2025.01.22
Doubao-1.5-pro
模型使用 MoE 架构,并通过训练-推理一体化设计,探索模型性能和推理性能之间的极致平衡。Doubao-1.5-pro 仅用较小激活参数,即可超过一流超大稠密预训练模型的性能,并在多个评测基准上取得优异成绩。

性能评估
本次更新,Doubao-1.5-pro 基础模型能力全面提升,在多个公开评测基准上表现优异。

Doubao-1.5-pro 在多个基准上的测评结果
模型性能与推理性能的极致平衡
模型从预训练阶段就坚持训练-推理一体设计,以在最强的模型性能和最优的推理成本之间取得平衡。
高效 MoE 模型结构
从训练和推理效率的角度出发,Doubao-1.5-pro 使用稀疏 MoE 架构。在预训练阶段,仅用较小参数激活的 MoE 模型,性能即可超过 Llama3.1-405B 等超大稠密预训练模型。团队通过对稀疏度 Scaling Law 的研究,确定了性能和效率比较平衡的稀疏比例,并根据 MoE Scaling Law 确定了小参数量激活的模型即可达到世界一流模型的性能。

训练 loss 图
MoE 模型的性能通常可以用表现相同的稠密模型的总参数量和 MoE 模型的激活参数量的比值来确定,比如 IBM 的 Granite 系列模型中,800M 激活的 MoE 模型性能可以接近 2B 总参数的稠密模型,性能比值大约在 2.5 倍(2000M/800M)。此前,业界在这一性能杠杆上的普遍水平为不到 3 倍。团队通过模型结构和训练算法优化,在完全相同的部分训练数据(9T tokens)对比验证下,用激活参数仅为稠密模型参数量 1/7 的 MoE 模型,超过了稠密模型的性能,将性能杠杆提升至 7 倍。
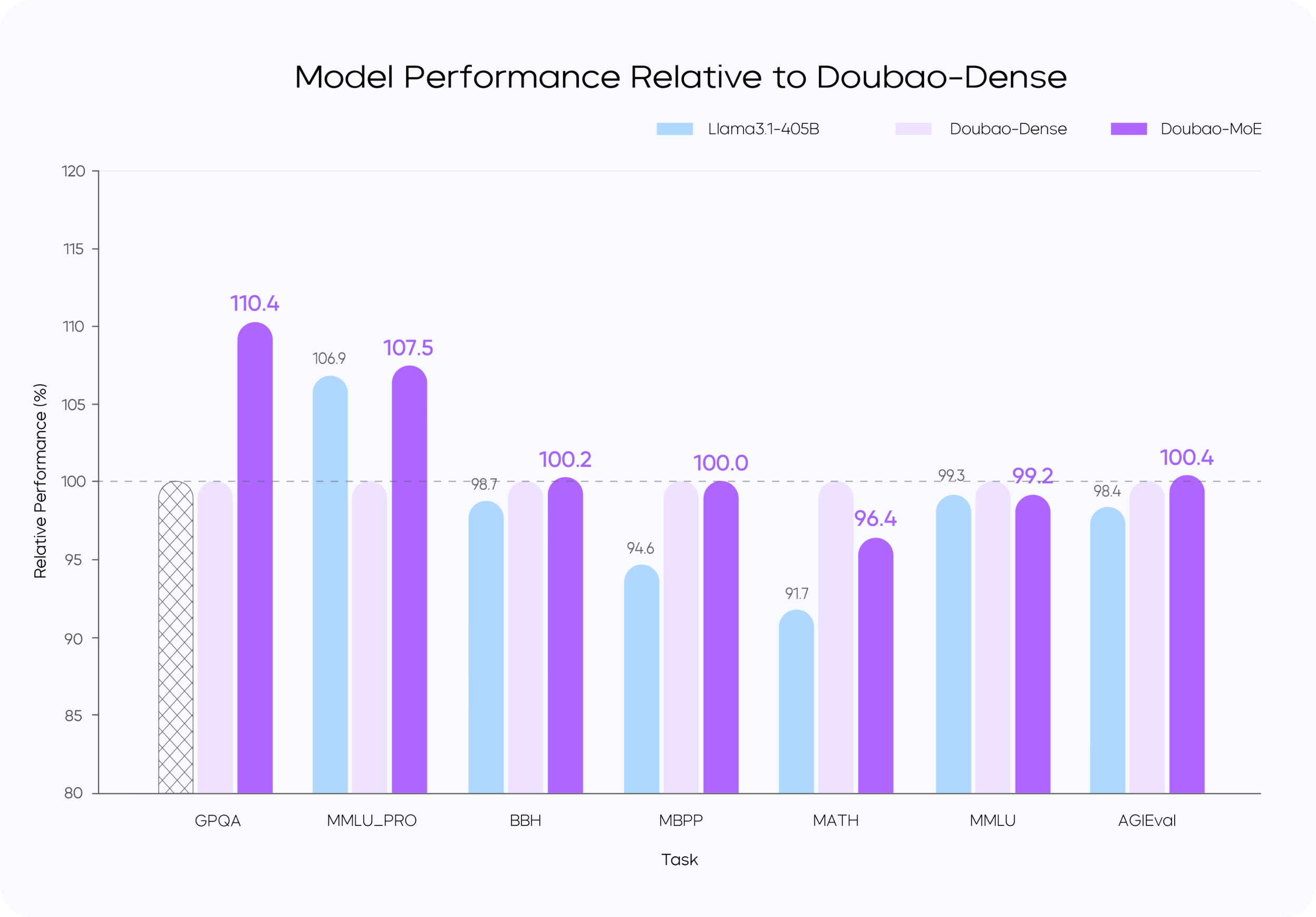
Performance 对比图
在预训练模型基础上,算法团队还设计了一系列模型参数动态调整算法。可以基于具体应用对模型性能的需求,从模型深度、宽度、MoE 专家数、激活专家数、隐藏 token 推理等不同维度,对模型参数进行扩增和缩小,达到模型能力和推理成本的最优平衡。同时,较小的预训练模型提高了团队迭代开发的效率,可以并发支持多个产品线。
高性能推理系统
Doubao-1.5-pro 是一个高度稀疏的 MoE 模型,在 Prefill/Decode 与 Attention/FFN 构成的四个计算象限中,表现出显著不同的计算与访存特征。针对四个不同象限,我们采用异构硬件结合不同的低精度优化策略,在确保低延迟的同时大幅提升吞吐量,在降低总成本的同时兼顾 TTFT 和 TPOT 的最优化目标。

