Uncover the Story behind Depth Anything - Selected by Apple CoreML Model Library and Boasts 8K Star on Github
Uncover the Story behind Depth Anything - Selected by Apple CoreML Model Library and Boasts 8K Star on Github
日期
2024-07-10
分类
技术发布
Depth Anything V2, developed by ByteDance's Large Language Model team, has been included into Apple's Core ML model library. This article introduces the research and development process, technical challenges and solutions behind Depth Anything, and shares the team's thoughts on Scaling Laws in single visual tasks. It is worth noting that the first author of Depth Anything V1 and V2 is an intern for the team.
The Depth Anything V2 model developed by ByteDance's Doubao team was recently selected into Apple's Core ML model library and is now available on the Apple Developer site.
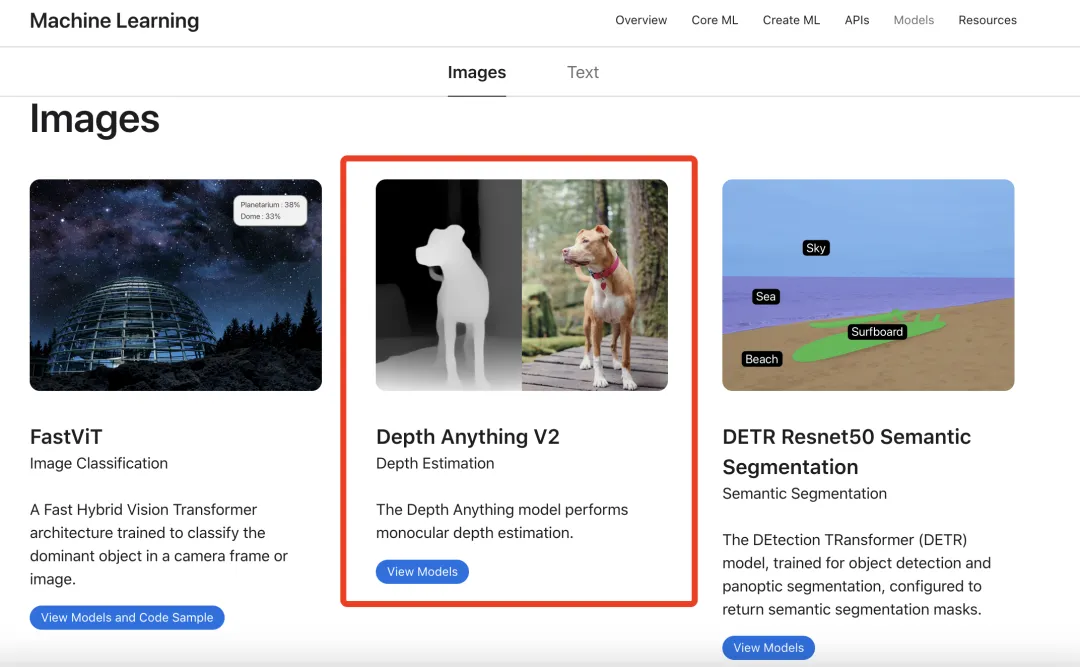
Depth Anything is a monocular depth estimation model, with its V1 version released in early 2024 and V2 version in June 2024. It includes different-sized models with parameters ranging from 25M to 1.3B. It can be applied in fields such as video special effects, autonomous driving, 3D modeling, augmented reality, security monitoring, and spatial computing.

Compared with the previous version, the V2 version is more refined in detail processing, more robust, and is significantly faster compared with the diffusion-based SOTA model.
This series of models has received a total of 8.7k stars on Github, of which 2.3k is gained shortly after the release of Depth Anything V2 and 6.4k can be attributed to Depth Anything V1. It is worth noting that the first author of the papers of the two versions is an intern of the team.
