Seed Research | 全新超稀疏架构,推理成本较 MoE 最高可降 83%!
Seed Research | 全新超稀疏架构,推理成本较 MoE 最高可降 83%!
日期
2025-02-12
分类
Seed Research

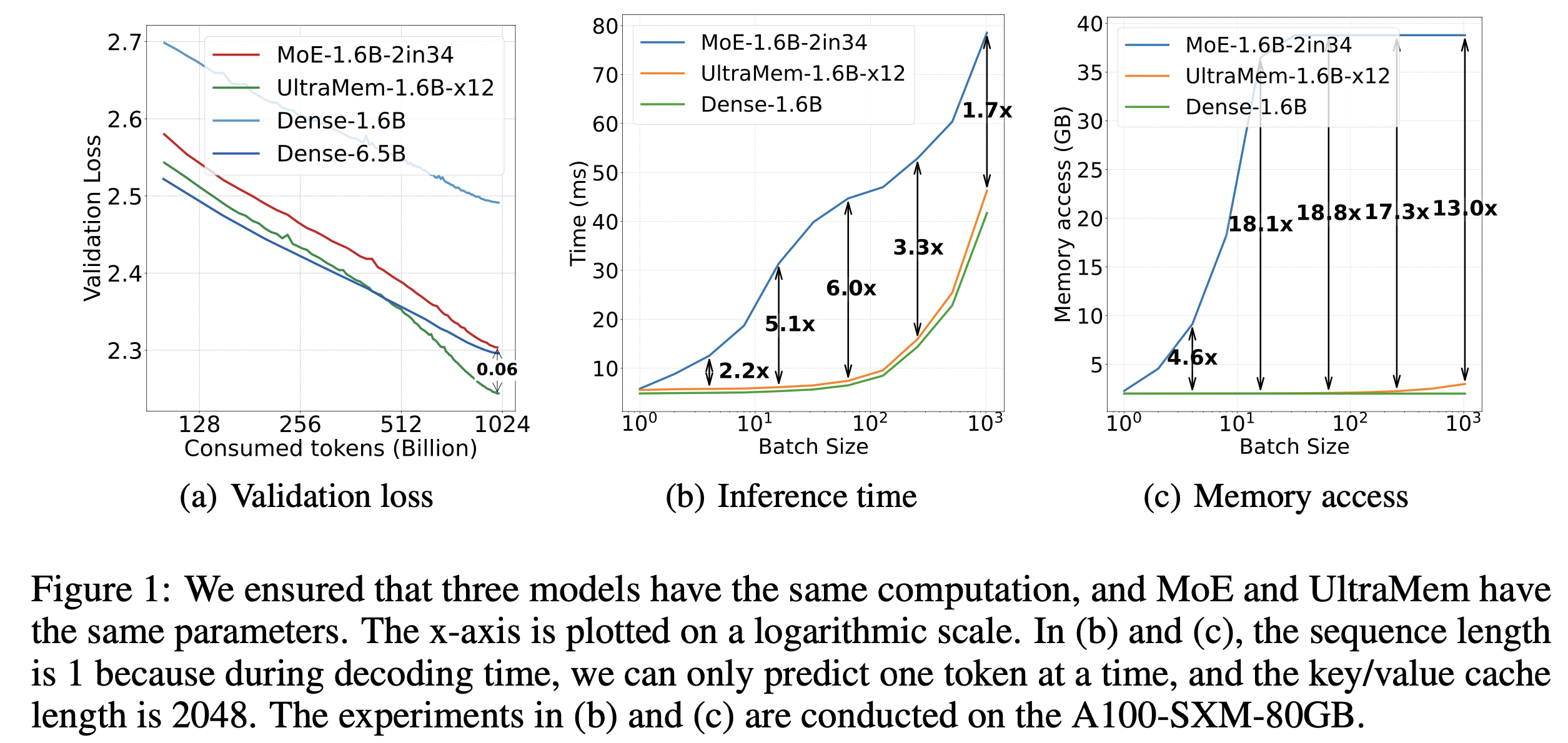
随着模型规模的扩大,推理成本和访存效率已成为限制大模型规模应用的关键瓶颈。近期,字节跳动豆包大模型团队提出了全新的稀疏模型架构 UltraMem,该架构有效解决了 MoE 推理时高额的访存问题,推理速度较 MoE 架构提升 2-6 倍,推理成本最高可降低 83%。该研究还揭示了新架构的 Scaling Law,证明其不仅具备优异的 Scaling 特性,更在性能上超越了 MoE。
实验结果表明,训练规模达 2000 万 value 的 UltraMem 模型,在同等计算资源下,可同时实现业界领先的推理速度和模型性能,为构建数十亿规模 value 或 expert 开辟了新路径。
