The introduction of multimodalities presents new safety requirements for the model.
Specifically, when using speech as input, the model must ensure that the same safety guidelines are applied to all speech expressions. At the same time, when speech is used as output, new safety concerns arise. In addition, the model needs to express the appropriate content with the correct tone across different scenarios and address the security risks associated with the many-to-one relationship between speech and text.
The team is deeply concerned about the issues mentioned above. In the joint modeling process, we implemented various safety mechanisms during the post-training phase to effectively suppress and filter potential unsafe content, thereby reducing security risks.
Of course, enhancing security is not an immediate task, but a complex challenge that requires ongoing research and long-term investment in the future.
3. Evaluation Results
In the evaluation, the team selected dozens of external testers and collected over 800 data points in Chinese across 270 topic groups.
These testers were from 10 cities, including 9 males and 18 females, all aged between 21 and 33. 11.11% of the testers had never used the Doubao APP, 70.37% were light users (1-2 days per week), and the rest were more frequent users.
The team evaluates the model around multiple dimensions such as human-likeness, usefulness, emotional intelligence, call stability, and dialogue fluency. Overall satisfaction ratings show that the Doubao Realtime Voice Model scored 4.36 out of 5, while GPT-4o scored 3.18. Of the testers evaluated, 50% rated the performance of the Doubao Realtime Voice Model as 5 out of 5.
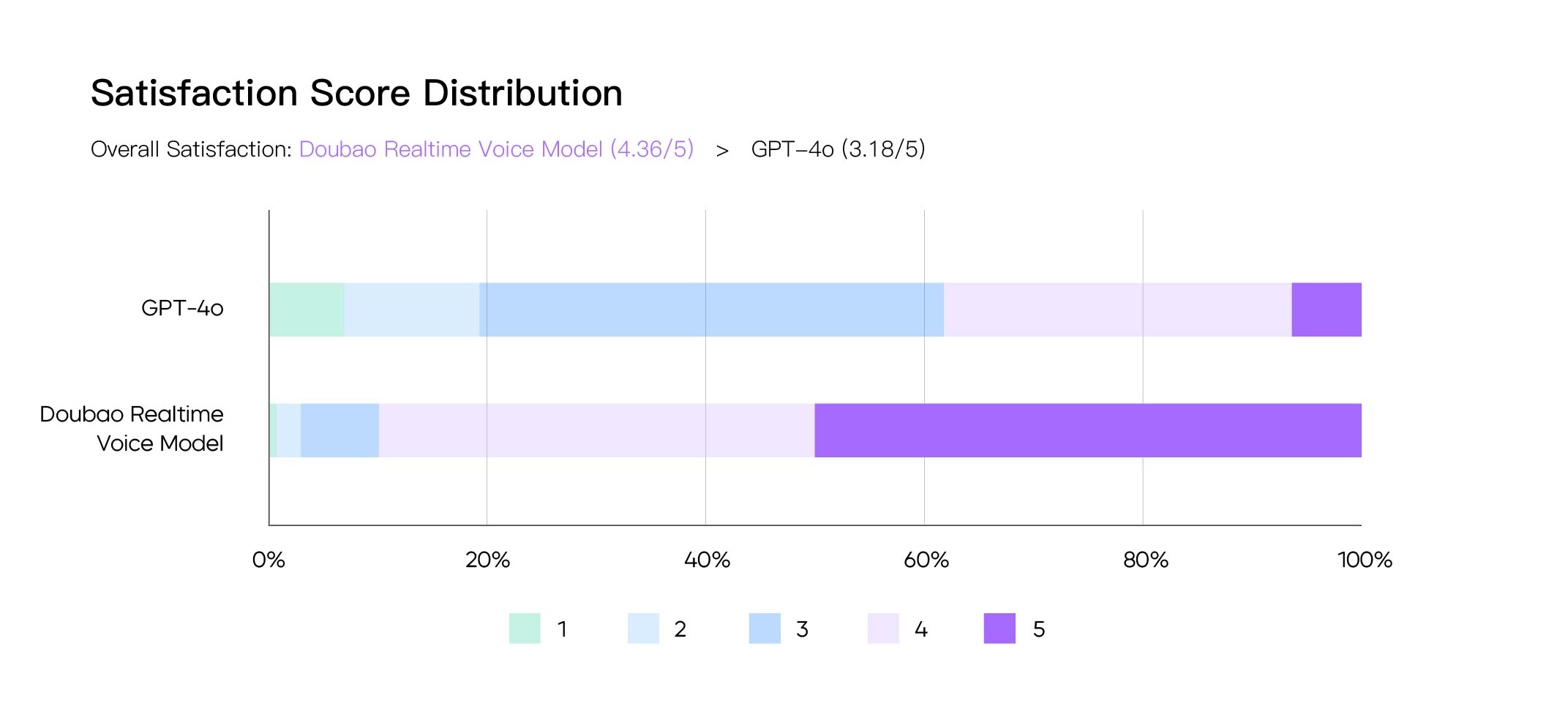
In addition, the Doubao Realtime Voice Model demonstrates significant strengths in emotional understanding and expression during the evaluation of model advantages. In particular, more than 30% of the testers in the "AI or not" evaluation said that GPT-4o was "too AI", while the corresponding proportion of the Doubao Realtime Voice Model was within 2%.
Based on the information above, the Doubao realtime voice model meets expectations in both IQ and EQ. Especially at the level of emotional intelligence, the model has also made significant progress in emotional understanding, acceptance and expression, and can accurately capture and respond to human emotional information.
4. Final Thoughts
Based on the above technological breakthroughs and their effective implementations, we believe that the Doubao Realtime Voice Model sets a new benchmark for the future application of voice multimodal technology and lays a strong foundation for future research and optimization.
At the same time, the team recognizes that while the model has initially shown promise for exploration, there are still many uncertainties regarding its limitations. For example, the model primarily supports Chinese, and the support for other languages is quite limited. In the Chinese language, the model only supports the understanding and expression of a small number of dialects and local accents, and there is still much room for improvement. In addition, security topics also require long-term investment.
In the future, we hope to further explore the potential of the model. We plan to gradually expand its capabilities by optimizing algorithms, increasing the amount of data, and improving training strategies. These efforts aim to enhance the model's adaptability and expressiveness in complex scenarios.
The mission of the Doubao (Seed) Large Model Speech Team is to enrich interaction and creation methods with multi-modal speech technology. If you are also interested in relevant work, please visit the Doubao (Seed) Large Model Speech Team webpage to learn more about the team.