Click on the video below to learn more about model performance:
The Depth Anything V2 selected by Apple is the Core ML version. As the company's machine learning framework, Core ML aims to integrate machine learning models into iOS, MacOS and other devices for efficient operation. It can perform complex AI tasks without an internet connection, thereby enhancing user privacy and reducing latency.
Depth Anything V2, the Core ML version, utilizes a minimal 25M model that has been optimized by HuggingFace. It achieved an inference speed of 31.1 milliseconds on the iPhone 12 Pro Max. Models selected alongside it include FastViT, ResNet50, and YOLOv3, covering multiple fields from natural language processing to image recognition.
More about the papers and model performance:
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Link to the paper: https://arxiv.org/abs/2401.10891
Model performance: https://depth-anything.github.io/
Depth Anything V2
Link to the paper: https://arxiv.org/abs/2406.09414
Model performance: https://depth-anything-v2.github.io/
1. Leverage Scaling Laws for Single Visual Tasks
Over the past two years, the popularity of LLM models has led to a greater appreciation for Scaling Laws. As some research teams focus on creating a single model capable of performing multiple visual tasks, such as object detection and image segmentation, the Depth Anything team has taken a different approach.
Utilize the principles of Scaling Laws to create a straightforward yet robust foundational model that can enhance performance on a singular task.
The team explained why they selected a different path. They also considered the possibility of creating a comprehensive model that could address various tasks. However, the projected outcome would only yield a score of 70-80 out of 100, and the expenses in terms of time and computing resources would be substantial.
The team believes that Scaling Laws offer a more feasible approach to fundamental issues.
Why depth estimation then? The team members explain that computer vision tasks can be classified into two types: those that require human input to be meaningful, such as text description and image classification, and those that are objective enough to not require manual evaluation, such as edge detection and motion detection. Depth estimation falls into the latter category and is considered a more fundamental task with a wider range of practical applications compared to other tasks.
Depth estimation is a crucial aspect of computer vision, involving the inference of distance information for objects within an image. This task has numerous applications, such as autonomous driving, 3D modeling, and augmented reality.
Furthermore, the depth estimation model can serve as middleware and seamlessly integrate with video platforms or editing software, facilitating the creation of special effects and video editing. Presently, several downstream business users have incorporated Depth Anything V2 into their products.
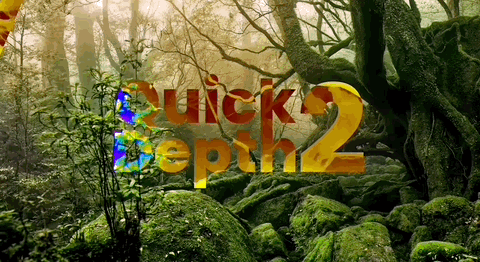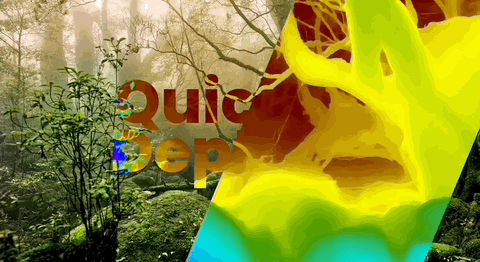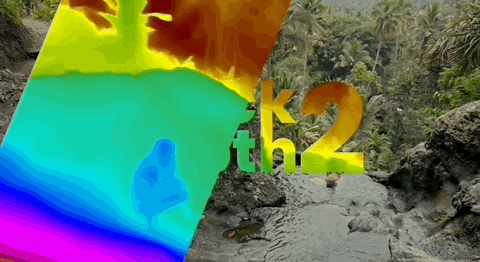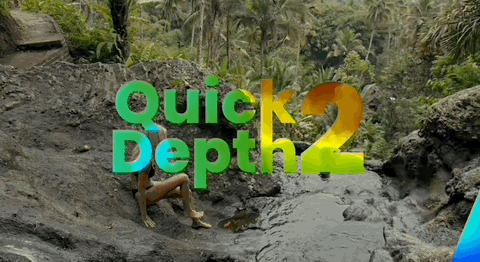
Note: The effect of integrating Depth Anything V2 into downstream user Quick Depth's product.