在 Transformer 架构下,模型的性能与其参数数量和计算复杂度呈对数关系。随着 LLM 规模不断增大,推理成本会急剧增加,速度变慢。
尽管 MoE 架构已经成功将计算和参数解耦,但在推理时,较小的 batch size 就会激活全部专家,导致访存急剧上升,进而使推理延迟大幅增加。
为此,字节跳动豆包大模型 Foundation 团队提出 UltraMem,一种同样将计算和参数解耦的稀疏模型架构,在保证模型效果的前提下解决了推理的访存问题。
实验结果表明,在参数和激活条件相同的情况下,UltraMem 在模型效果上超越了 MoE,并将推理速度提升了 2-6 倍。此外,在常见 batch size 规模下,UltraMem 的访存成本几乎与同计算量的 Dense 模型相当。
目前,该论文已被 ICLR 2025 接收。
Ultra-Sparse Memory Network
1. MoE 与 PKM 的局限性
LLM 的能力增长需要指数级增长的计算资源,这在实时应用等资源有限的环境中颇具挑战。为了解决计算问题,先前的研究者提出了 MoE 和 Product Key Memory(PKM)方案,但它们都有各自的局限性。
MoE 通过稀疏激活 expert 解耦了计算和参数,但在推理场景中,速度其实很慢。原因在于,模型在推理时只能一个字一个字的生成,因此 batch size 和 sequence length 都很小,在这个场景下,MoE 的所有专家通常会被全部访问到,极其容易遇到访存瓶颈,导致推理延迟激增。
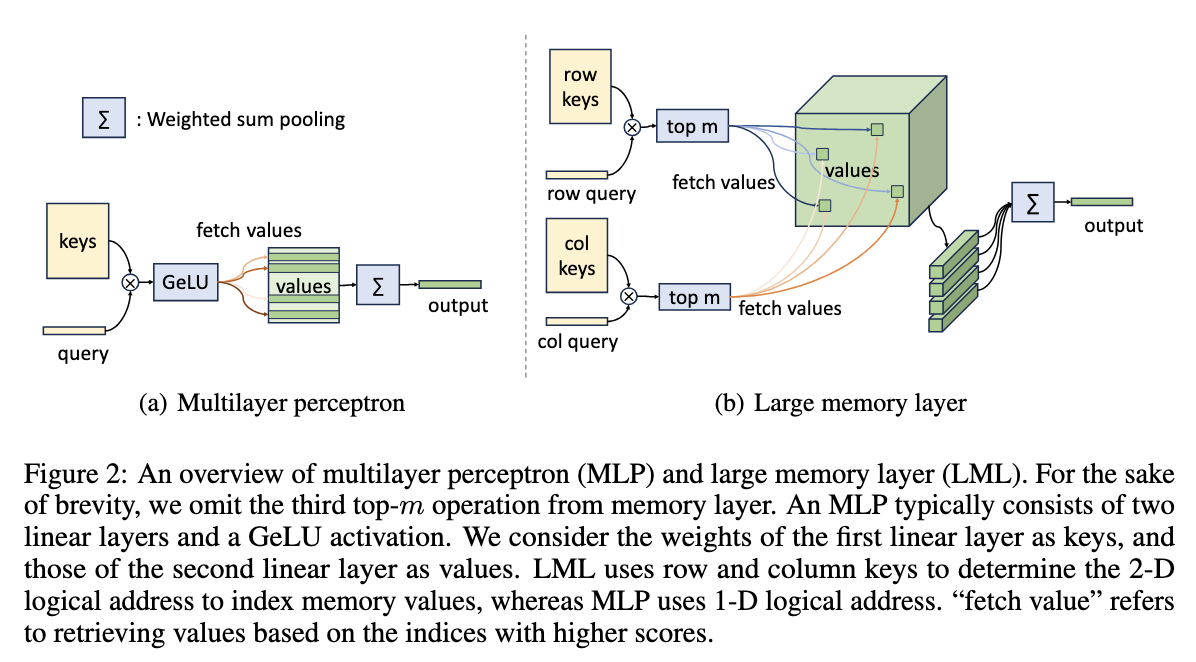
PKM 最早提出 large memory layer,其中包含了数量庞大的稀疏参数 value,这里 value 其实就是一个向量,每个 token 会根据一个「行路由」和一个「列路由」定位到得分最高的几个 value,激活这些 value 后做 weighted sum pooling 作为 memory layer 的输出。这种方法因为每个 token 在推理时仅仅只激活极少数的 value,所以推理时不会遇到访存瓶颈,但其效果很差,且 scaling 能力差。
