Seedream 3.0 文生图模型技术报告发布
Seedream 3.0 文生图模型技术报告发布
日期
2025-04-16
分类
技术发布
字节跳动 Seed 团队正式发布 Seedream 3.0 技术报告。Seedream 3.0 是一个原生高分辨率、支持中英双语的图像生成基础模型,对比 Seedream 2.0,这一版本的整体性能表现有较大提升,尤其在分辨率、生图结构准确性、数量准确性、多物体属性关系、小字生成与排版、美感效果、真实度等方面有所突破。
具体亮点如下:
原生 2K 直出,适配多比例场景: 无需后处理可直接输出 2K 分辨率图像,从手机端到巨幅海报场景的视觉需求均可满足;
3 秒出图,大幅提升创作效率: 面向海报设计、视觉创意等需求,可实现 3 秒左右快速生成高品质图像,实现“所想即所得”的实时创意交互;
小字更准,文本排版效果增强: 优化小字体高保真生成、多行文本语义排版等业界难题,让 AI 具备商业级图文设计能力;
美感&结构提升,生成富有感染力: 指令遵循进一步增强,人体和物体结构崩坏改善,且进一步弱化了出图的 AI 感,实现从“看得清”到“有感染力”的审美提升。
Seedream 3.0 的研发始于 2024 年末,通过调研设计师等群体的实际需求,Seedream 团队不仅将图文匹配、结构、美感等行业共识性指标纳入攻坚方向,同时,也将挑战小字生成与复杂文本排版、2K 高清直出、快速图片生成等业界难题作为核心目标。
2025 年 4 月,Seedream 3.0 正式上线,目前已在豆包、即梦等平台全量开放。
面向结构、美感、人像、文字可用性、用户偏好(Elo)等维度的主客观评测结果显示,Seedream 3.0 相比 2.0 版本综合性能显著提升,尤其在长文本渲染、真实人像生成方面表现出色。

Seedream 3.0 在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整
在权威竞技场 Artificial Analysis 上,Seedream 3.0 与 GPT-4o、Imagen 3、Midjourney v6.1、FLUX 1.1 Pro、Ideogram 3.0 等文生图模型同台竞技,在近期打榜中,一度排名第一。
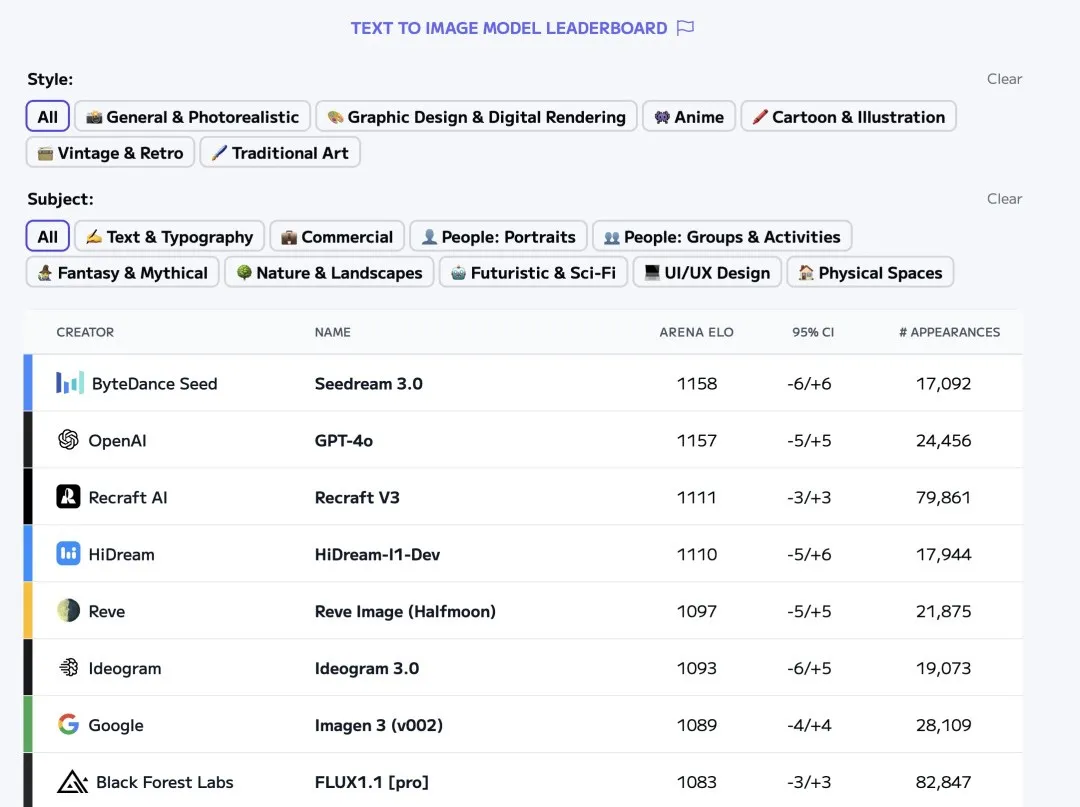
Artificial Analysis 排名(截止 4 月 15 日下午)
值得一提的是,Seedream 3.0 在海报设计与创意生成方面较为突出,贴合了设计师群体的日常工作需求。

本文将从数据采集与处理、预训练、后训练、推理加速等方面,介绍 Seedream 3.0 的技术实现方法。
1. 数据优化:缺陷感知扩充数据集,并改进数据分布
对生成式 AI,大规模的高质量训练数据必不可少。Seedream 3.0 从以下三个方面优化了数据采集和预处理流程:
- 图像缺陷感知的训练策略,大幅提升可用数据量