2. Depth Anything V1 Training Process
From its inception to the release of the V2 version and its selection by Apple for integration into Core ML, the development of Depth Anything spanned approximately one year. According to team members, the process presented two main challenges:
How to train the model to achieve and surpass existing results;
How to make the model perform better in terms of details;
These two issues, respectively, led to the development of Depth Anything's V1 and V2 versions. Let's start by discussing the model training.
In fact, before the emergence of Depth Anything, MiDaS had already been able to solve depth estimation problems quite well.
MiDaS is a robust monocular depth estimation model. The related paper was first submitted to ArXiv in 2019 and was quickly selected by the top international journal in the field of computer vision and artificial intelligence, TPAMI. However, the model itself was open-sourced, but the training method was not.
To implement the training process, the team made the following efforts.
I. Specifically Designed a Data Engine to Collect and Automatically Label Large Amounts of Data
These efforts significantly expanded the data coverage and reduced the generalization error. The introduction of data augmentation tools enabled the model to actively seek additional visual knowledge and achieve robust representation capabilities.
It is worth mentioning that initially, the model's self-training pipeline did not see significant improvements. The team speculated that this might be because the labeled dataset already contained a substantial number of images, preventing the model from gaining much knowledge from the unlabeled data.
Therefore, they shifted to a more challenging optimization target for the student model: during training, they introduced strong perturbations (color distortion and spatial distortion) to the unlabeled images, forcing the student model to actively seek additional visual knowledge.
II. Leveraging a Pre-trained Encoder to Enable the Model to Inherit Rich Semantic Priors
Theoretically, high-dimensional semantic information is beneficial for depth estimation models, and auxiliary supervision signals from other tasks can counteract pseudo-depth labels. Initially, the team attempted to assign semantic labels to unlabeled images using a combination of RAM, GroundingDINO, and HQ-SAM models, but the results were not satisfactory. The team speculated that this was due to the loss of considerable semantic information during the process of decoding images into a discrete class space.
After some experimentation, the team turned to knowledge distillation based on pre-trained encoders, enabling the model to inherit rich semantic priors, thereby addressing the issue of limited data annotation.
The training pipeline is shown in the diagram below, where solid lines represent the labeled image stream and dashed lines represent the unlabeled image stream. "S" indicates the introduction of strong perturbations. Additionally, to ensure the model possesses rich prior semantic knowledge, the team enforced auxiliary constraints between the frozen encoder and the online student model to retain semantic capabilities.
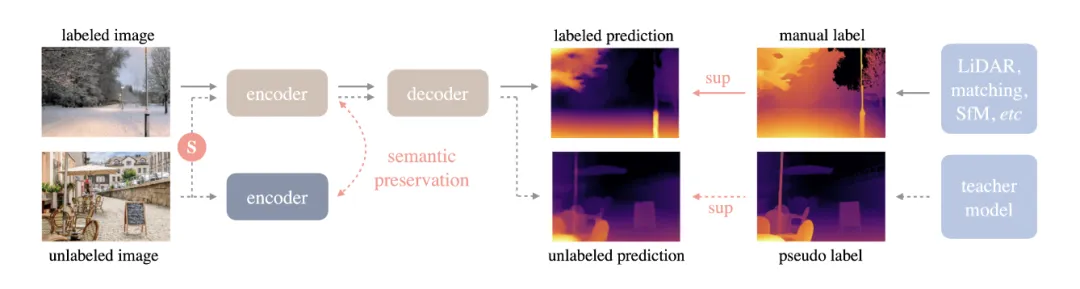
Note: Depth Anything Pipeline demonstration
Ultimately, Depth Anything not only achieved results comparable to previous outcomes but also surpassed the reference model in some metrics. In the zero-shot relative depth estimation performance shown in the figure below, Depth Anything performed well against MiDaS v3.1 on mainstream datasets such as KITTI. In this context, a lower AbsRel value indicates better performance, while a higher δ1 value indicates better performance.