2. UltraMem 兼顾访存和效果
UltraMem 参考了 PKM 的设计,但针对 PKM 的 3 个缺陷予以补充,以实现更高效的访存、更优质的 value 检索,同时,降低了显存和部署成本。
① 优化模型结构
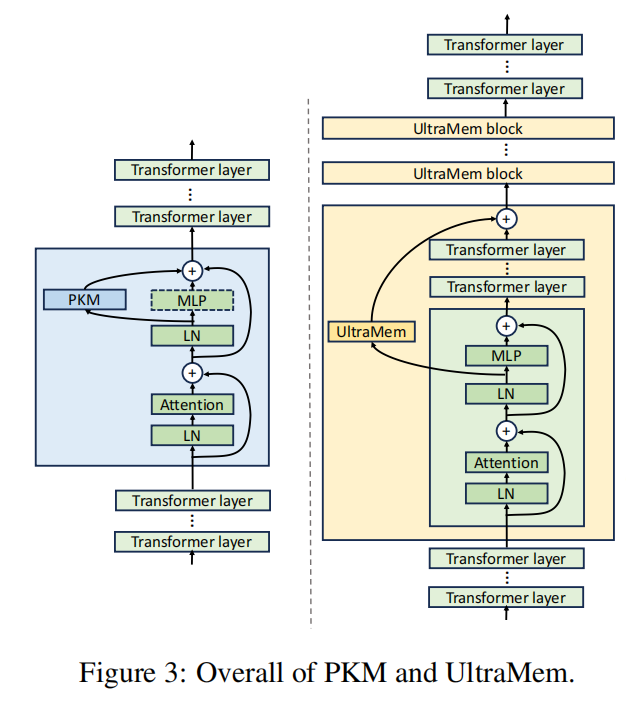
PKM 的设计中,memory layer 只有 1 层,插在整个 Transformer 的中间层,这对大规模训练并不友好,并且如此庞大的稀疏参数应该尽可能多的参与到每次的残差连接中。
因此,研究团队拆分出多个小 memory layer,以固定的间隔分布在 transformer layer 中;并且增加了 skip-layer 的操作,即当前层的 memory layer 的输出会加到后面某层 transformer layer 的输出。这使得模型可以并行地执行 memory layer 的访存操作和 transformer layer 的计算。