Seedream 2.0 中为了保证训练数据的质量,采用了相对来说比较保守的数据筛选策略,去除了大量具有微小缺陷(水印、字幕、马赛克等)的图像。在 Seedream 3.0 中,团队采用了全新的缺陷感知训练策略,通过自研检测器精准定位缺陷位置和面积,将缺陷较小的图像保留,并在训练时通过隐空间掩码来避免图像缺陷对损失函数的影响。这样的设计使得有效数据集扩充超过 20%,且依旧保障了模型的稳定训练。
- 视觉语义协同的采样策略,有效平衡数据分布
传统的文生图数据集的构建方法通常面临数据分布不均衡的挑战。为了解决这个问题,团队提出了视觉语义二维协同的采样策略:在视觉方面,采用层次化聚类方法来保证不同视觉形态的平衡;在语义方面,采用 TF-IDF (词频-逆文档频率) 技术有效解决文本描述的长尾分布,通过在视觉和语义两个方面的协同优化,大幅提升了视觉模式语义概念的均衡性。
- 研发图文检索系统,进一步改进数据分布
Seedream 3.0 团队研发了一套图文检索系统,该系统在公开的评测集上取得相对领先的性能。基于这个图文检索系统,团队对现有数据集进行了过滤和分布的校准,进一步提升了训练数据的质量,为文生图大模型的训练打下了基础。
2. 预训练:聚焦多分辨率生成和语义对齐
在预训练阶段,团队针对多语言语义理解、更加精准的文字渲染、多分辨率高质量图像直出等目标,对模型架构和训练策略做了多个方面的改进:
- 跨模态旋转位置编码,进一步加强文字渲染能力
为了进一步加强图文匹配能力,团队将上个版本提出的 Scaling RoPE 扩展成了跨模态的旋转位置编码(Cross-modality RoPE)。传统的方法中大多对图像特征采用 2D RoPE 方案,而对文本特征采用 1D RoPE 的方案,不利于两种模态特征的对齐。在 Cross-modality RoPE 中,团队将文本特征视为一个形状为 [1, L] 的二维特征,并在上面施加 2D RoPE。同时,文本的 2D RoPE 的起始列 ID 从图像 2D RoPE 的结束列 ID 后开始计算。这样的设计方式可以更好地建模不同模态间特征的相互关系和每个模态内特征的相对位置,是 Seedream 3.0 模型能够实现更强文字渲染能力的关键因素之一。
- 多分辨率混合训练,让2K图像直出成为可能
上个版本模型采用了额外的 Refiner 来生成高分辨率的图像,增加了额外的推理开销。在 Seedream 3.0 中,团队借助了 Transformers 架构对变长输入序列的灵活处理能力,采用了多分辨率混合训练的策略。预训练的第一阶段,团队在平均分辨率为 256×256 的低分辨率图像上进行训练;在第二阶段,团队将平均分辨率为 512×512 到 2048×2048 的不同分辨率和长宽比的图像进行混合训练。为了提升训练效率,团队还设计了负载均衡策略保证不同 GPU 上的序列长度大致相等。最终训练的模型能够实现多种分辨率的图像生成,在不经过额外 Refiner 的情况下实现2K图像直出。
- 流匹配和特征对齐损失函数,高效建模数据分布
不同于 Seedream 2.0 中采用了去噪扩散模型的分数匹配(Score Matching)损失函数,Seedream 3.0 采用了流匹配(Flow Matching)的损失函数来实现条件速度场的预测。为了更好适配多分辨率混合训练的信噪比变化,团队根据不同训练阶段的平均分辨率大小来动态调整流匹配训练过程中的时间步的分布。除此之外,团队还采用了特征对齐损失函数(REPA)辅助模型在预训练阶段更快地收敛,这也是特征对齐损失函数在工业级大规模文生图模型上的一次有效验证。