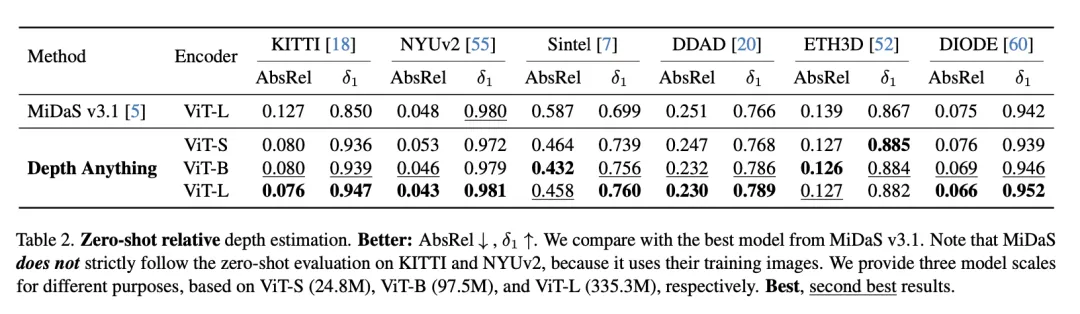
Additionally, the model demonstrated strong generalization capabilities in zero-shot evaluations on six public datasets and randomly taken photos.
3. Optimization Details and Model Scaling-Up
After completing the training of version V1, the team further optimized the model to enhance its robustness and compared its performance with other types of models.
Specifically, Marigold, which is based on stable diffusion, is a generative monocular depth estimation model. It effectively addresses issues related to details, as well as the monocular depth estimation of transparent objects and reflective surfaces, but it has some shortcomings in terms of complexity, efficiency, and generality. The features of Depth Anything V1 complement these aspects.

To address the above issues, the team made a series of explorations through various methods. These included adjustments to the pre-trained models, modifications to the loss function, and the implementation of data augmentation techniques, among others.
Throughout this journey, they uncovered three pivotal insights:
**Firstly, precise synthetic data could enhance model performance in terms of detail processing. **
Upon comparing their results with other models, such as Marigold, the team realized that the stable diffusion model wasn't the only solution for resolving details-related issues.They found that the discriminative monocular depth estimation model could also excel in handling details, provided it was trained with precise synthetic image data rather than labeled real image data.
The team believed there were two main drawbacks of relying solely on real labeled data. The first issue was the inevitable inaccuracies in the labeled information, which could stem from sensor limitations or algorithmic impacts. Secondly, real datasets may overlook certain depth details, like the textures of trees or the structure of chair legs, leading to suboptimal model performance.

Secondly, many previous studies had shied away from using synthetic data due to its inherent huge restrictions.
For instance, models like DINOv2-G, when trained exclusively on synthetic data, exhibited significant inaccuracies. This discrepancy arises from the inherent differences between synthetic and real images, such as the unnaturally "clean" colors and "ordered" composition of synthetic images, as opposed to the randomness found in real-world imagery. Moreover, the limited scenarios depicted in synthetic images could hinder the model's ability to generalize.
However, the team's comparative analysis of models like BEiT, SAM, and DINOv2 revealed that DINOv2-G was the only model to achieve satisfactory generalization capabilities, while the others faced significant challenges in this area.

Thirdly, the team devised a strategy to leverage synthetic image data effectively while mitigating its drawbacks. This involved training a larger "teacher" model using synthetic data, which then served as a guide for a smaller "student" model through the use of large-scale pseudo-labeled real images.