② 优化 value 检索方式
在检索时,只有 score 最高的 m 个 value 会被激活,PKM 的 score 是通过「行 score」+「列 score」得到的。团队进一步探索了一种更复杂的乘法方法 Tucker Decomposed Query-Key Retrieval(TDQKR)。这一方法受启发于 Tucker Decomposition。具体来看,给定 values,shape 为(n,n,h),其中 h 为 hidden size,那么 values 的 score S_grid 可以做如下分解:
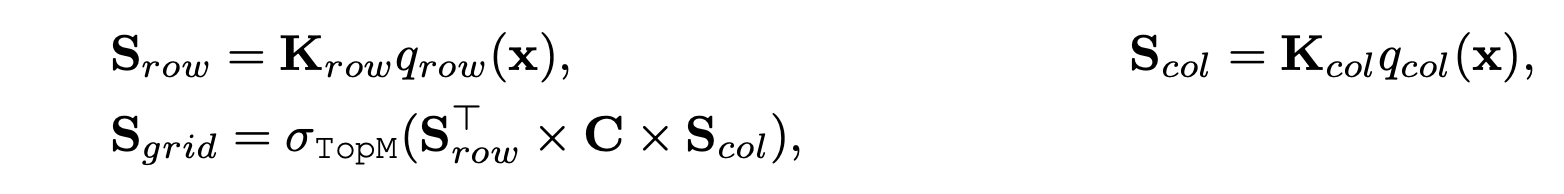
其中 Srow,Scol∈Rr×n\mathbf{S}_{row}, \mathbf{S}_{col} \in \mathbb{R}^{r\times n}Srow,Scol∈Rr×n, C∈Rr×rC\in \mathbb{R}^{r\times r}C∈Rr×r 是可学习的 tucker core。