3. 后训练RLHF:进一步提升美感并拓展模型上限
在后训练阶段,团队在 CT 和 SFT 阶段设计了多版本的美感描述,并在 RLHF 阶段通过扩展奖励模型规模,使其具备多维度质量判别能力,进而全方位提升生成模型性能。
- 多粒度美感描述
Seedream 3.0 针对 CT 和 SFT 阶段的数据专门训练了多个版本的 Caption 模型。这些 Caption 模型在审美、风格、排版等专业领域提供了精准的描述。这确保了模型能够更有效地响应各种提示,这些多粒度的 Caption 不仅提升了模型的可控性,也有助于协同PE提升模型整体性能。
- 奖励模型拓展
不同于 Seedream 2.0 采用 CLIP 作为奖励模型,Seedream 3.0 进一步优化了奖励模型,并提升了其参数量。Seedream 3.0 采用视觉语言模型(VLM)作为奖励模型,团队借鉴 LLM 中生成式 RM 的经验进行奖励建模,这样更易于通过 LLM 原本的 Scaling 能力提升奖励准确性与鲁棒性;同时,团队将奖励模型的参数量从 0.8B 拓展至 20B 以上,并发现一定的奖励模型 Scaling 规律。
4. 高效推理:1K 分辨率生图端到端仅需 3 秒
Seedream 3.0 采用多种策略实现了推理加速。除了对模型进行量化之外,对于扩散模型的一个重要加速维度就是推理时采样步数的蒸馏。Seedream 3.0 采用了自研推理加速算法,具体来说包括以下几个关键点:
- 一致性噪声预测,提升采样过程的平稳性
传统的扩散模型在采样过程中每个时间步的噪声预测值的变化很大,这种采样过程的不稳定是其需要大量采样步数的原因之一。为了解决这个问题,团队提出了让网络来预测全局噪声期望,这在整个采 样过程中具有很强的一致性,从而能够有效压缩总采样步数。
- 重要时间步采样,加速模型蒸馏训练过程
为了提升模型蒸馏的效率,团队提出了重要时间步采样技术。该技术训练了一个网络来针对每个样本预测重要的采样时间步的分布,并基于这个分布得到最优的时间步进行模型蒸馏。结合重要时间步采样技术,团队能够在 64 GPU days 之内完成对模型的蒸馏训练过程。
利用上述技术,团队实现了对模型的无损加速,能够在保持图文匹配、美学质量、结构准确度等指标几乎不受影响的情况下实现高效生图,1K 分辨率生图端到端耗时仅需 3 秒。
写在最后
Seedream 3.0 模型发布后,在海报创作、生成效率、结构与美感等方面的提升获得了一定认可。
未来,Seedream 团队期望尝试在以下方向进一步研究和探索:探索更高效的结构设计:构建效果更好、成本更低、生成更快的文生图模型;提升模型智能化水平:拓展模型对世界知识的理解,赋予模型交织生成等能力;探索数据、模型量级、奖励模型等维度 Scaling 现象,并将认知积累应用于下一代模型中。
后续,团队还将持续分享技术经验,与业界共同推动视觉生成领域的发展。