不同阶段的计算和访存特征
Prefill 阶段,通信和访存瓶颈不明显,但容易达到计算瓶颈。考虑到 LLM 单向注意力的特点,我们在多种计算访存比高的设备上做 Chunk-PP Prefill Serving,使线上系统 Tensor Core 的利用率接近 60%。
Decode 阶段,计算瓶颈不明显,但对通信和访存能力要求比较高。我们采用计算访存比较低的设备 Serving 来换取更高的 ROI,同时,采用极低成本的 Sampling 采样以及 Speculative Decoding 策略,降低 TPOT 指标。
整体来看,在 PD 分离的 Serving 系统上,我们实现了以下优化:
此外,凭借自研服务器集群方案,灵活支持低成本芯片,硬件成本比行业方案大幅度降低。我们还通过定制化网卡和自主研发的网络协议,显著优化了小包通信的效率。在算子层面,我们实现了计算与通信的高效重叠(Overlap),从而保证了多机分布式推理的稳定性和高效性。
扎实数据标注,坚持不走捷径
在 PostTraining 阶段,我们精心构建了一套高度自主的数据生产体系,该体系通过高效标注团队与模型自提升技术的深度融合,持续且精准地优化数据质量,严格遵循内部标准,坚持不走捷径,不使用任何其他模型的数据,确保数据来源的独立性和可靠性。
SFT 阶段,开发了一套算法驱动的训练数据优化系统,涵盖训练数据多样性优化以及精确人题匹配功能,并结合模型自演进(Self-evolve)技术,提升数据标注的多样性和难度,形成了模型性能提升的良性循环。
Reward Model 部分,我们建立了包含 prompt 分布优化、response 筛选、多轮迭代和 active learning 的完整数据生产 pipeline。通过融合同等规模的合成与挖掘数据,有效规避了数据冲突和 pattern hacking 问题;设计了多阶段 Reward Model 训练框架,实现了模型在各类数据分布上的稳定判断能力;基于梯度筛选和迭代过滤技术,用 25% 的数据达到近似全量的训练效果,提高迭代效率;实现了 Verifier 和 Reward Model 的深度融合,构建了统一的 Reward 框架,实现了模型在数学、编程、知识、对话等多维度能力的均衡提升;提出了不同于传统判别式 RM 的生成式 RM 建模方法,在 OOD 泛化性能和 reward hacking 防御上取得显著提升。
RL 阶段,基于 veRL 打造了高并行化的多角色训练推理一体框架,兼容不同类型的数据和奖励方式;通过自适应数据分布调节机制,解决了多任务训练中的冲突问题;攻克了价值函数训练难点,实现 token-wise 稳定建模,收敛速度提升 4 倍,在高难度任务上的性能提升超过 10 个绝对点;通过对比学习方法,有效提升了 LLM 的表现并显著缓解了 reward hacking 问题。在数据、算法、模型层面全面实现了 Scaling,完成算力到智力的有效转换。
此外,依托字节在推荐、搜索和广告领域的 AB Test 经验,研发了基于用户反馈的高效 PostTraining 全流程,基于豆包的大规模用户反馈,我们构建了从问题发现、数据挖掘、人机结合标注到快速迭代的闭环优化系统,通过用户数据飞轮持续提升模型的实际使用体验。
多模态能力全面提升
Doubao-1.5-pro 在同一模型中融合并提升了视觉、语音等多模态能力,可为用户带来更自然、更丰富的交互体验。
视觉多模态:性能进一步提升,从容应对更复杂场景
视觉方面,相比于上一版本,Doubao-1.5-pro 在多模态数据合成、动态分辨率、多模态对齐、混合训练上进行了全面的技术提升,进一步增强了模型在视觉推理、文字文档识别、细粒度信息理解、指令遵循等方面的能力,并让模型的回复模式变得更加精简、友好。在同一模型中融入强大的视觉理解能力,使模型可以同时理解虚拟和现实世界的各类视觉信号,更好地辅助人类决策。
Doubao-1.5-pro 的视觉推理能力表现优越,在各类评测基准上均取得了优异表现:

Doubao-1.5-pro 在多个视觉基准上的测评结果
高效的原生动态分辨率训练
分辨率问题一直是影响视觉理解能力的关键因素,尤其在虚拟世界中,信息理解受分辨率的影响更为明显。为应对各类场景下的复杂图像输入,Doubao-1.5-pro 采用了原生动态分辨率架构设计,支持任意分辨率的图像输入。无论是高清大图还是低分辨率的小图,亦或是极端长宽比例的图像,模型都能实现精准的特征提取和高效的计算性能。借助于原生分辨率的设计,新模型在文档识别、细粒度信息识别等任务上实现了极大的效果提升。
我们自研的支持动态分辨率的 Doubao ViT 在多种视觉分类任务中表现优异,仅凭 2.4B 规模便在综合评分上取得 SOTA 表现,效果超越 7 倍于自身规模的模型。

Doubao ViT 在多种视觉分类任务中的表现
在动态分辨率训练过程中,为了缓解 VLM 中视觉 Encoder 部分负载不均衡问题,我们在训练 Infra 上,精心设计了专门针对动态分辨率的前向和反向的负载优化算法,以通信传输消除不均衡计算带来的同步等待,整体训练吞吐提升了 60% 以上。
多样化的数据合成管线
相比于主要来自互联网的纯文本语料,VLM 所需要的图文数据获取更为复杂,需要更为精细的数据管线来对互联网数据进行清洗和加工,甚至需要从零开始构造合成数据。在 Doubao-1.5-pro 中,除了利用来自搜索引擎的海量图文对和图文交织数据进行训练外,还采用了基于渲染引擎、传统计算机视觉模型、模型自迭代等多种数据合成方式,以获取高质量的多模态预训练数据。
文本与视觉理解混合训练
为同时提升 Doubao-1.5-pro 的视觉能力和语言能力,我们在 VLM 的多个训练阶段,都混入了一定比例的纯文本数据,并通过动态调整学习率的方法平衡视觉与语言能力,确保模型的语言能力无损。在 PostTraining 阶段,多模态部分同样拥有完全自主可控的数据管线,我们利用人工标注与自身模型数据合成的方式,构建多模态偏好数据集,以和文本数据一同训练。同时,我们将绝大部分的后训练算力和数据工作都集中在 RL 阶段,根据不同类型的 Prompt 建立了不同的偏好标准,并构造了去除长度偏好影响的 RM 训练集,以平衡好回复准确性、长度和信息量的关系,使多模态模型的回复在尽可能准确、实用的前提下,保持简洁。
效果演示


语音多模态:理解生成一体化,情商智商在线
在语音多模态上,我们提出了新的 Speech2Speech 的端到端框架,不仅通过原生方法将语音和文本模态进行深度融合,同时还实现了语音对话中真正意义上的语音理解生成端到端,相比传统的 ASR+LLM+TTS 的级联方式,在对话效果上有质的飞跃。Doubao-1.5-pro 不仅拥有高理解力(高智商),还具备语音高表现力与高控制力,以及模型整体在回复内容和语音上的高情绪承接能力。
在框架设计上,我们将语音和文本 Token 进行融合,为语音多模态数据的 Scaling 提供了必要条件。在 Pretrain 阶段,我们开发了多样化的数据生产和使用方式,同时在训练上探索了多种有效方案,通过 Scaling 最大化地将语音和文本能力进行深度融合。在 PostTraining 阶段, 通过融合高表现力与智商数据的均衡, 数据筛选以及多模态 RL 阶段的专项能力提升让模型在智商,语音表现力等多方面达到最优。

探索智能的边界
Doubao 深度思考模式
推理能力是智能的重要组成部分,团队致力于使用大规模 RL 的方法不断提升模型的推理能力,拓宽当前模型的智能边界。在完全不使用其他模型数据的条件下,通过 RL 算法的突破和工程优化,充分发挥 test time scaling 的算力优势,完成了 RL scaling,研发了 Doubao 深度思考模式。

Doubao-1.5-pro-AS1-Preview 在 AIME 上的评测结果
目前,阶段性进展 Doubao-1.5-pro-AS1-Preview 在 AIME 上已经超过 O1-preview,O1 等推理模型。并且,随着 RL 的持续,模型能力还在不断提升中。在这一过程中,我们也看到了推理能力在不同领域的泛化,智能的边界正在被慢慢拓宽。

推理能力的初步泛化
向智能的无限可能出发
豆包大模型团队一直以探索智能的无尽边界、解锁通用智能的无限可能为目标。同时,我们认为探索智能的边界与服务用户和行业是一体的关系,两者可以彼此增益、双向驱动。接下来,团队会继续加强对大模型基础研究的投入,挑战更长周期的、具有颠覆性的通用智能研究课题。