这个结构下,每个 value 的 score 由 r 个行 score 和 r 个列 score 的组合乘加 获得,具备更高的复杂度。
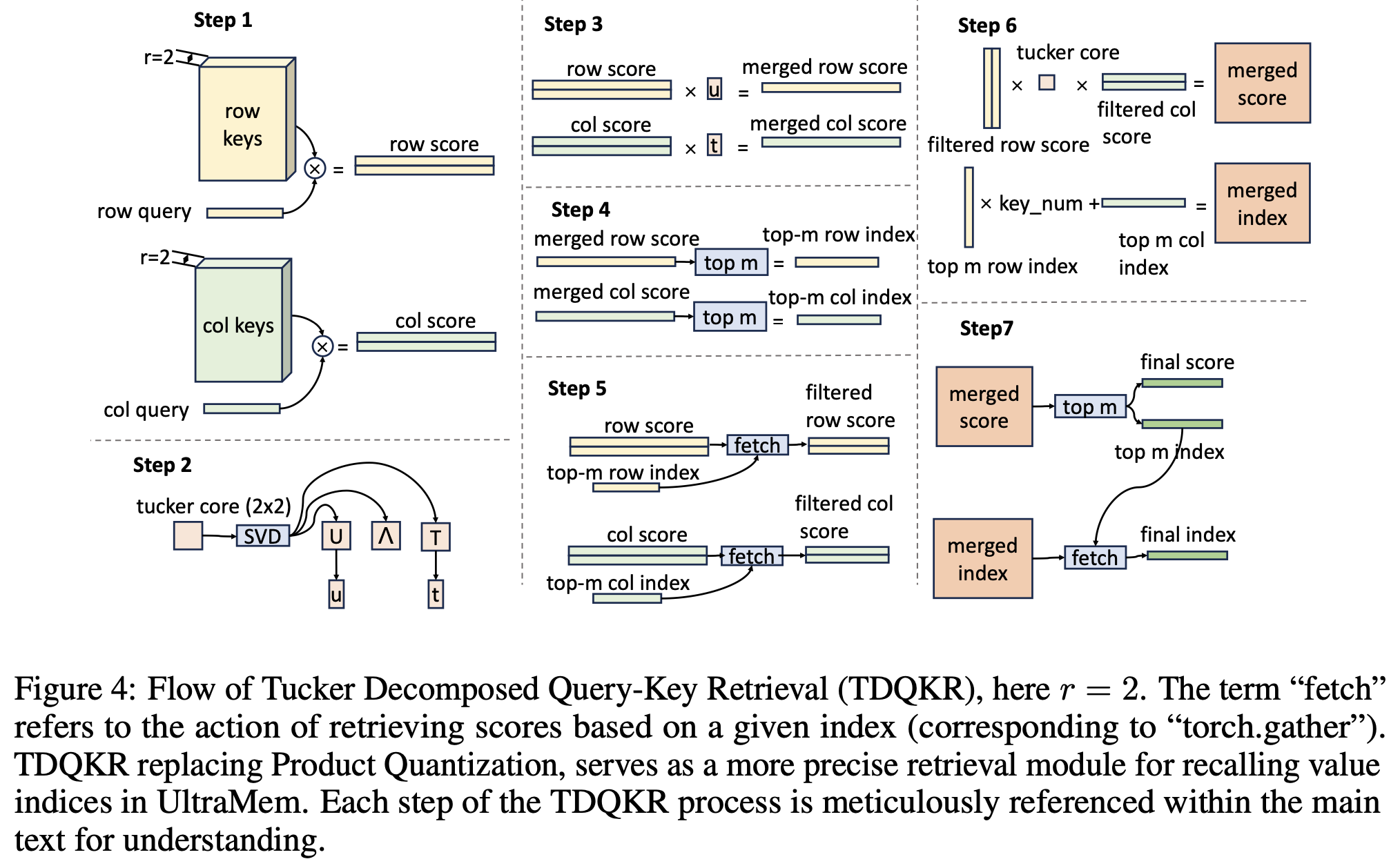
③ 隐式扩展稀疏参数
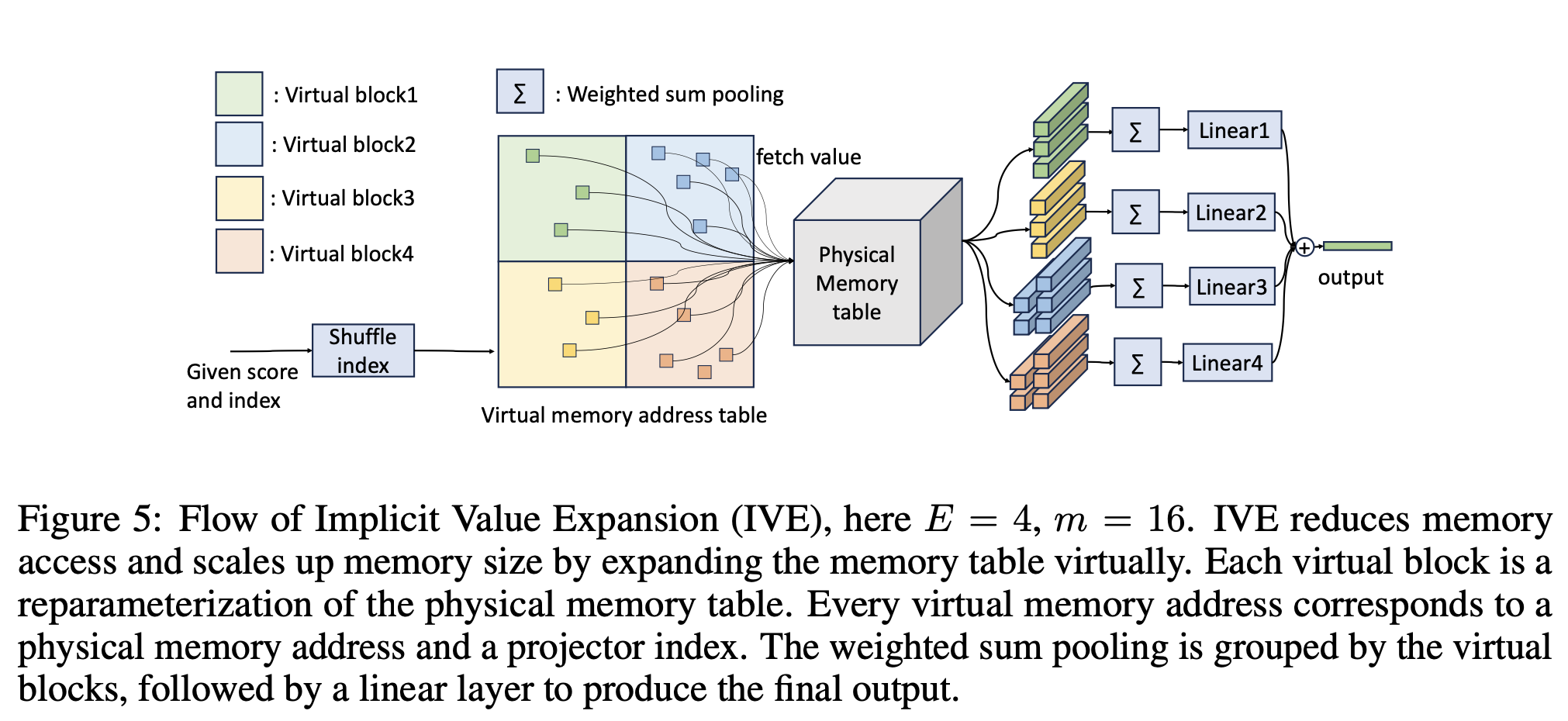
更多的稀疏参数通常会带来更好的效果,但过多的参数又会给显存和部署带来麻烦。为此,研究团队提出了 Implicit Value Expansion (IVE)方法隐式地扩展稀疏参数,并引入了 virtual memory 和 physical memory 的概念。
以 4 倍扩展为例(如下图所示),virtual memory 的数量是 physical memory 的 4 倍,给定多对(score,index)后,首先按照 virtual memory address table 做查表,4 个 virtual block 会查询同一个 physical memory table,之后各自做 weighted sum pooling,并经过不同的线性层,最后再求和输出。