Leveraging the insights gained, the team developed a training pipeline for the Depth Anything V2 model. This process begins with training a "teacher" model using the DINOv2-G architecture and high-quality synthetic images. Subsequently, they generate precise pseudo-labeled depth information from a vast collection of unlabeled real images. The final step involves training a "student" model with these pseudo-labeled real images, thereby enhancing the robustness in its generalization capabilities.
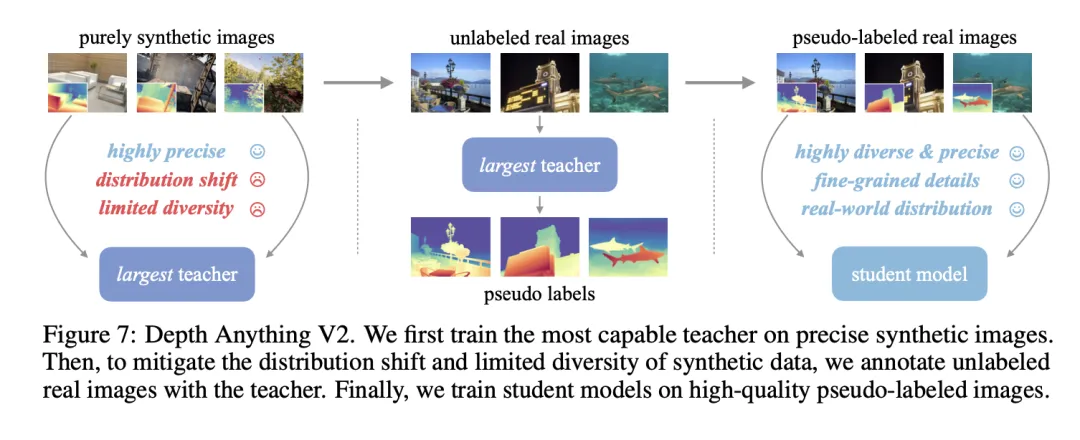
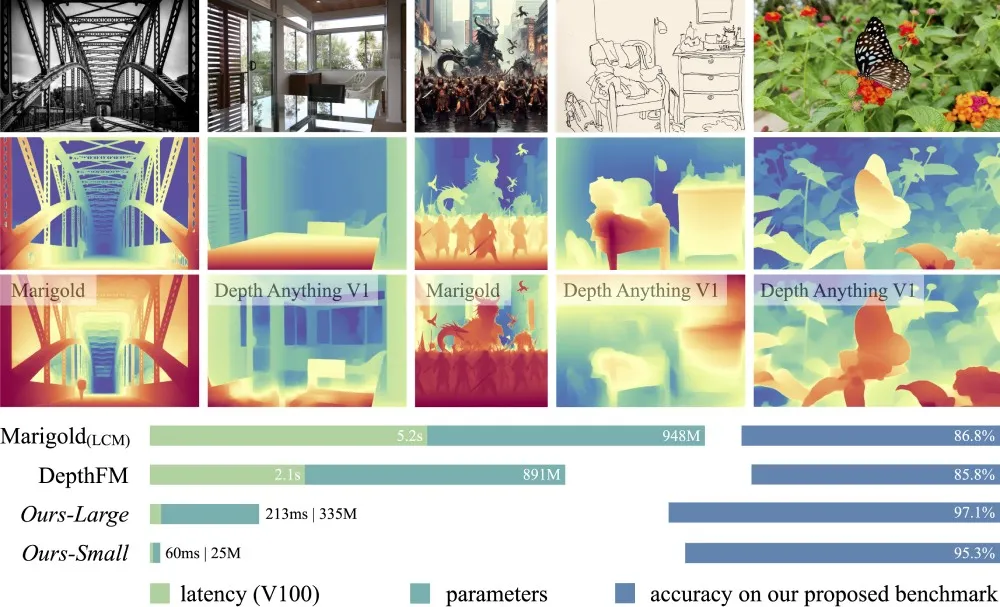
To accurately assess the model's effectiveness, the team introduced the DA-2K evaluation benchmark. This benchmark focuses on precise depth relationships across a diverse array of scenarios, featuring a vast collection of high-resolution images spanning eight distinct scenarios. When evaluated against this benchmark, the Depth Anything V2 ViT-G model outperforms its predecessors, including Marigold and Depth Anything V1, by a significant margin.