由于最后的 Linear 和取 value 之间没有任何非线性操作,因此每个 Linear 都可以和 physical memory table 做融合,生成一个全新的 memory table,这个例子下,实际上隐式扩展了 4 倍的 value 数量。
3. 实验结果:推理速度较 MoE 最高提升 6 倍
① 模型性能评估
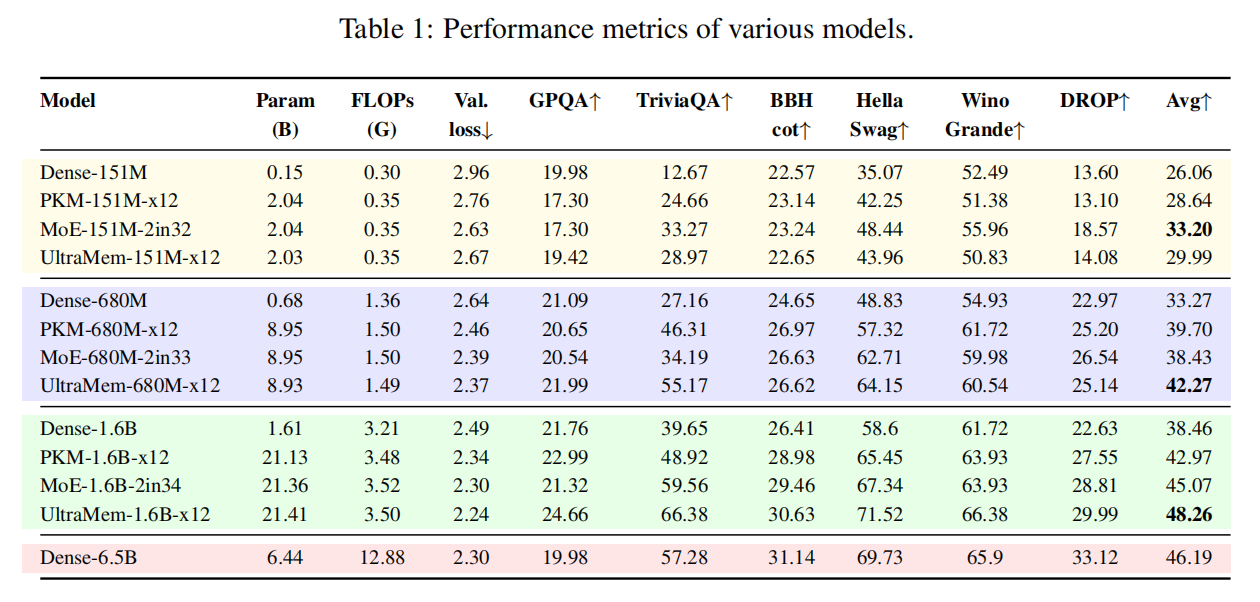
研究团队在 151M、680M、1.6B 三个尺寸的激活参数上做了广泛实验,其中 MoE、PKM 和 UltraMem 的总稀疏参数保持在激活参数的 12 倍。
如下表所示,可以发现 UltraMem 在 680M、1.6B 上具有显著的效果优势。
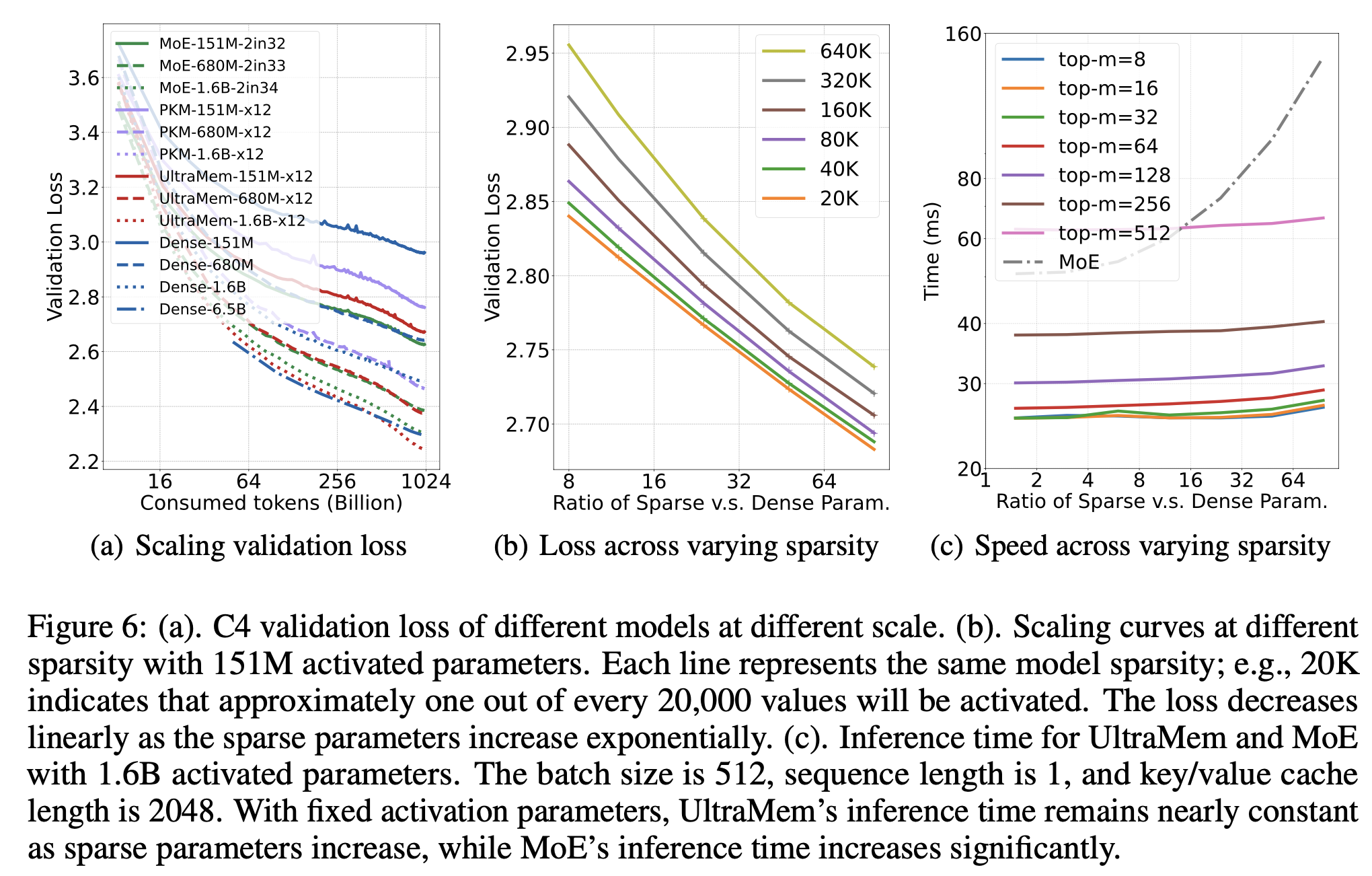
随着稀疏参数的增加,UltraMem 的效果和推理速度如何变化?
下图(b)展示了 UltraMem 的效果变化,横轴为稀疏参数和稠密参数的比值,每个颜色的线代表了一种稀疏度。稀疏度定义为 value 的数量 / 每个 token 激活的 value 数量。观察发现,持续增加稀疏参数和 loss 的下降呈对数关系;且稀疏度越小,模型效果越好;但是稀疏度持续降低带来的收益在逐渐饱和。
下图(c)展示了 UltraMem 的推理时间变化,横轴为稀疏参数和稠密参数的比值。观察发现,UltraMem 在持续增加稀疏参数时推理时间几乎不变,反观 MoE 有显著增长的趋势。
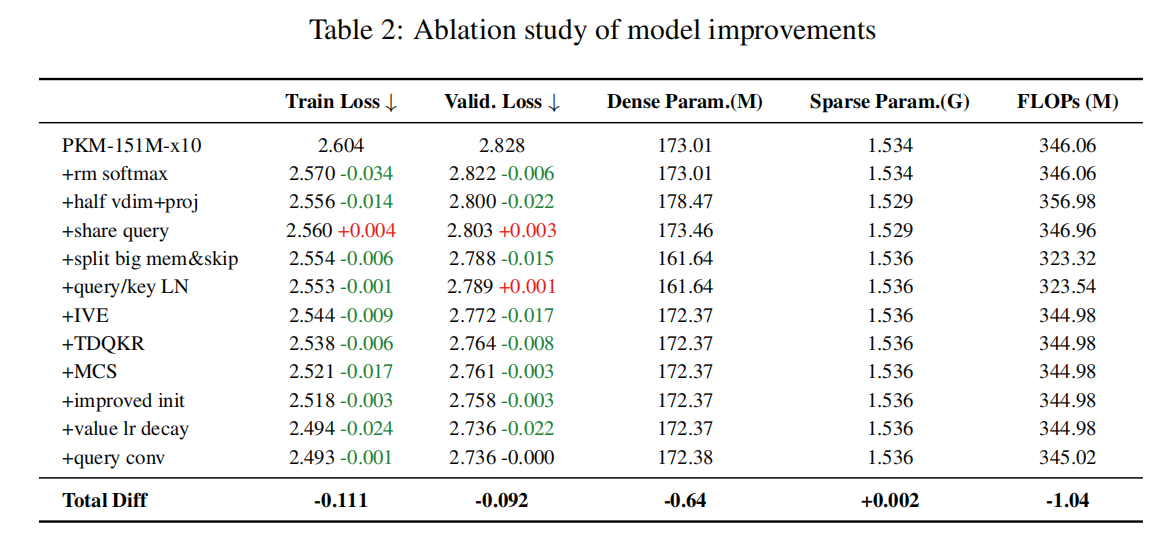
② 消融实验
研究团队在 151M 激活、1.5B 总参数的稀疏模型上进行了全面的消融实验。从最原始的 PKM 开始,逐渐增加一些 trick 和上文提出的结构改进,最终能拿到 C4 validation loss -0.092 的显著收益,同时稀疏参数和计算量几乎不变。
综上所述,研究团队提出的 UltraMem 具有极小的访存,因此,相比 MoE 实现了最高达 6 倍的速度提升,推理成本最高可降低 83%。同时,在性能方面,随着模型容量的增加,在相同的参数和计算量情况下,UltraMem 超过了 MoE,表明其具有更强的扩展能力。这项工作为开发更高效和可扩展的语言模型提供了一个有希望的方向。
4. 写在最后
UltraMem 能有效地应用于对延迟要求较高的推理场景(例如代码补全),避免了类似 MoE 的访存瓶颈。即使在通用场景下,UltraMem 相较于 MoE 都展现出了显著的速度优势,除非 batch size 上万的极端场景。
当前,针对 UltraMem 的技术演进仍存在若干值得探索的方向,包括但不限于:如何高效优化稀疏参数、如何提升稀疏模型推理能力、如何更优地激活稀疏参数等。这些技术方向或将成为后续研究的重要切入点。
豆包大模型团队一直以探索智能的无尽边界、解锁通用智能的无限可能为目标。