In their quest to further refine the model, the team explored the potential benefits of increasing the teacher model's capacity. This exploration aimed to understand the impact of model size scaling on performance outcomes.
Their findings revealed that larger models demonstrated greater generalization capabilities. Moreover, the extent of generalization improvement varied significantly among different types of pre-trained encoders. For example, mainstream encoders like BEiT and SAM were outperformed by DinoV2 in this regard.
This research and development phase spanned several months. Ultimately, the Depth Anything model achieved remarkable advancements in robustness and detail richness. The model now operates over 10 times faster than the most advanced models based on stable diffusion technology, leading to higher efficiency.
Comparison showed that pre-trained diffusion models performed better in terms of details processing. The team initially considered adopting more complex models. However, after thorough research, they recognized the importance of balancing complexity with practical considerations such as deployment costs and real-world applicability. As a result, they concluded that a Feed-forward architecture is still the most viable option for deployment.
Looking back on the entire process, one participant remarked, 'There aren't many so-called moments of inspiration in research work. Instead, it’s more about methodically and diligently testing each approach one by one to achieve results.'
Finally, regarding the impact of Scaling Laws on the development of computer vision (CV), the team believes that Scaling Laws will be increasingly instrumental in overcoming long-standing fundamental challenges that have been difficult to break through, fully leveraging the value of data and model scaling. As for where the boundaries of continuous scaling lie, the team is still exploring that further.
4. The First Author was An Intern.
Currently, Depth Anything has released two versions of its model series, and the related paper, Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data, has been accepted for CVPR 2024.

First author of this series of achievements was an intern. The related research work was also conducted during the internship at the company.
At the project initiation stage, the mentor proposed the scaling route and provided the initial project concept. The intern further suggested the idea of scaling up using large-scale unlabeled data. In less than a year, the intern completed most of the work, including conducting the relevant experiments, advancing the project, and writing the paper.
During this time, the company’s scientists and the team mentor provided suggestions and guidance, continuously tracked the progress, and coordinated with collaborating departments to secure computing resources.
'In our research work, we focus more on identifying good questions and guiding the project’s direction at key milestones, while providing interns with appropriate ideas for solutions. In terms of execution, we place full trust in them,' shared the project mentor.
'This approach not only respects the intern's ideas but also avoids the risk of having no output due to being completely hands-off,' he added.
Through everyone's combined efforts, the intern not only achieved significant results but also greatly improved skills and the intern's personal research judgment and ability to independently identify and solve problems were highly recognized by the team.
Regarding personal growth and team support, the intern felt that the company and the team provided a research environment with a high degree of freedom, and they were supportive of reasonable ideas.
'Moreover, compared to the number of papers, the team encourages spending more time on researching more difficult, fundamental problems that can offer new perspectives and value to the industry,' he added.
In fact, Depth Anything is just one of many achievements; ByteDance has recently been exploring a wide range of research in the fields of visual generation and large models.
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
An Image is Worth 32 Tokens for Reconstruction and Generation
Magic-Boost: Boost 3D Generation with Multi-View Conditioned Diffusion
LLaVA-next: Open Large Multimodal Models
PLLaVA: Parameter-free llava extension from images to videos for video dense captioning
Flash v-stream: Memory-Based Real-Time Understanding for Long Video Streams
...
Currently, the ByteDance Large Language Model team in the field of computer vision is continuously seeking talented individuals. If you also aspire to engage in cutting-edge exploration of computer vision technology within a free research environment, we welcome you to submit your resume.